简单使用workflow框架
对于一个我们以前不了解的第三方框架,初步了解、使用的方式可以通过官方网站、官方文档、官方示例、头文件等方式进行了解和熟悉。workflow框架没有官方网站,我们可以通过官方文档、示例程序和查看头文件的方式进行熟悉。
- 官方文档 https://github.com/sogou/workflow/blob/master/README_cn.md
- 示例程序 位于源码目录中的tutorial目录中
避免进程提前终止
由于任务的启动是异步的,所以任务的执行和主线的执行是并行的,如果不加任何的控制,那么当主线程执行完所有操作以后直接退出,并且导致整个进程的终止。WFFacilities::WaitGroup 可以根据情况阻塞线程或者恢复运行,可以用来主线的运行情况。
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
// 1.告诉WaitGroup任务数量
static WFFacilities::WaitGroup wait_group(1);
void signalhandle(int signo) {
// 告诉WaitGroup完成了一个任务
wait_group.done();
}
int main() {
// 3.设退出方法
signal(SIGINT, signalhandle);
// 使用信号回调函数来完成任务
// 当任务数量为 0 时,程序自动退出
// 2.阻塞程序,防止主程序退出
wait_group.wait();
std::clog << "finished\n";
return 0;
}作为HTTP客户端
用户可以通过以下的方式进行控制任务的属性:
- 创建任务的时候,根据任务类型给工厂函数传递一些属性参数,比如HTTP任务的URL等参数;
- 在创建任务之后且任务启动之前,可以配置任务的各种参数,比如HTTP任务的目标URI、请求方法等;
- 在创建任务的时候需要配置一个回调函数,这个回调函数会任务的其余所有步骤都执行完成以后调用。
接下来,我们利用workflow来实现一个http客户端。实现一个http客户端的基本流程如下:
- 使用工厂函数,根据任务类型HTTP,创建一个任务对象;
- 设置任务的属性;
- 为任务绑定一个回调函数;
- 启动任务。
在workflow当中,所有任务对象都是使用工厂函数来创建的。在创建任务的时候,还可以设置一些属性,比如要连接的服务端的url、最大重定向次数、连接失败的时候的重试次数和用户的回调函数(没有回调函数则传入nullptr)。
注册任务
调用start方法可以异步启动任务。需要值得特别注意的是,只有客户端才可以调用start方法。通过观察得知,start方法的底层逻辑就是根据本任务对象创建一个序列,其中本任务是序列当中的第一个任务,随后启动该任务。
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(1);
void signalhandle(int signo) {
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建任务
WFHttpTask *http_task = WFTaskFactory::create_http_task(
"https://www.baidu.com", // URL 地址
10, // 最大重定向次数
10, // 最大重试次数
nullptr // 请求发送完成的回调函数,在收到对应相应时调用
);
// 2.将任务交给 workflow 框架
// 虽然函数名为 start,但是什么时间开始执行任务由框架决定
// 这一步只是注册任务
http_task->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}获取任务状态
当任务的基本工作完成之后,就会执行用户设置的回调函数的,在回调函数当中,可以获取本次任务的执行情况。
针对http任务,回调函数在执行过程中可以获取本次任务的执行状态和失败的原因。
下面是使用状态码和错误码的例子。当http基本工作执行正常的时候,此时状态码为
WFT_STATE_SUCCESS,当出现系统错误的时候,此时状态码为WFT_STATE_SYS_ERROR,可以使用strerror获取报错信息。当出现url错误的使用,此时状态码为WFT_STATE_DNS_ERROR,可以使用gai_strerror获取报错信息。
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(1);
void signalhandle(int signo) {
wait_group.done();
}
// 任务的回调
void http_back(WFHttpTask *task) {
// 获取任务状态
int status = task->get_state();
int error = task->get_error(); // 如果任务失败,获取失败原因
// 判断任务的状态
switch (status) {
case WFT_STATE_DNS_ERROR:
std::clog << "DNS_ERROR:" << strerror(error);
break;
case WFT_STATE_TASK_ERROR:
std::clog << "TASK_ERROR:" << strerror(error);
break;
case WFT_STATE_SUCCESS:
std::clog << "TASK_SUCCESS\n";
break;
default:
break;
};
// 将任务数量-1
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建任务
WFHttpTask *http_task = WFTaskFactory::create_http_task(
"https://www.baidu.com", // URL 地址
10, // 最大重定向次数
10, // 最大重试次数
http_back // 请求发送完成的回调函数,在收到对应相应时调用
);
// 2.将任务交给 workflow 框架
// 虽然函数名为 start,但是什么时间开始执行任务由框架决定
// 这一步只是注册任务
http_task->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}在使用回调函数的时候,还可以获取http请求报文和响应报文的内容。
获取请求/响应信息
对于首部字段,workflow提供 protocol::HttpHeaderCursor 类型作为遍历所有首部字段的迭代器。next方法负责找到下一对首部字段键值对,倘若已经解析完成,就会返回false。find会根据首部字段的键,找到对应的值,值得注意的是,find方法会修改迭代器的位置。
对于http报文的报文体,可以使用get_parsed_body方法获取报文的内容,需要值得是它的用法。
#include <iostream>
#include <signal.h>
#include <string>
#include <workflow/HttpUtil.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(1);
void signalhandle(int signo) {
wait_group.done();
}
// 任务的回调
void http_back(WFHttpTask *task) {
// 获取任务状态
int status = task->get_state();
int error = task->get_error(); // 如果任务失败,获取失败原因
// 判断任务的状态
switch (status) {
case WFT_STATE_DNS_ERROR:
std::clog << "DNS_ERROR:" << strerror(error);
break;
case WFT_STATE_TASK_ERROR:
std::clog << "TASK_ERROR:" << strerror(error);
break;
case WFT_STATE_SUCCESS:
std::clog << "TASK_SUCCESS\n";
break;
default:
break;
};
// 获取请求和响应信息
protocol::HttpRequest *req = task->get_req(); // 获取请求头
protocol::HttpResponse *res = task->get_resp(); // 获取响应头
// 方式一:一个一个获取请求/响应头内容
// std::clog << "Request Method:" << req->get_method() << "\n";
// std::clog << "Response Status Code:" << res->get_status_code() << "\n";
// 方式二:遍历请求/响应头
// #include <workflow/HttpUtil.h>
std::string name, value;
protocol::HttpHeaderCursor req_cursor(req);
std::clog << "------start print request header-----\n";
while (req_cursor.next(name, value)) {
std::clog << name << ":" << value << "\n";
}
std::clog << "----print request header finished----\n\n";
protocol::HttpHeaderCursor res_cursor(res);
std::clog << "------start print response header-----\n";
while (res_cursor.next(name, value)) {
std::clog << name << ":" << value << "\n";
}
std::clog << "----print response header finished----\n\n";
const void *body;
size_t size;
res->get_parsed_body(&body, &size);
std::clog << "Response Body size:" << size << "bytes\n";
// std::clog << (char *)body; // 因为我们知道获取到的是 html 内容,所以可以直接转为 char*输出
// 将任务数量-1
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建任务
WFHttpTask *http_task = WFTaskFactory::create_http_task(
"https://www.baidu.com", // URL 地址
10, // 最大重定向次数
10, // 最大重试次数
http_back // 请求发送完成的回调函数,在收到对应相应时调用
);
// 2.将任务交给 workflow 框架
// 虽然函数名为 start,但是什么时间开始执行任务由框架决定
// 这一步只是注册任务
http_task->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}注意
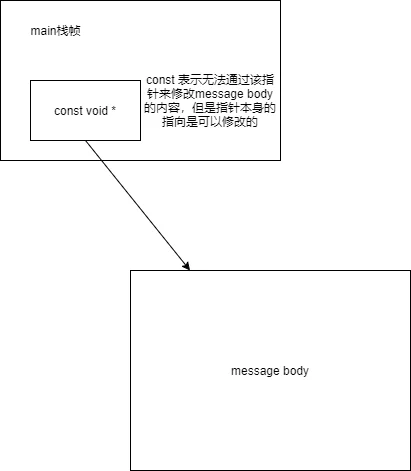
const void *body;
size_t size;
res->get_parsed_body(&body, &size);上面的代码中,要想只获取size大小,也需要传入 body,否则会引起程序崩溃。
执行Redis任务
HTTP任务可以让进程作为HTTP客户端发起请求,然后对请求和响应做后续处理,workflow除了可以当做HTTP客户端使用以外,还可以通过创建redis任务充当redis客户端。和其他任务一样,redis任务是异步的,这样的话在和redis服务端的通信过程当中就不会阻塞原来进程的运行,这种异步的方式能有效地提升访问redis的性能。除此以外,框架底层实现了一个连接池结构——这样用户的redis命令会自动复用连接从而避免不必要的创建连接消耗。
创建redis的方法和http方法类似,都是使用一个工厂函数来创建。
static WFRedisTask *create_redis_task(const std::string& url, int retry_max, redis_callback_t callback);url用来指定redis服务端的登录用户以及ip和端口。Redis URL format: redis://:password@host:port/dbnum
redis://127.0.0.1
redis://:12345@redis.sogou:6379/3在创建任务之后,启动任务之前,需要调用redis任务的get_req方法获取redis任务的请求对象,然后调用请求对象的set_request方法来设置本次redis将要执行的redis指令。set_request方法的参数由两个部分组成,第一个参数是一个字符串,传入redis的指令名字,第二参数是一个元素为string的vector,vector当中的元素是redis指令的其余所有参数。
auto redisTask = WFTaskFactory::create_redis_task("redis://127.0.0.1:6379",2,Callback);
protocol::RedisRequest *req = redisTask->get_req();
req->set_request("SET", { data.key, "value2" });随后启动任务,redis任务的基本工作就是连接到redis服务端执行指令。用户可以设置回调函数来处理基本工作完成之后的行为。首先可以获取的是状态码和错误码。完整示例如下
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(1);
void signalhandle(int signo) {
wait_group.done();
}
void redisCallback(WFRedisTask *task) {
// 获取 redis 类型的 request 和 response
protocol::RedisRequest *req = task->get_req();
protocol::RedisResponse *resp = task->get_resp();
// 获取任务状态和出错时的错误信息
int state = task->get_state();
int error = task->get_error();
// 如果 redis 任务是 get 类型
// 定义一个 redis value类型的变量用来接收返回的 value 值
protocol::RedisValue val;
// 判断任务的执行状态
// 若任务执行成功则获取返回的 redis value 值
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
resp->get_result(val);
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
// 如果任务状态不是成功则提示退出
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
// 获取请求参数
std::string command;
req->get_command(command);
std::clog << "Command:" << command << "\t";
std::vector<std::string> params;
req->get_params(params);
if (params.size()) {
for (auto i : params) {
std::clog << i;
}
std::clog << "\n";
}
// 判断 redis value 的类型
if (val.is_string()) {
std::clog << "Return:" << val.string_value() << "\n";
}
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建 Redis 任务
WFRedisTask *redis_task = WFTaskFactory::create_redis_task(
"redis://127.0.0.1", // redis URL
3, // 最大重试次数
redisCallback // 回调函数
);
// 2.设置请求参数 方式一
protocol::RedisRequest *req = redis_task->get_req();
req->set_request("GET", {"name"}); // 直接使用{}来初始化一个 vector
// 方式二
// redis_task->get_req()->set_request("GET", {"age"});
// 3.注册 Redis 任务
redis_task->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}一般可以将redis分成两种类型,一种是写类型的任务,写类型的redis任务是指执行修改数据库内容指令的任务,例如:GET、SETNX、INCRBY、HSET、HMSET、HSETNX等指令。对于写类型的任务,当任务的基本工作完成了之后,实际上数据库的操作就已经完成了。另一种类型的任务是读类型的任务,读类型的redis是指获取数据库内容的任务,比如GET、HGET、HGETALL等等,读类型任务的基本工作完成之后,还需要用户设置回调函数,将获取的结果按照合适的方式展示出来。
值得注意的是,读取redis中不同数据类型的结果时,类型为protocol::RedisValue结果对象用来展示所使用的方法会有所不同。
执行串行任务
任务默认并行执行
如果我们想按照一定的顺序去执行Redis任务,比如先设置一个键值对然后获取对应键的值判断是否成功,则可能写出如下代码
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(1);
void signalhandle(int signo) {
wait_group.done();
}
void redisCallback_set(WFRedisTask *task) {
std::clog << "redis set task start\n";
int state = task->get_state();
int error = task->get_error();
protocol::RedisValue val;
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
std::clog << "redis set task finished\n";
wait_group.done();
}
void redisCallback_get(WFRedisTask *task) {
std::clog << "redis get task start\n";
protocol::RedisResponse *resp = task->get_resp();
int state = task->get_state();
int error = task->get_error();
protocol::RedisValue val;
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
resp->get_result(val);
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
// 判断 redis value 的类型
if (val.is_string()) {
std::clog << "Return:" << val.string_value() << "\n";
}
std::clog << "redis get task finished\n";
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建第一个任务 设置 name 键值对
WFRedisTask *redis_task_set = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, redisCallback_set);
redis_task_set->get_req()->set_request("SET", {"name", "lisi"});
redis_task_set->start();
// 创建第二个任务 获取 name 的值
WFRedisTask *redis_task_get = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, redisCallback_get);
redis_task_get->get_req()->set_request("GET", {"name"});
redis_task_get->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}运行情况
$ ./main
redis get task start
Return:lisi
redis get task finished
finished
redis set task start
redis set task finished通过运行情况我们可以看出,两个任务的回调函数中输出的内容是乱序的,并不是先执行完了前面的回调才去执行后面的。
设置串行任务
我们将上面串行任务的代码改写,可以在set的回调函数里,回调函数结束时创建get的任务这样两个任务就达到了串行的效果。
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(2);
void signalhandle(int signo) {
wait_group.done();
}
void redisCallback_get(WFRedisTask *task) {
std::clog << "redis get task start\n";
protocol::RedisResponse *resp = task->get_resp();
int state = task->get_state();
int error = task->get_error();
protocol::RedisValue val;
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
resp->get_result(val);
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
// 判断 redis value 的类型
if (val.is_string()) {
std::clog << "Return:" << val.string_value() << "\n";
}
std::clog << "redis get task finished\n";
wait_group.done();
}
void redisCallback_set(WFRedisTask *task) {
std::clog << "redis set task start\n";
int state = task->get_state();
int error = task->get_error();
protocol::RedisValue val;
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
std::clog << "redis set task finished\n";
wait_group.done();
// 2.创建第二个任务 获取 name 的值
WFRedisTask *redis_task_get = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, redisCallback_get);
redis_task_get->get_req()->set_request("GET", {"name"});
redis_task_get->start();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建第一个任务 设置 name 键值对
WFRedisTask *redis_task_set = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, redisCallback_set);
redis_task_set->get_req()->set_request("SET", {"name", "lisi"});
redis_task_set->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}运行情况
$ ./main
redis set task start
redis set task finished
redis get task start
Return:lisi
redis get task finished
finished上面的方式只是我们考虑的,实际上workflow框架中有设计执行串行任务的方式。
推荐的方式
在workflow当中,所有的任务都是异步执行的,如果用户需要两个任务同步执行,比如先执行一次SET key value,再执行一次GET key指令,就需要将两个指令分配两个任务,并且将两个任务串联起来——这里就用到了workflow的序列机制。workflow的序列机制用于将若干个任务串联起来,从而可以同步地执行任务。在某个任务调用方法start而启动时,其本质是创建一个序列,并且将该任务作为序列当中的第一个任务,然后按次序执行序列当中的任务。
执行串行任务的步骤
- 创建若干任务,可以在首个任务启动之前创建,也可以在某个任务的回调函数执行过程中动态创建;
- 对于想要第一个执行的任务,调用其start方法;
- 每当想要任务之间串行执行的时候,就将后面执行任务通过序列的push_back加入到序列中。
设置串行任务的第一种方式
#include <iostream>
#include <signal.h>
#include <workflow/Workflow.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(2);
void signalhandle(int signo) {
wait_group.done();
}
void redisCallback_get(WFRedisTask *task) {
std::clog << "redis get task start\n";
protocol::RedisResponse *resp = task->get_resp();
int state = task->get_state();
int error = task->get_error();
protocol::RedisValue val;
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
resp->get_result(val);
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
// 判断 redis value 的类型
if (val.is_string()) {
std::clog << "Return:" << val.string_value() << "\n";
}
std::clog << "redis get task finished\n";
wait_group.done();
}
void redisCallback_set(WFRedisTask *task) {
// 2.创建第二个任务 获取 name 的值
WFRedisTask *redis_task_get = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, redisCallback_get);
redis_task_get->get_req()->set_request("GET", {"name"});
// redis_task_get->start();
// 使用框架中的函数来将redis_task_get任务添加到redis_task_set任务的后面
// 可以在redisCallback_set回调函数一开始就添加,但是还是会等redisCallback_set执行完才启动redis_task_get任务
// 我们上面的那个示例中注册任务放到这个回调函数开始时,顺序就还会乱
series_of(task)->push_back(redis_task_get);
std::clog << "redis set task start\n";
int state = task->get_state();
int error = task->get_error();
protocol::RedisValue val;
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
std::clog << "redis set task finished\n";
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建第一个任务 设置 name 键值对
WFRedisTask *redis_task_set = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, redisCallback_set);
redis_task_set->get_req()->set_request("SET", {"name", "lisi"});
redis_task_set->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}设置串行任务的第二种方式
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
#include <workflow/Workflow.h>
static WFFacilities::WaitGroup wait_group(2);
void signalhandle(int signo) {
wait_group.done();
}
void redisCallback_get(WFRedisTask *task) {
std::clog << "redis get task start\n";
protocol::RedisResponse *resp = task->get_resp();
int state = task->get_state();
int error = task->get_error();
protocol::RedisValue val;
switch (state) {
case WFT_STATE_SYS_ERROR:
fprintf(stderr, "system error: %s\n", strerror(error));
break;
case WFT_STATE_DNS_ERROR:
fprintf(stderr, "DNS error: %s\n", gai_strerror(error));
break;
case WFT_STATE_SUCCESS:
resp->get_result(val);
if (val.is_error()) {
fprintf(stderr, "Error reply. Need a password?\n");
state = WFT_STATE_TASK_ERROR;
}
break;
}
if (state != WFT_STATE_SUCCESS) {
fprintf(stderr, "Failed. Press Ctrl-C to exit.\n");
return;
}
// 判断 redis value 的类型
if (val.is_string()) {
std::clog << "Return:" << val.string_value() << "\n";
}
std::clog << "redis get task finished\n";
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建第一个任务 设置 name 键值对 为了简化代码就不要回调函数了
WFRedisTask *redis_task_set = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, nullptr);
redis_task_set->get_req()->set_request("SET", {"name", "lisi"});
// 2.创建第二个任务 获取 name 的值
WFRedisTask *redis_task_get = WFTaskFactory::create_redis_task("redis://127.0.0.1", 3, redisCallback_get);
redis_task_get->get_req()->set_request("GET", {"name"});
// 3.创建一个任务序列
// 参数1 第一个任务 参数2 任务序列完成后的回调函数
// 不使用回调函数
// SeriesWork *swork = Workflow::create_series_work(redis_task_set, nullptr);
// 使用回调函数
std::function<void(const SeriesWork *)> finish_work = [](const SeriesWork *) {
std::clog << "finished a series work\n";
wait_group.done();
};
SeriesWork *swork = Workflow::create_series_work(redis_task_set, finish_work);
// 4.将第二个任务添加到任务序列
swork->push_back(redis_task_get); // 添加到第一个任务的后面
// swork->push_front(redis_task_get); // 添加到第一个任务的前面
// 5.注册任务序列
swork->start();
wait_group.wait();
std::clog << "finished\n";
return 0;
}定时任务
在workflow框架当中存在一种定时任务。定时任务会在指定的时间之后完成基本工作,并开始执行回调函数。定时任务的精度是微秒量级。
class WFTaskFactory {
//...
public:
static WFTimerTask *create_timer_task(unsigned int microseconds, timer_callback_t callback);
}通过定时任务和workflow任务机制的配合,可以实现一个定时器,示例代码如下:
#include <ctime>
#include <iostream>
#include <signal.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(1);
char buffer[80];
void sigHandler(int num) { wait_group.done(); }
void timerCallback(WFTimerTask *timerTask) {
// 输出当前时间
time_t now = time(nullptr);
strftime(buffer, 80, "%Y-%m-%d %H:%M:%S", localtime(&now));
std::cerr << "timer callback " << buffer << std::endl;
// 启动下一个定时器任务 无限循环
WFTimerTask *nextTask = WFTaskFactory::create_timer_task(3000000, timerCallback);
series_of(timerTask)->push_back(nextTask);
}
int main() {
signal(SIGINT, sigHandler);
// 创建定时器任务
WFTimerTask *timerTask = WFTaskFactory::create_timer_task(3000000, timerCallback);
timerTask->start();
time_t now = time(nullptr);
strftime(buffer, 80, "%Y-%m-%d %H:%M:%S", localtime(&now));
std::cerr << "timer start " << buffer << std::endl;
wait_group.wait();
return 0;
}并行任务
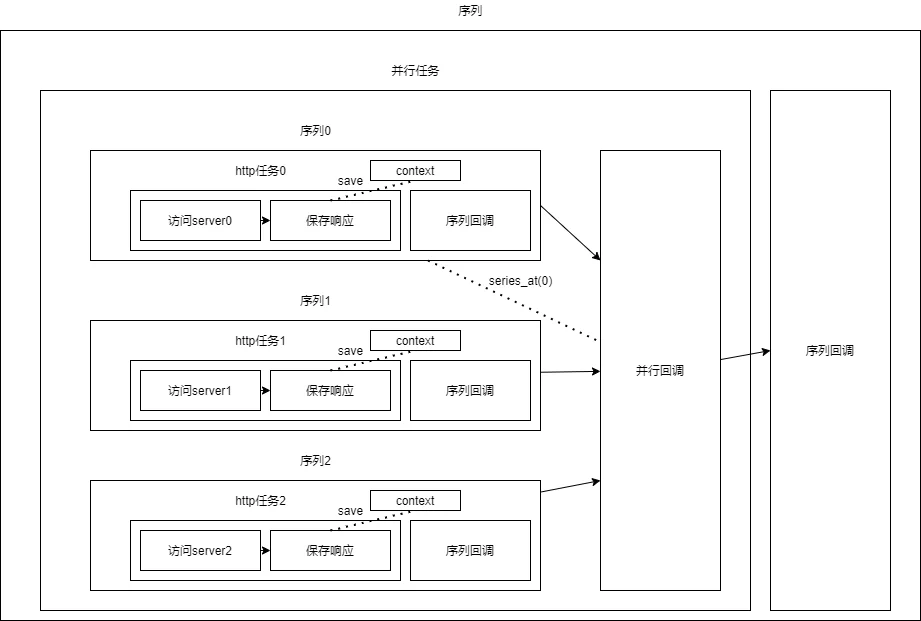
前面的例子介绍了SeriesWork,SeriesWork由任务构成,代表一系列任务的串行执行。所有任务结束, 则该序列结束。与SeriesWork对应的ParallelWork类,描述了一个并行任务,并行任务由序列构成,代 表若干个序列的并行执行。所有序列结束,则这个并行任务的基本工作结束,随后执行相应的回调函 数。需要特别注意的是,ParallelWork本身也是一种任务,所以它可以加入到其他序列中——(而这个 序列又可以用来构建更加复杂的并行任务)这样的话,用户就可以任意地构造复杂的任务流程图,并且 还可以在运行过程中动态地创建任务。
并行任务的创建使用流程
- 创建一个空的并行任务
- 创建很多个小任务,再创建小序列
- 将小序列加入到并行任务
- 设计好要共享的数据,放入小序列的context
- 把所有小序列完成之后再做的事情,放入到并行任务的回调之中
- 并行任务的执行会放到一个大序列里面。
共享数据
workflow中在序列内部的任务之间共享数据可以使用context,可以通过序列的get_context和set_context 来获取和设置 context。
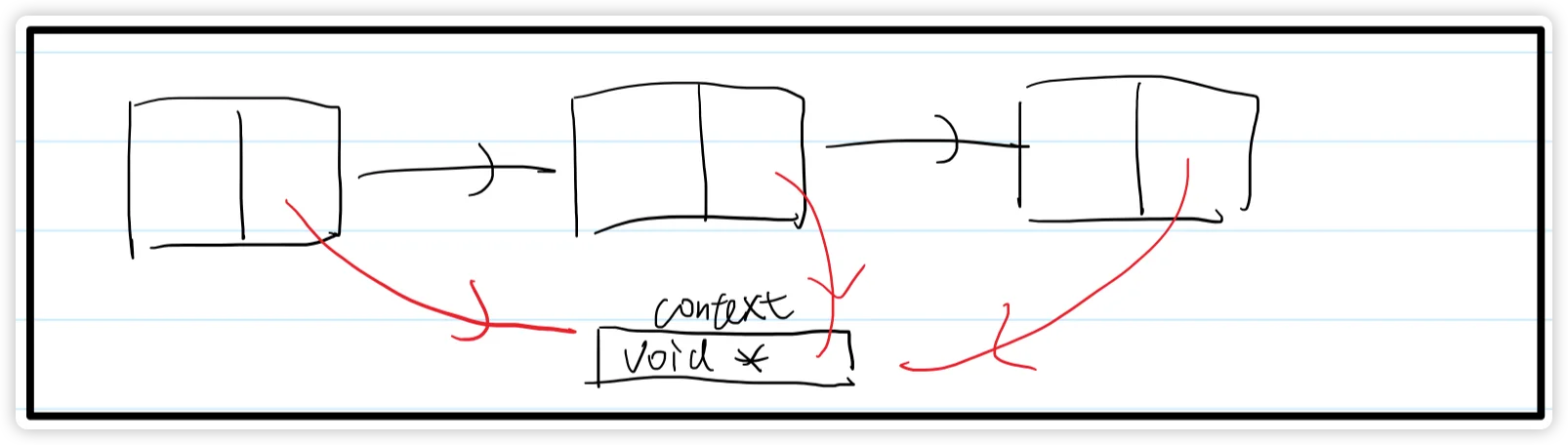
context 的使用步骤是
- 自定义一个类型
- 构造任务和序列
- 给序列添加自定义的类型
- 序列的回调函数中可以通过get_context来获取到共享数据
- 使用完毕后在序列的回调函数中释放内存
业务需求:访问淘宝、京东、拼多多,把报文体最长的网站URL信息记录到redis当中
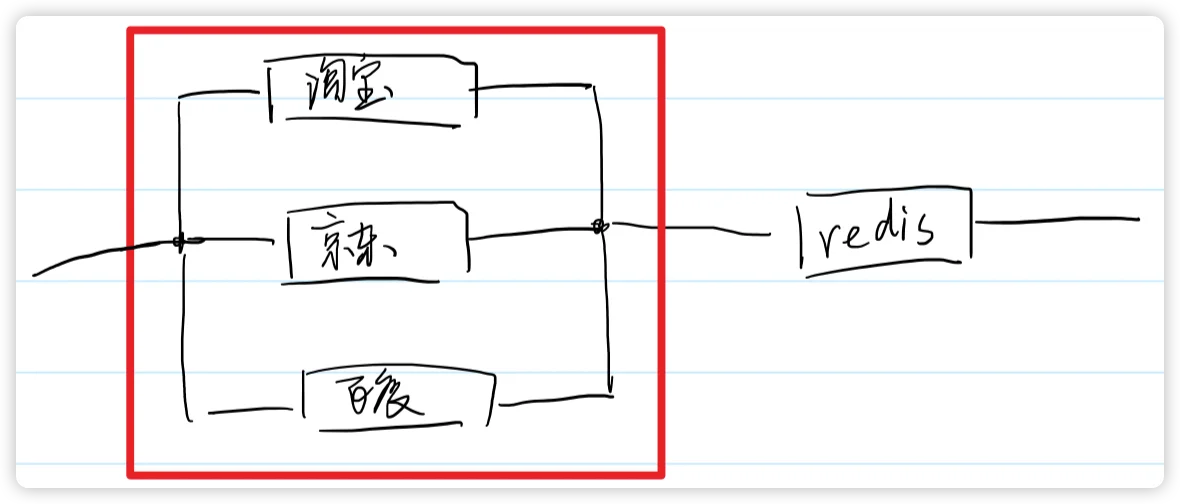
- 淘宝、京东、拼多多本身是一个 http 任务,使用小的序列任务执行他们
- 在小的序列任务中设置并传递共享数据
- 大的红色的框是并行任务
每个任务都是一个序列任务,序列任务是 workflow 框架中最小的任务调度单位,可以通过 start 函数进行查看,其底层是通过 Workflow::start_series_work(this, nullptr) 进行执行的。
#include <iostream>
#include <signal.h>
#include <string>
#include <workflow/WFFacilities.h>
#include <workflow/WFHttpServer.h>
#include <workflow/WFTaskFactory.h>
#include <workflow/Workflow.h>
#define DEBUG
#include "../debug-new.h"
static WFFacilities::WaitGroup wait_group(1);
// A.定义要传递数据的结构体
struct SeriesContext {
std::string url;
int state;
int error;
size_t body_len;
};
void signalhandle(int signo) {
wait_group.done();
std::clog << "Program finished\n";
}
void httpCallback(WFHttpTask *task) {
protocol::HttpResponse *resp = task->get_resp();
const void *body;
size_t size;
resp->get_parsed_body(&body, &size);
// C.获取序列任务中传递数据的结构体并添加要传递的数据
SeriesContext *ctx = static_cast<SeriesContext *>(series_of(task)->get_context());
ctx->state = task->get_state();
ctx->error = task->get_error();
ctx->body_len = size;
std::clog << "size:" << size << " url:" << ctx->url << "\n";
}
void ParallelCallback(const ParallelWork *pwork) {
size_t size = 0;
std::string url;
for (size_t i = 0; i < pwork->size(); ++i) {
// D.获取并行任务中每个小序列任务中共享数据结构体中的数据
SeriesContext *ctx = static_cast<SeriesContext *>(pwork->series_at(i)->get_context());
// E.使用数据
if (ctx->body_len > size) {
size = ctx->body_len;
url = ctx->url;
}
// F.释放空间
delete ctx;
}
std::clog << "max size is " << size << " and url is " << url << "\n";
wait_group.done();
}
int main() {
signal(SIGINT, signalhandle);
// 1.创建一个空的并行任务
ParallelWork *pwork = Workflow::create_parallel_work(nullptr);
std::vector<std::string> urls = {"https://www.jd.com", "https://www.pinduoduo.com", "https://www.taobao.com"};
for (size_t i = 0; i < urls.size(); ++i) {
// 2.创建 http 任务
WFHttpTask *http_work = WFTaskFactory::create_http_task(urls[i], 3, 3, httpCallback);
// 3.创建小的序列任务
SeriesWork *series = Workflow::create_series_work(http_work, nullptr);
// 4.创建共享数据
SeriesContext *ctx = new SeriesContext;
ctx->url = urls.at(i);
// B.将要传递数据的结构体添加到小序列任务重
series->set_context(ctx);
// 5.将小序列加入到并行任务中
pwork->add_series(series);
}
pwork->set_callback(ParallelCallback);
pwork->start();
wait_group.wait();
check_leak();
return 0;
}作为HTTP服务端
相较于客户端任务,服务端的任务相对来说会麻烦一些。服务端的使用过程并非是主动地创建任务然后 异步启动之,相反地,它是一个被动的过程——workflow使用一个专门的WFHttpServer对象来描述服务 端,WFHttpServer对象负责监听端口等待客户端连接,每当有客户端接入的时候,server就会自动创建 一个特殊的服务端任务。
这个服务端任务有以下特殊之处:
- 这个任务是在客户端接入之后由框架自动生成的;
- 用户需要设置一个process函数来找到服务端任务;
- 这个服务端任务回调函数会在序列中所有其他任务执行完之后执行;
- 回复给客户端的响应内容,一定是服务端任务的响应内容;
- 在服务端任务所在序列执行完毕之后,将响应回复给客户端。
process函数对象
process是一个用户设计的函数对象。,其作用就是获取和修改任务的属性,如果业务需要做一些更复杂 的东西,比如需要访问MySQL、redis或者需要发起HTTP连接,那么就需要在服务端任务所在的序列中 添加新的任务。
process是WFHttpServer类构造函数的参数,当服务端启动之后,每当有客户端接入服务端时,process 会在服务端接收完客户端的请求之后在所有的服务端任务执行之前被调用。用户可以使用process获取客 户端请求的内容或者设置响应的内容。
下面是一个简单的示例:
#include <iostream>
#include <signal.h>
#include <string>
#include <workflow/WFFacilities.h>
#include <workflow/WFHttpServer.h>
#include <workflow/WFTaskFactory.h>
#define DEBUG
#include "../debug-new.h"
// 创建一个共享数据的结构体
struct shareData {
std::string name;
std::string password;
protocol::HttpResponse *resp;
};
static WFFacilities::WaitGroup wait_group(1);
void signalCallback(int signo) {
std::clog << "finished a work.\n";
wait_group.done();
}
void fileTaskCallback(WFFileIOTask *task) {
FileIOArgs *args = task->get_args();
shareData *data = static_cast<shareData *>(series_of(task)->get_context());
data->resp->append_output_body((char *)args->buf);
delete data;
delete args->buf;
}
void redisCallback(WFRedisTask *task) {
protocol::RedisResponse *resp = task->get_resp();
shareData *data = static_cast<shareData *>(series_of(task)->get_context());
protocol::RedisValue value;
resp->get_result(value);
if (value.is_array()) {
if (data->name == value.arr_at(0).string_value() && data->password == value.arr_at(1).string_value()) {
data->resp->append_output_body("login success");
} else {
data->resp->append_output_body("login failed");
}
}
delete data;
}
void process(WFHttpTask *serverTask) {
protocol::HttpRequest *req = serverTask->get_req();
protocol::HttpResponse *resp = serverTask->get_resp();
// 获取并判断请求方法
// 如果是 get 方法返回一个登录页面
if (strcmp(req->get_method(), "GET") == 0) {
char *buf = new char[20480]{0};
WFFileIOTask *fileTask = WFTaskFactory::create_pread_task("postform.html", buf, 20480, 0, fileTaskCallback);
shareData *data = new shareData;
data->resp = std::move(resp);
series_of(serverTask)->set_context(data);
series_of(serverTask)->push_back(fileTask);
} else if (strcmp(req->get_method(), "POST") == 0) {
/*
127.0.0.1:6379> hmget site name password
1) "syss"
2) "1234"
127.0.0.1:6379>
*/
// username=syss&password=123
const void *body;
size_t size;
req->get_parsed_body(&body, &size);
std::string bodyString((char *)body);
std::string nameKV = bodyString.substr(0, bodyString.find('&'));
std::string passwordKV = bodyString.substr(bodyString.find("&") + 1);
std::string name = nameKV.substr(nameKV.find("=") + 1);
std::string password = passwordKV.substr(passwordKV.find("=") + 1); // 解析,提取去传入的用户名和密码
shareData *data = new shareData;
data->name = name;
data->password = password;
data->resp = std::move(resp);
series_of(serverTask)->set_context(data);
WFRedisTask *redisTask = WFTaskFactory::create_redis_task("redis://127.0.0.1:6379", 3, redisCallback);
redisTask->get_req()->set_request("HMGET", {"site", "name", "password"});
series_of(serverTask)->push_back(redisTask);
}
}
int main() {
signal(SIGINT, signalCallback);
// 根据process创建了一个server对象
WFHttpServer serv(process);
unsigned short port = 1234;
if (serv.start(port) == 0) {
std::clog << "server statrt on port " << port << "\n";
wait_group.wait();
// 程序结束时千万不要忘记停止server,否则会引起段错误
serv.stop();
} else {
perror("server start");
}
std::clog << "Finished all work.\n";
check_leak();
return 0;
}执行MySQL任务
使用MySQL任务的方法和其他任务的方法是一致的
- 首先使用工厂函数创建一个MySQL类型的任务
- 设置任务的属性,在这里可以设置使用的SQL语句
- 启动任务
- 在回调函数当中可以处理任务响应
- 写类型的任务可以获取SQL指令的执行状态
- 读类型的任务可以获取SQL指令返回的表,包括域的信息和每个值的具体内容
#include <iostream>
#include <signal.h>
#include <workflow/MySQLResult.h>
#include <workflow/WFFacilities.h>
#include <workflow/WFTaskFactory.h>
static WFFacilities::WaitGroup wait_group(1);
void signalCallback(int signo) {
wait_group.done();
}
void mysqlCallback(WFMySQLTask *task) {
// protocol::MySQLResponse *resp = task->get_resp();
protocol::MySQLResultCursor cursor(task->get_resp());
do {
// 遍历结果集合
// 判断指令的类型是 读 select table
if (cursor.get_cursor_status() == MYSQL_STATUS_OK) { // 说明sql语句是写操作
} else if (cursor.get_cursor_status() == MYSQL_STATUS_GET_RESULT) { // 说明sql语句是读操作
std::clog << "field count = " << cursor.get_field_count() << " rows count = " << cursor.get_rows_count() << "\n";
// 找到所有域的信息
// const protocol::MySQLField *const *fields = cursor.fetch_fields();
// for (int i = 0; i < cursor.get_field_count(); ++i) {
// std::clog << "database = " << fields[i]->get_db()
// << " table = " << fields[i]->get_table()
// << " fieldname = " << fields[i]->get_name()
// << " fieldtype = " << datatype2str(fields[i]->get_data_type())
// << "\n";
// }
// 输出表头字段
const protocol::MySQLField *const *fields = cursor.fetch_fields();
for (int i = 0; i < cursor.get_field_count(); ++i) {
std::clog << fields[i]->get_name() << "\t";
}
std::clog << "\n";
// 取出表格当中的所有内容
std::vector<std::vector<protocol::MySQLCell>> rows;
cursor.fetch_all(rows);
// std::clog << rows[0][1].as_string() << "\n";
for (size_t i = 0; i < rows.size(); ++i) {
for (size_t j = 0; j < rows[i].size(); ++j) {
if (rows[i][j].is_int()) {
std::clog << rows[i][j].as_int() << "\t";
} else if (rows[i][j].is_string()) {
std::clog << rows[i][j].as_string() << "\t";
} else if (rows[i][j].is_datetime()) {
std::cerr << rows[i][j].as_datetime() << "\t";
}
}
std::clog << "\n";
}
}
} while (cursor.next_result_set());
wait_group.done();
}
int main() {
signal(SIGINT, signalCallback);
// utf8mb4
WFMySQLTask *mysqlTask = WFTaskFactory::create_mysql_task("mysql://root:123@127.0.0.1/test?character_set=utf8", 3, mysqlCallback);
mysqlTask->get_req()->set_query("SELECT * FROM workflow.user WHERE name like 'syss';");
mysqlTask->start();
wait_group.wait();
std::clog << "Program finished\n";
return 0;
}文件IO任务
相比较于其他的网络通信框架,比如异步通信框架Boost.asio,Boost.beast等等,workflow最为突出的 特性就它将磁盘IO行为、CPU行为以及其他消耗系统资源的行为也抽象成了任务。这样的话,一方面, 使用这些消耗资源的操作的用法会使用之前的网络任务的方式上一致,另一方面,资源的调度完全由框 架实现,降低用户调度和调优的需求和难度。
利用多线程来读写磁盘数据的时候有一些值得注意的事情:多线程通常来说可以充分利用多核心CPU以 提高应用的性能,但是对于读写磁盘文件而言,使用多线程也能提高访问磁盘的速率吗?
使用多线程读写文件是无法提高访问磁盘的速率的。当有多个线程读写同一个文件时,操作系统会将数 据先集中到一片内存区域(这个区域称为磁盘的高速缓存)中,然后由高速缓存统一写入磁盘。一般来 说,和高速缓存交互的时间是非常短,而将数据写入磁盘的时间是比较漫长的,在多核CPU下使用多线 程可以减少和高速缓存交互的时间,显然并没有解决性能瓶颈。
随着多线程技术的广泛应用,有时应用程序会在不知觉的情况使用多线程访问同一个文件,显然这样就 会导致读写文件的并发问题。除了使用加锁的方案,使用基于偏移的读写操作会更加流行——每个线程 都明确知道本线程将要访问的文件内容的范围,这样就可以在不使用锁的情况解决并发问题。这里需要 使用的系统调用是pread和pwrite:这两个系统调用在读写文件的时候,会设置一个初始偏移量——这样 的话,多个线程读写文件时只要指定好本线程起始偏移,就可以避免数据竞争问题。
#include <unistd.h>
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);workflow框架的磁盘文件IO接口就是参考pread和pwrite来设计的。下面是读写磁盘文件所涉及到的接口:
class WFTaskFactory { //...
/* File tasks with path name. */ public:
static WFFileIOTask *create_pread_task(const std::string &pathname, void *buf, size_t count, off_t offset, fio_callback_t callback);
static WFFileIOTask *create_pwrite_task(const std::string &pathname, const void *buf, size_t count, off_t offset, fio_callback_t callback);
}workflow框架在Linux系统版本当中,为了提高磁盘IO的吞吐率,其底层采取了异步IO库(aio),可以使用 man aio 来查询相关的接口设计和使用示例。
执行Go任务
go任务可以将一个简单的函数封装成任务。具体可以查阅文档 点击查看
workflow提供了另一种更简单的使用计算任务的方法,模仿go语言实现的go task。使用go task来实计算任务无需定义输入与输出,所有数据通过函数参数传递。
创建go_task
class WFTaskFactory
{
...
public:
template<class FUNC, class... ARGS>
static WFGoTask *create_go_task(const std::string& queue_name,
FUNC&& func, ARGS&&... args);
};参数说明
- queue_name为计算队列名,其作用在之前示例文档中有过介绍。
- func可以是函数指针,函数对象,仿函数,lambda函数,类的成员函数等任意可调用对象。
- args为func的参数列表。注意当func是一个类的非静态成员函数时,args的第一个成员必须是对象地址。
我们想异步的运行一个加法函数:void add(int a, int b, int& res); 并且我们还想在函数运行结束的时候打印出结果。于是可以这样实现:
#include <stdio.h>
#include <utility>
#include "workflow/WFTaskFactory.h"
#include "workflow/WFFacilities.h"
void add(int a, int b, int& res)
{
res = a + b;
}
int main(void)
{
WFFacilities::WaitGroup wait_group(1);
int a = 1;
int b = 1;
int res;
WFGoTask *task = WFTaskFactory::create_go_task("test", add, a, b, std::ref(res));
task->set_callback([&](WFGoTask *task) {
printf("%d + %d = %d\n", a, b, res);
wait_group.done();
});
task->start();
wait_group.wait();
return 0;
}以上的示例异步运行一个加法,打印结果并退出程序。go task的使用与其它的任务没有多少区别,也有user_data域可以使用。唯一一点不同,是go task创建时不传callback,但和其它任务一样可以set_callback。如果go task函数的某个参数是引用,需要使用std::ref,否则会变成值传递,这是c++11的特征。
把workflow当成线程池
用户可以只使用go task,这样可以将workflow退化成一个线程池,而且线程数量默认等于机器cpu数。 但是这个线程池比一般的线程池又有更多的功能,比如每个任务有queue name,任务之间还可以组成各种串并联或更复杂的依赖关系。
带执行时间限制的go task
通过create_timedgo_task接口(这里无法重载create_go_task接口),可以创建带时间限制的go task:
class WFTaskFactory
{
/* Create 'Go' task with running time limit in seconds plus nanoseconds.
* If time exceeded, state WFT_STATE_SYS_ERROR and error ETIMEDOUT will be got in callback. */
template<class FUNC, class... ARGS>
static WFGoTask *create_timedgo_task(time_t seconds, long nanoseconds,
const std::string& queue_name,
FUNC&& func, ARGS&&... args);
};相比创建普通的go task,create_timedgo_task函数需要多传两个参数,seconds和nanoseconds。
如果func的运行时间到达seconds+nanosconds时限,task直接callback,且state为WFT_STATE_SYS_ERROR,error为ETIMEDOUT。
注意,框架无法中断用户执行中的任务。func依然会继续执行到结束,但不会再次callback。另外,nanoseconds取值区间在[0,10亿)。 另外,当我们给go task加上了运行时间限制,callback的时机可能会先于func函数的结束,任务所在series可能也会先于func结束。
如果我们在func里访问series,可能就是一个错误了。例如:
void f(SeriesWork *series)
{
series->set_context(...); // 错误。当f是一个带超时的go task,此时series可能已经失效了。
}
int http_callback(WFHttpTask *task)
{
SeriesWork *series = series_of(task);
WFGoTask *go = WFTaskFactory::create_timedgo_task(1, 0, "test", f, series); // 1秒超时的go task
series_of(task)->push_back(go);
}这也是为什么,我们不推荐在计算任务的执行函数里,对任务所在的series进行操作。对series的操作,应该在callback里进行,例如:
int main()
{
WFGoTask *task = WFTaskFactory::create_timedgo_task(1, 0, "test", f);
task->set_callback([](WFGoTask *task) {
SeriesWork *series = series_of(task):
void *context = series->get_context();
if (task->get_state() == WFT_STATE_SUCCESS) // 成功执行完
{
...
}
else // state == WFT_STATE_SYS_ERROR && error == ETIMEDOUT // 超过运行时间限制
{
...
}
});
}但是,在计算函数里使用task,是安全的。所以,可以使用task->user_data,在计算函数和callback之间传递数据。例如:
int main()
{
WFGoTask *task = WFTaskFactory::create_timedgo_task(1, 0, "test", [&task]() {
task->user_data = (void *)123;
});
task->set_callback([](WFGoTask *task) {
SeriesWork *series = series_of(task):
void *context = series->get_context();
if (task->get_state() == WFT_STATE_SUCCESS) // 成功执行完
{
int result = (int)task->user_data;
}
else // state == WFT_STATE_SYS_ERROR && error == ETIMEDOUT // 超过运行时间限制
{
...
}
});
task->start();
...
}
重置go task的执行函数
在某些时候,我们想在go task的执行函数里访问task,如上面的例子,将计算结果写入task的user_data域。
上例中,我们使用了引用捕获。但明显引用捕获会有一些问题。比如task本身的生命周期。我们更希望在执行函数里直接捕获go task指针。
直接进行值捕获明显是错误的,例如:
WFGoTask *task = WFTaskFactory::create_timedgo_task(1, 0, "test", [task]() {
task->user_data = (void *)123;
});这段代码并不能在lambda函数里得到task指针,因为捕获执行时,task还没有赋值。但我们可以通过以下的代码,实现这个需求:
WFGoTask *task = WFTaskFactory::create_timedgo_task(1, 0, "test", nullptr); // 执行函数可以初始化为nullptr
WFTaskFactory::reset_go_task(task, [task]() {
task->user_data = (void *)123;
});WFTaskFactory::reset_get_task()函数,用于重置go task的执行函数。因为task已经创建完毕,这时候在lambda函数里捕获task,就是一个正确的行为了。