Redis面试常见问题
缓存雪崩
一般热点数据都会去做缓存,一般缓存都是定时任务去刷新,定时刷新就有一个问题:
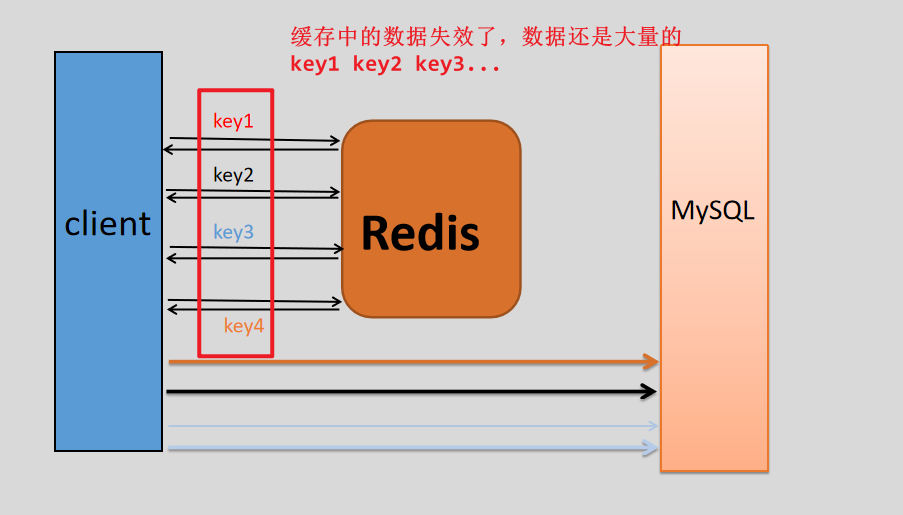
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样缓存在失效的时候,原本访问缓存就能得到的数据,现在失效了,只能到数据库中取访问,这样会给后端系统(比如DB)带来很大压力。
总结:缓存中大量的数据在同一时间失效,此时相当于没有缓存,所有对数据的请求直接走到数据库,会带来很大压力。
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!大多数系统设计者考虑用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。加锁排队只是为了减轻数据库的压力,并没有提高系统吞吐量。这是个治标不治本的方法!因此很少使用。
还有一个简单方案就是将缓存失效时间分散开,比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
还有一种方法是不设置缓存的过期时间,有更新操作时就把热点的缓存全部更新,比如首页上的商品,当首页更新时,就把对应的数据替换掉。
缓存击穿
缓存击穿跟缓存雪崩类似,但是又不一样。
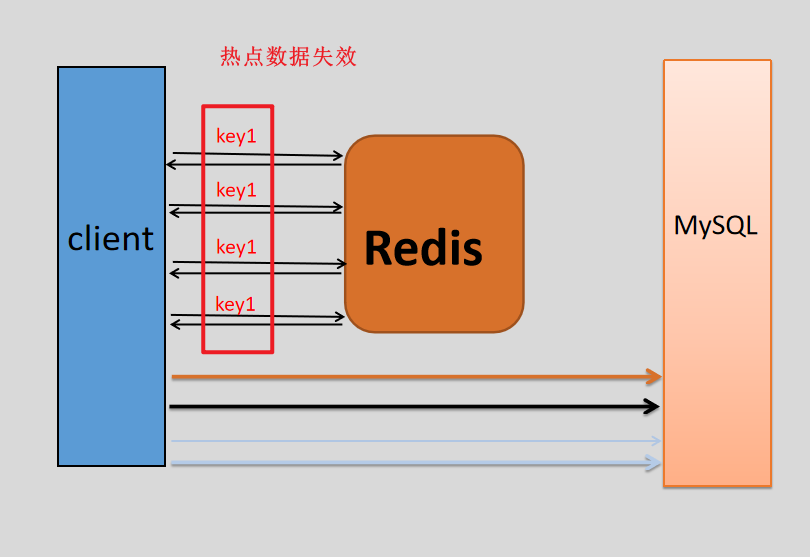
缓存雪崩是大量的缓存失效,对这些数据的访问量全都转移到数据库上了。 而缓存击穿是一个key可能会在某些时间点被超高并发地访问,属于“热点”数据,在不停的扛着大并发的访问量,当这个热点数据在缓存中过期而失效的时候,大量的并发访问就会穿破缓存,转移到数据库上面,就像在缓存上开了一个洞,所以叫击穿。
总结:当热点数据key从缓存内失效时,大量访问同时请求这个数据,就会将查询下沉到数据库层,此时数据库层的负载压力会骤增,我们称这种现象为"缓存击穿"。
解决问题:1、可以让数据不失效或者延长过期时间 2、让客户端互斥访问数据库(对数据库加锁)
解决方案
- 延长热点key的过期时间或者设置永不过期,如排行榜,首页等;
- 利用互斥锁保证同一时刻只有一个客户端可以查询底层数据库的这个数据,一旦查到数据就缓存至Redis内,避免其他大量请求同时穿过Redis访问底层数据库;
缓存穿透
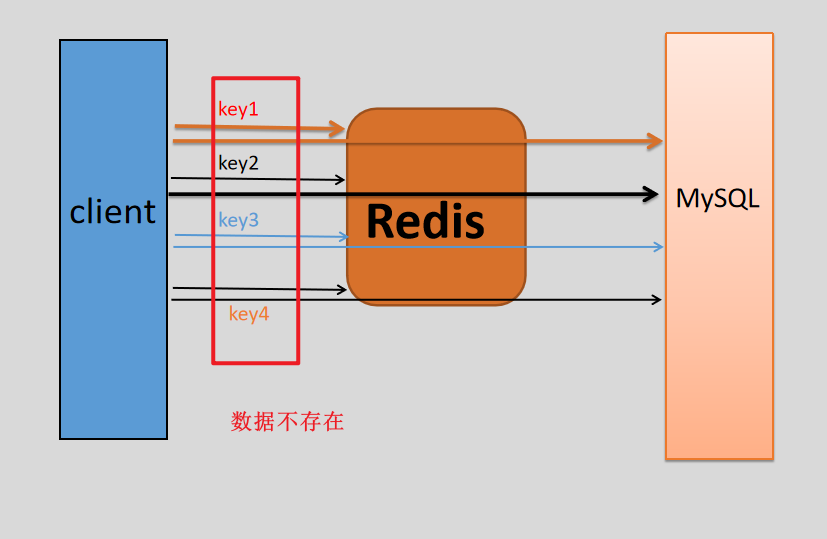
假如用户要访问的数据并不存在(缓存和数据库中都没有),这样每次先到缓存中查找,再到数据库中查找,由于数据并不存在,也就无法将该数据写入到缓存中,那么每次对该数据的查询都会去查询一次数据库。如果用户频繁请求这样的数据,比如用一个不存在的用户id获取用户信息,不论缓存还是数据库都没有,会导致数据库压力过大,若黑客利用此漏洞进行攻击可能压垮数据库。
总结:要查询的数据不存在,缓存无法命中所以需要查询完数据库,但是数据是不存在的,此时数据库肯定会返回空,也就不会记录到缓存中,这样每次对该数据的查询都会穿过缓存去查询一次数据库。
缓存击穿和缓存穿透从名词上可能很难区分开来,它们的区别是:穿透表示底层数据库没有数据且缓存内也没有数据,击穿表示底层数据库有数据而缓存内没有数据。
解决方案
- 查询时做一些校验和过滤(权限校验,参数校验等等),判断这是一次正常的查询,还是异常的查询或者是攻击,如果是不合法的参数或者查询,直接返回
- 缓存空对象,如果数据库中不存在这个数据,我们也在缓存中保存这个key,只是把val值记录为“不存在”,“空”这样的数据,下次再访问这个key时,就不会到数据库中做无用的查找了。
- 我们可以预先将数据库里面所有的key全部存到一个大的map里面,然后在过滤器中过滤掉那些不存在的key. 但是需要考虑数据库的key是会更新的,此时需要考虑数据库 --> map的更新频率问题。类似于位图。