线程池
为什么要有线程池?假设没有使用线程池时,一个请求用一个子线程来处理。每来一个请求,都得创建子线程,子线程执行请求,关闭子线程。当请求量(并发)比较大的时候,频繁地创建和关闭子线程,也是有开销的。因此提出线程池,提前开辟好N个子线程,当有任务过来的时候,先放到任务队列中,之后N个子线程从任务队列中获取任务,并执行,这样能大大提高程序的执行效率。其实当任务数大于线程池中子线程的数目的时候,就需要将任务放到缓冲区(队列)里面,所以本质上还是一个生产者消费者模型。
查看线程的状态的命令
ps -elLf | grep xxx原理图
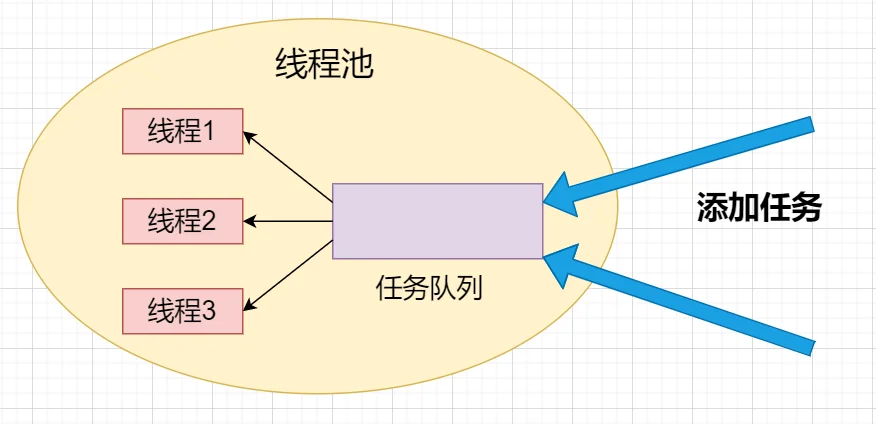
面向对象线程池
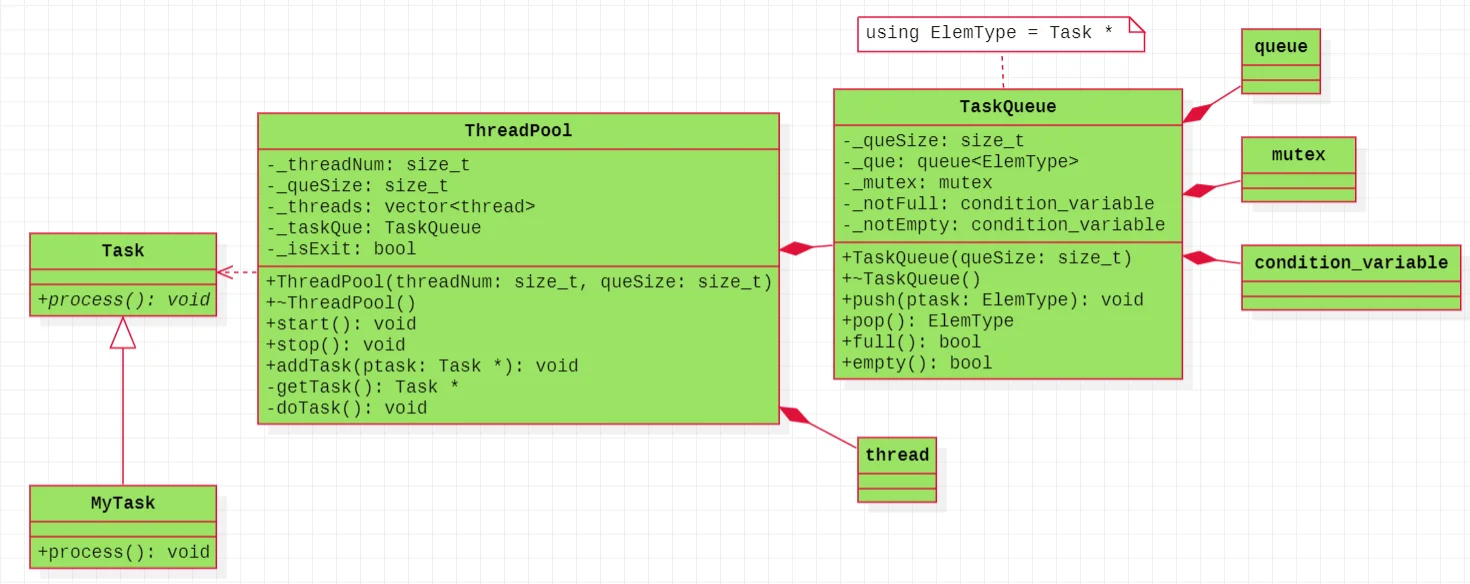
使用面向对象的思想封装线程池,在线程池类中需要有工作线程,用来处理任务,也需要有存放任务的数据结构,我们称之为任务队列,这样线程池中的工作线程只要空闲之后就可以从任务队列中获取数据。那么需要有一个变量记录线程的数目,我们设置为size_t _threadNum以及存放这么多线程的数据结构vector,用来存放线程,vector<thread> _threads;对于任务队列而言,多个线程可能并发访问任务队列,获取其中的任务,所以任务队列就是一个共享资源,所以需要给其上锁,避免数据的污染,所以在此处就可以直接使用之前封装的TaskQueue对象,并且为了给其进行初始化,还设置了一个任务队列大小的数据成员size_t _queSize以及任务队列TaskQueue _taskQue,最后为了标识线程池是否退出设置了标志位bool _isExit
对于线程池中需要设置的成员函数包括:线程池的启动start与停止stop,用来将工作线程启动起来等待执行任务,以及线程池结束前回收工作线程;然后就是向任务队列中添加任务的addTask函数以及获取任务的getTask函数;再就是线程池交给线程做的任务doTask函数,其中就是工作线程执行的操作。最后就是任务是什么,以什么形式存在,这里我们将其设置为一个类,称之为Task。任务怎么执行我们封装了一个纯虚函数process,这样任何具体的任务只需要继承这个Task并实现其中的process函数就可以了。这就是面向对象的线程池的设计思想。
核心代码
ThreadPool::ThreadPool(size_t threadNum, size_t queSize) : _threadNum(threadNum), _queSize(queSize), _taskQue(_queSize), _isExit(false) {}
ThreadPool::~ThreadPool() {}
void ThreadPool::start() {
// 创建出线程,存放在vector,同时还要将线程运行起来
for (size_t idx = 0; idx < _threadNum; ++idx) {
/* thread th(&ThreadPool::doTask, this); */
/* _threads.push_back(std::move(th)); */
_threads.push_back(thread(&ThreadPool::doTask, this));
}
}
void ThreadPool::stop() {
_isExit = true;
for (auto &th : _threads) {
th.join();
}
}
void ThreadPool::addTask(Task *ptask) {
if (ptask) {
_taskQue.push(ptask);
}
}
Task *ThreadPool::getTask() { return _taskQue.pop(); }
void ThreadPool::doTask() {
// 只要线程池不退出,只要有任务就一直执行任务
while (!_isExit) {
Task *ptask = getTask(); // 获取任务
if (ptask) {
ptask->process(); // 肯定会有多态
} else {
cout << "nullptr == ptask" << endl;
}
}
}测试代码
class MyTask : public Task {
public:
void process() override {
::srand(::clock()); // 种随机种子
int number = ::rand() % 100; // 产生随机数
cout << "MyTask number = " << number << endl;
}
};
void test() {
unique_ptr<Task> ptask(new MyTask());
ThreadPool pool(4, 10);
pool.start();
// 线程池启动之后,需要添加任务
int cnt = 20;
while (cnt--) {
pool.addTask(ptask.get());
cout << "cnt = " << cnt << endl;
}
pool.stop();
}
int main(int argc, char *argv[]) {
test();
return 0;
}思考
- 上述测试代码会不会有什么问题?
- 线程池中的任务可以执行完毕吗?
- 线程池可以完美退出吗?如何解决?
基于对象线程池
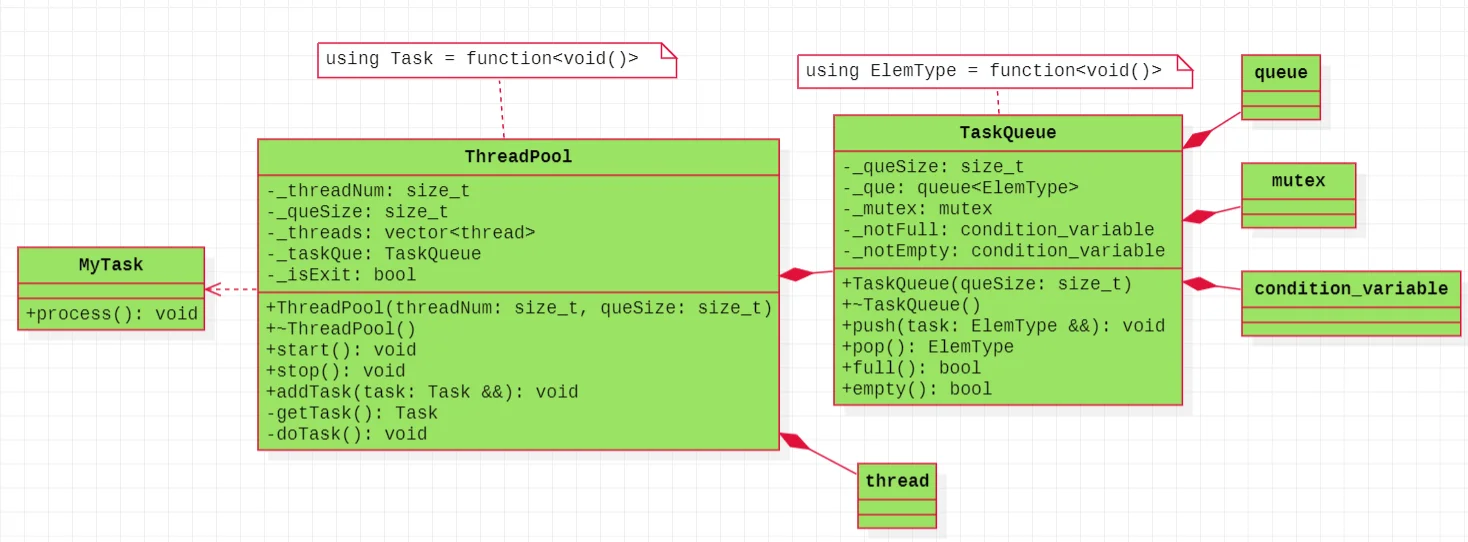
所有的数据成员的设计与上述面向对象的完全一致,但是基于对象线程池的区别是,任务的形式有所区别。对于基于对象而言,是不存在继承的,所以我们将任务的形式发生了转变。利用之前使用的function可以接受函数类型,将任务中的函数通过bind进行绑定之后变成被function接受的函数类型,这就是基于对象的思想,所以所有的Task可以修改为using Task = function<void()>,所以添加任务就是添加函数类型、处理任务就是处理函数类型。