内存布局
程序运行前
C代码经过 4步后生成一个可执行程序。
在 Windows 下,程序是一个普通的可执行文件;以下列出一个Linux环境下二进制可执行文件的基本情况:

通过上图可以得知,在没有运行程序前,也就是说,可执行程序内部已经分好3段信息,分别为 3个部分(有些人直接把data和bss合起来叫做静态区或全局区)。
代码区
存放 CPU 执行的机器指令。通常代码区是可共享的(即另外的执行程序可以调用它),使其可共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可。代码区通常是只读的,使其只读的原因是防止程序意外地修改了它的指t令。另外,代码区还规划了局部变量的相关信息。
全局初始化数据区/静态数据区(data段)
该区包含了在程序中明确被初始化的全局变量、已经初始化的静态变量(包括全局静态变量和t)和常量数据(如字符串常量)。
未初始化数据区(又叫 bss 区)
存入的是全局未初始化变量和未初始化静态变量。未初始化数据区的数据在程序开始执行之前被内核初始化为 0 或者空(NULL)。
那为什么把程序的指令和程序数据分开呢?
- 程序被load到内存中之后,可以将数据和代码分别映射到两个内存区域。由于数据区域对进程来说是可读可写的,而指令区域对程序来讲说是只读的,所以分区之后呢,可以将程序指令区域和数据区域分别设置成可读可写或只读。这样可以防止程序的指令有意或者无意被修改;
- 当系统中运行着多个同样的程序的时候,这些程序执行的指令都是一样的,所以只需要内存中保存一份程序的指令就可以了,只是每一个程序运行中数据不一样而已,这样可以节省大量的内存。比如说之前的Windows Internet Explorer 7.0运行起来之后, 它需要占用112 844KB的内存,它的私有部分数据有大概15 944KB,也就是说有96 900KB空间是共享的,如果程序中运行了几百个这样的进程,可以想象共享的方法可以节省大量的内存。
程序运行后
程序在加载到内存前, 程序运行期间不能改变。然后,运行可执行程序,系统把程序加载到内存,
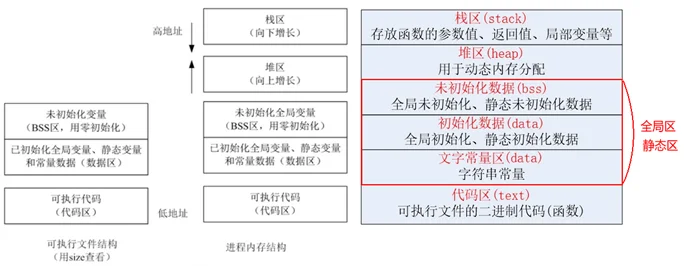
代码区(text segment)
加载的是可执行文件代码段,所有的可执行代码都加载到代码区,这块内存是不可以在运行期间修改的。
未初始化数据区(BSS)
加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静 态未初始化数据)的生存周期为整个程序运行过程。
全局初始化数据区/静态数据区(data segment)
加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据,文字常量(只读))的数据的 生存周期为整个程序运行过程。
栈区(stack)
栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程 序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
堆区(heap)
堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存 中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
存储类型总结
| 类型 | 作用域 | 生命周期 | 存储位置 |
|---|---|---|---|
| auto变量 | 一对{}内 | 当前函数 | 栈区 |
| static局部变量 | 一对{}内 | 整个程序运行期 | 初始化在data段,未初始化在BSS段 |
| extern变量 | 整个程序 | 整个程序运行期 | 初始化在data段,未初始化在BSS段 |
| static全局变量 | 当前文件 | 整个程序运行期 | 初始化在data段,未初始化在BSS段 |
| extern函数 | 整个程序 | 整个程序运行期 | 代码区 |
| static函数 | 当前文件 | 整个程序运行期 | 代码区 |
| register变量 | 一对{}内 | 当前函数 | 运行时存储在CPU寄存器 |
| 字符串常量 | 当前文件 | 整个程序运行期 | data段 |
#include <stdio.h>
#include <stdlib.h>
int e;
static int f;
int g = 10;
static int h = 10;
int main(void) {
int a;
int b = 10;
static int c;
static int d = 10;
char *i = "test";
char *k = NULL;
printf("&a\t %p\t //局部未初始化变量\n", &a);
printf("&b\t %p\t //局部初始化变量\n", &b);
printf("&c\t %p\t //静态局部未初始化变量\n", &c);
printf("&d\t %p\t //静态局部初始化变量\n", &d);
printf("&e\t %p\t //全局未初始化变量\n", &e);
printf("&f\t %p\t //全局静态未初始化变量\n", &f);
printf("&g\t %p\t //全局初始化变量\n", &g);
printf("&h\t %p\t //全局静态初始化变量\n", &h);
printf("i\t %p\t //只读数据(文字常量区)\n", i);
k = (char *) malloc(10);
printf("k\t %p\t //动态分配的内存\n", k);
return 0;
}程序输出:
&a 0x7fffffffe328 //局部未初始化变量
&b 0x7fffffffe324 //局部初始化变量
&c 0x555555558048 //静态局部未初始化变量
&d 0x55555555803c //静态局部初始化变量
&e 0x55555555804c //全局未初始化变量
&f 0x555555558050 //全局静态未初始化变量
&g 0x555555558038 //全局初始化变量
&h 0x555555558040 //全局静态初始化变量
i 0x555555556004 //只读数据(文字常量区)
k 0x5555555596b0 //动态分配的内存内存分区模型
栈区
由系统进行内存的管理。主要存放函数的参数以及局部变量。在函数完成执行,系统⾃行释放栈区内存,不需要用户管理。
#include <stdio.h> #include <stdlib.h>
char *func() {
char p[] = "hello world!";//在栈区存储 乱码
printf("%s\n", p);
return p;
}
void test() {
char *p = NULL;
p = func();
printf("%s\n", p);
}
int main(void) {
test();
return 0;
}程序输出:
hello world!
烫烫烫烫烫烫烫烫烫烫烫堆区
由编程人员⼿动申请,⼿动释放,若不⼿动释放,程序结束后由系统回收,生命周期是整个程序运行期间。使用malloc或者new进行堆的申请。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *func() {
char *str = malloc(100);
strcpy(str, "hello world!");
printf("%s\n", str);
return str;
}
void test01() {
char *p = NULL;
p = func();
printf("%s\n", p);
}
void allocateSpace(char *p) {
p = malloc(100);
strcpy(p, "hello world!");
printf("%s\n", p);
}
void test02() {
char *p = NULL;
allocateSpace(p);
printf("%s\n", p);
}
int main(void) {
printf("test01 print:\n");
test01();
printf("\n\ntest02 print:\n");
test02();
return 0;
}程序输出:
test01 print:
hello world!
hello world!
test02 print:
hello world!
(null)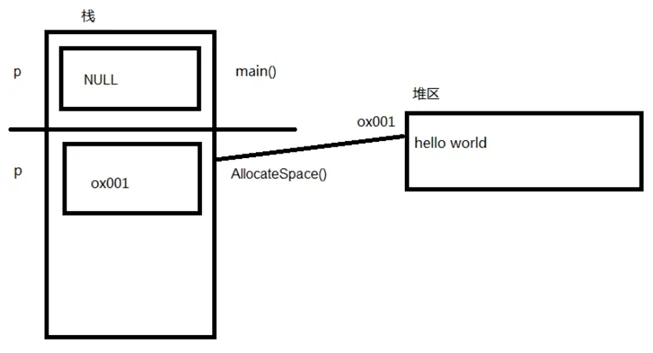
全局/静态区
全局静态区内的变量在编译阶段已经分配好内存空间并初始化。这块内存在程序运行期间一直存在,它主要存储全局变量、静态变量和常量。
注意:
这里不区分初始化和未初始化的数据区,是因为静态存储区内的变量若不显⽰初始化,则编译器会⾃动以默认的⽅式进行初始化,即静态存储区内不存在未初始化的变量。
全局静态存储区内的常量分为常变量和字符串常量,一经初始化,不可修改。静态存储内的常变量是全局变量,与局部常变量不同,区别在于局部常变量存放于栈,实际可间接通过指针或者引用进行修改,而全局常变量存放于静态常量区则不可以间接修改。
字符串常量存储在全局/静态存储区的常量区。
⽰例代码:
int v1 = 10;//全局/静态区
const int v2 = 20; //常量,一旦初始化,不可修改
static int v3 = 20; //全局/静态区
char* p1; //全局/静态区,编译器默认初始化为NULL
//那么全局static int 和 全局int变量有什么区别?
void test() {
static int v4 = 20; //全局/静态区
}加深理解:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
char *func() {
static char arr[] = "hello world!";//在静态区存储 可读可写
arr[2] = 'c';
char *p = "hello world!";//全局/静态区-字符串常量区
//p[2] = 'c'; //只读,不可修改
printf("%d\n", arr);
printf("%d\n", p);
printf("%s\n", arr);
return arr;
}
void test() {
char *p = func();
printf("%s\n", p);
}
int main(void) {
test();
return 0;
}程序输出:
1431666736
1431658500
heclo world!
heclo world!字符串常量是否可修改?
字符串常量优化:
ANSI C中规定:修改字符串常量,结果是未定义的。
ANSI C并没有规定编译器的实现者对字符串的处理,例如:
1.有些编译器可修改字符串常量,有些编译器则不可修改字符串常量。
2.有些编译器把多个相同的字符串常量看成一个(这种优化可能出现在字符串常量中,节省空间),有些则不进行此优化。如果进行优化,则可能导致修改一个字符串常量导致另外的字符串常量也发生变化,结果不可知。
C99标准:char *p = "abc"; defines p with type ‘‘pointer to char’’ and initializes it to point to an object with type ‘‘array of char’’ with length 4 whose elements are initialized with a character string literal. If an attempt is made to use p to modify the contents of the array, the behavior is undefined.
字符串常量地址是否相同?
- tc2.0,同文件字符串常量地址不同。
- Vs2013,字符串常量地址同文件和不同文件都相同。
- Dev c++、QT同文件相同,不同文件不同。
总结
在理解C/C++内存分区时,常会碰到如下术语:数据区,堆,栈,静态区,常量区,全局区,字符串常量区,文字常量区,代码区等等,初学者被搞得云里雾里。在这里,尝试捋清楚以上分区的关系。
数据区包括:堆,栈,全局/静态存储区。
全局/静态存储区包括:常量区,全局区、静态区。
常量区包括:字符串常量区、常变量区。
代码区:存放程序编译后的二进制代码,不可寻址区。
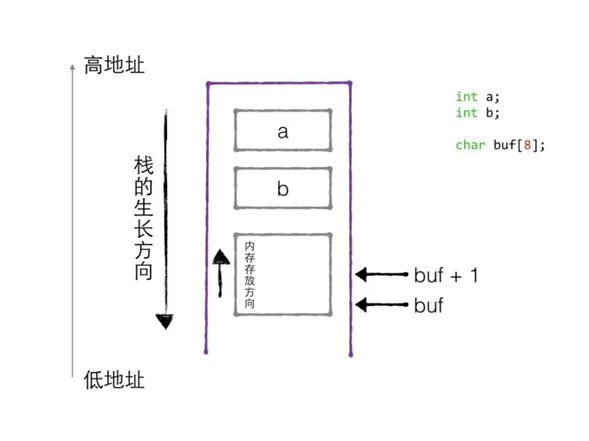
栈的生长方向和内存存放方向
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
//1. 栈的生长⽅向
void test01() {
int a = 10;
int b = 20;
int c = 30;
int d = 40;
printf("a = %d\n", &a);
printf("b = %d\n", &b);
printf("c = %d\n", &c);
printf("d = %d\n", &d);
//a的地址⼤于b的地址,故而生长⽅向向下
}
//2. 内存生长⽅向(⼩端模式)
void test02() {
//⾼位字节 -> 地位字节
int num = 0xaabbccdd;
unsigned char *p = #
//从⾸地址开始的第一个字节
printf("%x\n", *p);
printf("%x\n", *(p + 1));
printf("%x\n", *(p + 2));
printf("%x\n", *(p + 3));
}
int main(void) {
printf("test01 print:\n");
test01();
printf("\n\ntest02 print:\n");
test02();
return 0;
}程序输出:
test01 print:
a = -7204
b = -7208
c = -7212
d = -7216
test02 print:
dd
cc
bb
aa内存分区代码分析
返回栈区地址
#include <stdio.h>
#include <stdlib.h>
int *fun() {
int a = 10;
return &a;//函数调用完毕,a释放
}
int main(void) {
int *p = NULL;
p = fun();
*p = 100;//操作野指针指向的内存,err
printf("%d\n", *p);
printf("%d\n", *p);
return 0;
}程序输出:
100
32767注意
对于栈区已经释放的内存地址程序运行时会保护一次,之后再次使用则不受保护,不能依赖这种保护机制。
返回data区地址
#include <stdio.h>
#include <stdlib.h>
int *fun() {
static int a = 10;
return &a;//函数调用完毕,a不释放
}
int main(void) {
int *p = NULL;
p = fun();
*p = 100;//ok
printf("*p = %d\n", *p);
printf("*p = %d\n", *p);
return 0;
}程序输出:
*p = 100
*p = 100值传递1
#include <stdio.h>
#include <stdlib.h>
int *fun() {
static int a = 10;
return &a;//函数调用完毕,a不释放
}
int main(void) {
int *p = NULL;
p = fun();
*p = 100;//ok
printf("*p = %d\n", *p);
printf("*p = %d\n", *p);
return 0;
}
值传递2
#include <stdio.h>
#include <stdlib.h>
void fun(int *tmp) {
*tmp = 100;
}
int main(void) {
int *p = NULL;
p = (int *) malloc(sizeof(int));
fun(p);//值传递
printf("*p = %d\n", *p);//ok,*p为100
printf("*p = %d\n", *p);
return 0;
}程序输出:
*p = 100
*p = 100返回堆区地址
#include <stdio.h>
#include <stdlib.h>
int *fun() {
int *tmp = NULL;
tmp = (int *) malloc(sizeof(int));
*tmp = 100;
return tmp;//返回堆区地址,函数调用完毕,不释放
}
int main(void) {
int *p = NULL;
p = fun();
printf("*p = %d\n", *p);//ok
printf("*p = %d\n", *p);
//堆区空间,使用完毕,⼿动释放
if (p != NULL) {
free(p);
p = NULL;
}
return 0;
}程序输出:
*p = 100
*p = 100面试题
C/C++堆栈大小
C++中的“堆栈大小”可能涉及内存栈或数据结构容器。 内存栈默认大小因平台而异(Windows 1MB,Linux 8MB),可通过编译选项或运行时API调整;栈溢出需通过动态内存分配或算法优化规避。 std::stack容器默认无固定大小限制,但可封装实现容量限制。实际开发中需区分两者,并根据场景合理管理内存。
Details
在C++面试中,若面试官提问“堆栈大小”相关问题,可能的考察方向包括内存模型中的栈空间(Stack)特性、默认大小限制、设置方法,以及与数据结构中的堆栈容器(如std::stack)的区别。以下是系统化的回答框架,结合多个角度:
一、内存模型中的栈空间(Stack)
默认大小与平台差异
• Windows:默认栈大小为1MB(通过编译器选项可调整)。
• Linux:默认栈大小通常为8MB或更大(通过ulimit -s查询或修改)。
• 原因:栈空间用于存放局部变量、函数调用信息等,过小易溢出,过大浪费内存资源。设置栈大小的方式
编译时设置:
GCC/Clang:
-Wl,--stack=<size>(如-Wl,--stack,10485760设置10MB)。MSVC:
/STACK链接器选项(如/STACK:10485760)。
运行时设置(仅限Linux):
- 使用
setrlimit(RLIMIT_STACK, ...)动态调整当前线程栈大小。
- 使用
栈溢出的风险与规避
- 常见原因:递归深度过大、局部变量(如大数组)占用过多栈空间。
- 规避方法:
- 将大型数据改为堆分配(
new/malloc)。 - 限制递归深度或改用迭代算法。
- 将大型数据改为堆分配(
- 检测工具:Valgrind、AddressSanitizer等内存分析工具。
二、数据结构中的堆栈容器(std::stack)
与内存栈的区别
• 用途:std::stack是容器适配器,用于数据管理(LIFO),与内存栈的底层机制无关。
• 容量限制:默认无固定大小限制,但底层容器(如std::deque)可能有动态扩展策略。自定义大小限制的实现
• 通过封装std::stack并添加容量检查逻辑(示例代码见搜索结果):cpptemplate <typename T> class LimitedStack { private: std::stack<T> data; size_t max_size; public: LimitedStack(size_t size) : max_size(size) {} void push(const T& value) { if (data.size() >= max_size) throw std::overflow_error("Stack full!"); data.push(value); } // 其他操作类似... };
三、面试回答建议
明确问题意图:
• 若面试官问“堆栈大小”,优先解释内存栈的默认值、设置方法及溢出处理。
• 若涉及数据结构,补充std::stack的容量特性。结合应用场景:
• 举例说明栈溢出场景(如深度递归、大数组)及优化方案。
• 对比不同平台默认值的工程意义(如嵌入式系统需谨慎设置栈大小)。延伸知识点:
• 栈与堆的对比:分配效率、管理方式、碎片问题。
• 栈生长方向:向低地址扩展(与堆相反)。
通过多角度拆解,既能展示对底层内存模型的理解,又能体现工程实践能力,符合面试考察预期。