C/C++程序运行过程
C源文件经过预处理、编译、汇编、链接后,生成可执行文件,这就是一个C语言可执行程序(Program)。可执行文件被操作系统加载到内存中,程序得以运行,运行的程序我们称之为"进程(Process)"。
此时操作系统会为每一个进程分配。那么什么是虚拟内存空间呢?
虽然这更多是操作系统课程中的概念,但大家至少还是需要了解一下。
什么是虚拟内存空间?
"虚拟"这一术语用于描述这种机制,因为每个进程获得的内存空间并不是实际物理内存中连续的一段。实际上,这些虚拟地址都是由操作系统与硬件(主要是内存管理单元,MMU)共同管理,以映射到物理内存地址。
当一个进程启动时,它所“看到”的是操作系统为其分配的这种 连续的虚拟内存空间,而这些虚拟地址并不直接等同于实际的物理内存地址。

实际上虚拟内存空间可以看作是操作系统和物理内存之间的一个抽象层,如上图所示。 这种分层的设计,具有以下优点:
- 降低了内存管理的复杂性,提高了内存管理的效率。操作系统现在只需管理虚拟地址到物理地址的映射,简化了内存分配和回收的过程。
- 增强系统安全性和稳定性。由于每个进程都有自己独立的虚拟内存空间,因此相互之间难以直接访问或干扰,从而提高了安全性。
- 通过一些内存管理的技术,可以实现更灵活、更高效的内存管理。举例如下:
- 基于虚拟内存空间的技术,操作系统甚至可以将磁盘的空间暂时作为内存空间使用(虚拟内存技术),这使得运行大型应用程序变得可能,即使在物理内存不足的情况下也能保持运行。
- 内存复用。同一片物理内存可以被多个进程使用,但在进程各自的虚拟内存空间中,进程仍然是隔离的。
总之,一系列的好处使虚拟内存成为现代操作系统中不可或缺的一部分。
虚拟内存空间模型
为了更直观的从C程序的视角理解虚拟内存空间,帮助C程序员更好的管理和操作内存,我们用虚拟内存空间模型来描述虚拟内存空间。
虚拟内存空间模型将一个C进程的虚拟内存空间,划分为几个不同的内存区域,这些内存区域存放的数据、用途、特点等皆有不同,是我们后续学习课程的重点!
虽然不同的平台、操作系统在虚拟内存空间模型上可能会有所差异,但虚拟内存空间模型普遍包括以下几个关键部分:
![]()
从低地址到高地址,虚拟内存空间模型的内存区域包括:
代码段(Code)
- 代码段一般位于虚拟内存空间的最低地址处。
- 代码段用于存放一个C程序编译后得到的可执行代码指令,一般是只读的。
- C程序员的操作一般不涉及代码段。
- 数据段用于存放程序运行时具有静态存储期限的全局数据,包括:全局变量和静态变量(static修饰的局部变量和全局变量)
- 数据段还用于存储程序运行时的只读数据,比如字符串字面值。
.data section
存放 已初始化且初始值非零 的全局变量和静态变量(包括 static 修饰的局部变量和全局变量)。
int global_var = 42; // 全局变量,初始值非零 → 存入 .data
static int static_var = 100; // 静态变量,初始值非零 → 存入 .data.rodata section
存放 只读的常量数据,例如字符串常量、const 修饰的全局变量,或编译时已知的常量表达式。
const char* str = "Hello"; // 字符串常量 → 存入 .rodata
const int MAX_SIZE = 1024; // const 全局常量 → 存入 .rodata.bss section
存放 未初始化 或 初始化为零 的全局变量和静态变量。这些变量在程序加载时由系统自动初始化为零,不占用磁盘空间(仅在内存中分配)。
int uninit_global; // 未初始化的全局变量 → 存入 .bss
static int static_zero = 0; // 初始化为零的静态变量 → 存入 .bss三者的核心区别
| 段名 | 存储内容 | 是否占用磁盘空间 | 读写权限 | 示例 |
|---|---|---|---|---|
.data | 已初始化且非零的全局/静态变量 | 是 | 可读可写 | int a = 42; |
.rodata | 只读的常量数据(如字符串、const) | 是 | 只读 | const char* s = "abc"; |
.bss | 未初始化或初始化为零的全局/静态变量 | 否(仅在内存分配) | 可读可写 | int b; 或 static int c = 0; |
- 堆空间是虚拟内存空间中C程序员最关注的区域,没有之一。
- 堆空间涉及到C程序的动态内存分配和管理,我们常说C语言可以操作和管理内存,最主要说的就是管理堆空间。对堆空间的自由管理,也是C语言和其他语言(如Java)的重要区别!
- 堆空间往往占据虚拟内存空间的大部分,它可以按照程序员的需求,自由的从低地址向高地址生长。
- 栈空间也是C程序员比较关注的内存区域。
- C语言是一门以函数调用为核心的编程语言,而栈空间保障了函数调用的正常进行,决定了函数调用的流程。
- 栈空间的特点是"先进后出"。它会随着函数调用从高地址向低地址生长,也会随着函数调用结束裁剪内存空间。栈空间的大小往往十分有限,内存占用远小于堆空间。
内核区域(Kernel)
- 内核区域由操作系统内核使用,存储内核代码和内核级的数据结构。
- 应用程序通常不能直接访问内核空间。但涉及到"系统调用"时,应用程序会从"用户态"转入"内核态",此时应用程序就可以访问内核区域了。
查看相关信息的方法
通过
size命令查看段大小:bashsize ./your_program输出结果会显示各段的大小(单位为字节)。
通过
objdump查看详细分布:bashobjdump -h ./your_program通过
nm命令查看符号表:bashnm ./your_program
内存地址的概念
相信每一位对C语言有一丢丢了解的同学,都听说过"内存地址"的概念。
什么是内存地址?
内存地址是(虚拟)内存空间中某个位置的唯一性标识。由于现代计算机的最小寻址单位是1个字节(即8个bit位),所以我们可以直接认为,
和内存地址相对应的还有一个非常重要的概念:
什么是变量地址?
变量地址:
比如一个32位(4字节)的整数变量,那么这个变量的地址指的是这4字节中的第一个字节的地址。
C语言提供了专门的取地址运算符 &,它一般用于和一个变量名结合,如 &a,用于取变量 a 的内存地址。当然此时你得到的就是变量 a 的第一个字节的内存地址。
注意
在C语言编程中,我们提到的"内存地址"总是指虚拟内存空间地址,简称"虚地址"。
地址值
内存地址是虚拟内存空间中某1个字节区域的唯一性标识,为了直观地描述这些地址,我们使用了"地址值"这个概念。
高地址和低地址
在描述虚拟内存地址时,我们可以把虚拟内存空间想象成一个多单元(多字节)组成的数组,每个单元都有其唯一标号"索引",这个"索引值"就是其地址值。
这样我们就得到了"低地址"和"高地址"两个不同的概念:- 低地址:位于内存取值范围的较低端,即接近0的地址。
- 高地址:相对于低地址而言,高地址指的是内存范围中接近最大地址的部分。
示例
假设有一个内存范围从地址 0x1000 到地址 0x2000:
0x1000就是这个范围的低地址。0x2000就是这个范围的高地址。
明确高、低地址的概念十分重要,比如:
- 我们描述虚拟内存空间,当我们说从"低地址到高地址",意味着从代码段到内核虚拟内存这样的内存排布。
- 堆(heap)通常从低地址开始向高地址增长,栈(stack)则从高地址开始向低地址增长。
那么对于一个具体的平台而言,虚拟内存空间的最大地址是什么呢?
实际上,虚拟内存空间的最大地址通常由平台的地址位数决定。目前主流的平台有两种:
- 32位架构平台
- 64位架构平台
32位系统平台
地址总位数是32位,虚拟内存空间中存在232个可能的地址,也就是对应232个字节(即4GB)的虚拟内存空间。这232个可能中:
- 最小的可能(低地址),所有位都是
0,即00000000 00000000 00000000 00000000,即十六进制的0x00000000。 - 最大的可能(高地址),所有位都是
1,即11111111 11111111 11111111 11111111,即十六进制的0xFFFFFFFF。
0x00000000 到 0xFFFFFFFF,这个十六进制数的每一个取值就代表内存中的一个字节内存区域。64位系统平台
地址总位数是64位,虚拟内存空间中存在264个可能的地址,对应着极大的虚拟地址空间(理论上有16 EB,也就是224TB)。
然而,现代64位架构和操作系统并没有利用所有64位进行寻址,主要是由于:
- 当前的硬件无法支持如此大的物理内存。
- 也没有应用需要如此大的内存空间。
现代的64位操作系统,大多只实际使用48位来进行虚拟内存空间寻址。
注意
在现代的编程生产环境中,64位软件架构可能是更常见的选择。64位架构意味着可利用的内存空间更大以及更强大的性能。但这并不意味着32位软件架构就被淘汰了,32位架构意味着更小的内存占用,以及更好的兼容性。
总之,两种架构更多是一种并存的状态,很多软件都会同时开发32位架构和64位架构两种版本。
但在学习过程中,为了便于大家理解虚拟内存,简化地址值,我们会选择将代码运行在32位平台。
小端存储
搞清楚上述概念后,现在我们可以把虚拟内存空间简化看成一个数组,而地址值就是这个数组的索引下标,如下图所示:

如果你理解了上图,那么我就要提出一个新的问题了:
"数组"中要存储元素数据,每个存储单元是1个字节,需要存储1个字节的数据,那么要如何存储呢?
比如一个占32位(4个字节)的整型数据变量 int num = 10;,在虚拟内存空间中该如何存储呢?
我们都知道计算机中存储整数,采用的是有符号数补码的形式存储,变量num用补码形式表示是: 00000000 00000000 00000000 00001010。那么虚拟内存空间中存储num,就是按顺序从低地址到高地址存储这个补码吗?
当然不是,
在采用小端存储时,1个字节的低有效位被存储在低地址上,也就是说num是按照下列格式从低地址到高地址存储的: 00001010 00000000 00000000 00000000(数据的低有效位存储在低地址端) 。如果画图来描述的话就是:
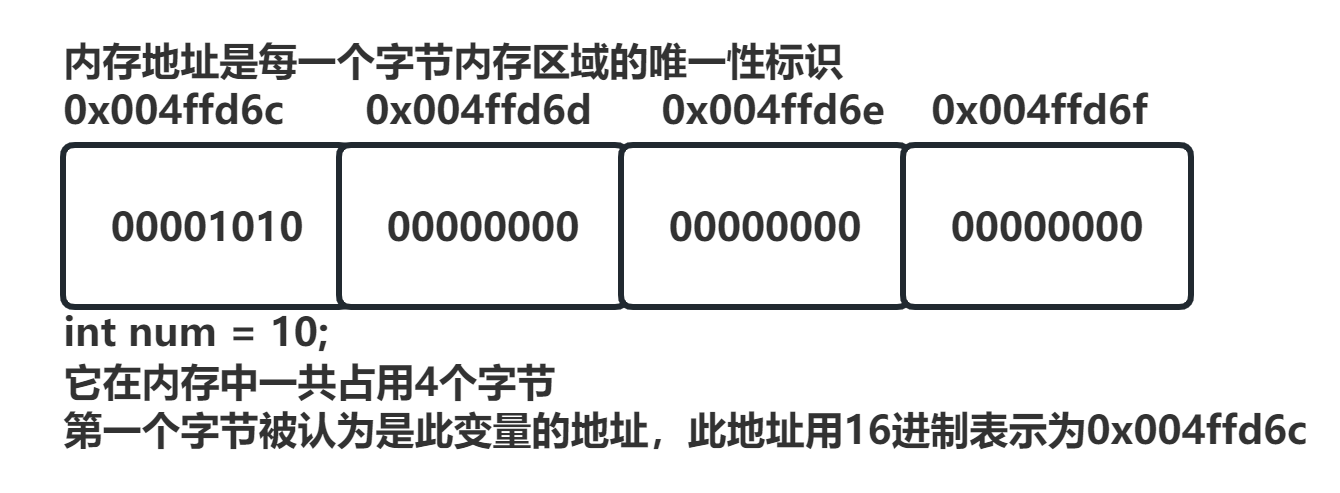
此图描述了一个int类型变量:
- 它占用4个字节的内存空间,地址范围是
0x004ffd6c~0x004ffd6f - 此变量的地址是
0x004ffd6c - 这4个字节的空间共同存储了整数值
10,其中最低地址的字节(0x004ffd6c)存储了10的低有效位,其余高地址字节存储0。
简单汇编指令解析
汇编语言是计算机底层编程的核心工具,掌握它可以帮助开发者深入理解程序运行机制、优化性能,甚至进行恶意软件分析。本文将以x86架构32位系统为基础,系统解析汇编代码的核心要素,涵盖寄存器、内存管理、指令集和程序结构等关键内容。
汇编语法
AT&T:Linux环境
<instruction> <src1> <src2> <dst>可使用 objdump -S 可执行程序路径 查看,如果编译时有 -g 参数,还可看到源代码
寄存器体系:CPU的"工作台"
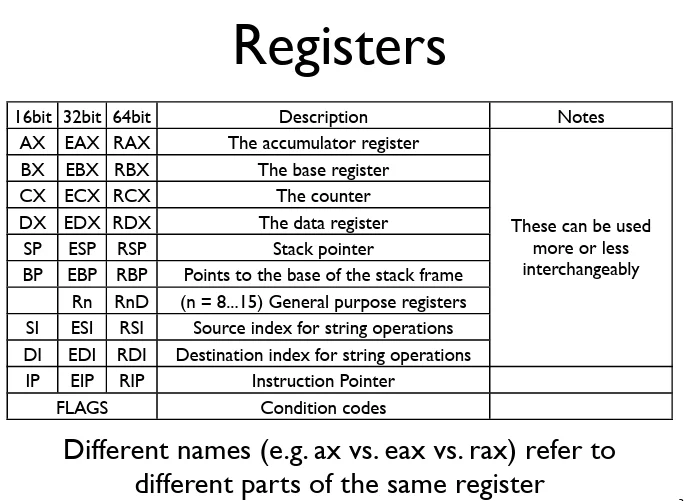
x86架构32位系统包含8个32位通用寄存器,每个寄存器都有约定俗成的用途:
EAX:累加器(函数返回值存储地)
EBX:基址寄存器(常用于数据段寻址)
ECX:计数器(循环操作专用)
EDX:数据扩展(I/O操作和辅助计算)
ESI/EDI:源/目标索引(字符串操作核心)
ESP:栈指针(实时追踪栈顶位置)
EBP:基址指针(函数调用时保存堆栈帧)特殊寄存器:
- EIP:指令指针,指向下一条待执行指令
- EFLAGS:标志寄存器,记录运算状态(如ZF零标志、CF进位标志、OF溢出标志)
 图片来源: https://cseweb.ucsd.edu/classes/sp10/cse141/pdf/02/S01_x86_64.key.pdf
图片来源: https://cseweb.ucsd.edu/classes/sp10/cse141/pdf/02/S01_x86_64.key.pdf
内存管理:程序的"生存空间"
内存分段模型
32位系统采用平坦内存模型(Flat Memory Model),程序可访问4GB线性地址空间:
- 代码段(.text):存放可执行指令
- 数据段(.data/.bss):存储初始化/未初始化静态数据
- 堆栈段(.stack):函数调用时存储参数和局部变量
数据声明示例
section .data
msg db 'Hello World!',0xA ; 定义字符串(0xA为换行符)
num dd 1234h ; 定义32位整型
arr times 100 dd 0 ; 声明100个双字数组寻址模式
- 直接寻址:
mov eax, [0x8048000] - 寄存器间接:
mov ecx, [ebx] - 基址+偏移:
mov edx, [esi+4] - 比例因子寻址:
mov eax, [ebx+4*esi](适用于数组遍历)
核心指令集解析
数据传输类
| 指令 | 功能 | 特性 |
|---|---|---|
| MOV | 寄存器/内存间数据复制 | 不修改标志位 |
| LEA | 计算有效地址(不访问内存) | 常用于数组指针计算 |
| PUSH/POP | 压栈/弹栈操作 |
算术逻辑类
ADD EAX, EBX ; EAX = EAX + EBX(影响CF/ZF/OF)
IMUL ECX ; EDX:EAX = EAX * ECX(有符号乘法)
AND AL, 0x0F ; 低四位掩码运算(常用于十六进制处理)
SHL EAX, 3 ; 逻辑左移3位(相当于乘以8)流程控制类
- 条件跳转:
CMP EAX, 10→JE equal(若相等则跳转) - 循环控制:
LOOP label(ECX自减后非零跳转) - 函数调用:
CALL func() →RET()
汇编分析函数调用过程
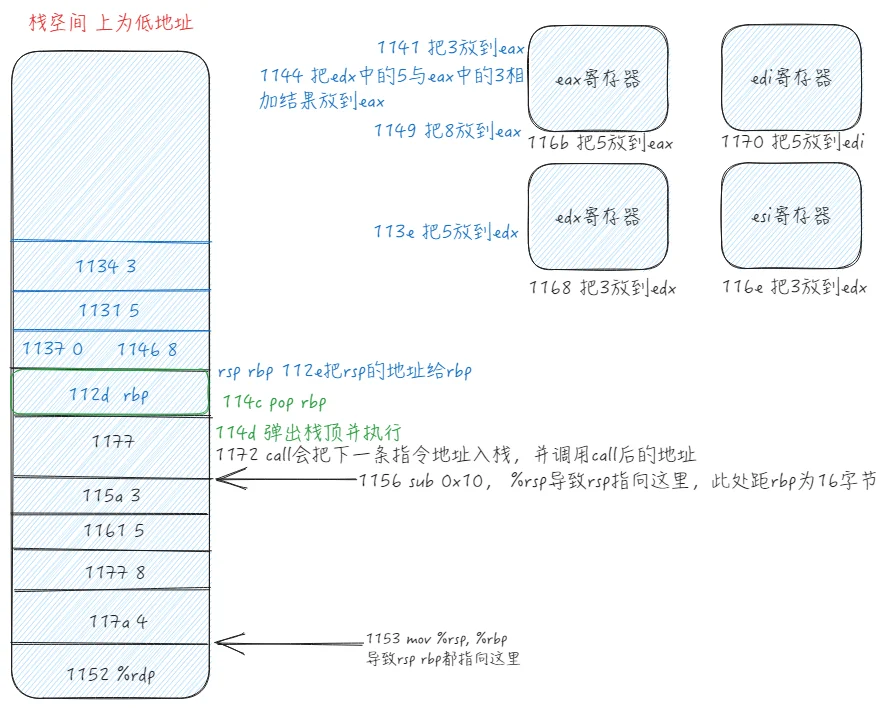
在C语言中,函数调用是一个非常重要的过程,它涉及到函数的参数传递、栈帧的创建和销毁等。下面我们通过一个简单的C程序,来深入了解函数调用的过程。
int add(int lhs, int rhs) {
int temp = 0;
temp = lhs + rhs;
return temp;
}
int main(void) {
int a = 3;
int b = 5;
int ret = add(a, b);
int c = 4;
return 0;
}对应可执行程序汇编代码,可使用
# 环境为Linux,使用AT&T汇编语法
# 删除了其他信息,只留下了main函数和add函数的汇编指令
0000000000001129 <add>:
1129: f3 0f 1e fa endbr64
112d: 55 push %rbp
112e: 48 89 e5 mov %rsp,%rbp
1131: 89 7d ec mov %edi,-0x14(%rbp)
1134: 89 75 e8 mov %esi,-0x18(%rbp)
1137: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
113e: 8b 55 ec mov -0x14(%rbp),%edx
1141: 8b 45 e8 mov -0x18(%rbp),%eax
1144: 01 d0 add %edx,%eax
1146: 89 45 fc mov %eax,-0x4(%rbp)
1149: 8b 45 fc mov -0x4(%rbp),%eax
114c: 5d pop %rbp
114d: c3 ret
000000000000114e <main>:
114e: f3 0f 1e fa endbr64
1152: 55 push %rbp
1153: 48 89 e5 mov %rsp,%rbp
1156: 48 83 ec 10 sub $0x10,%rsp
115a: c7 45 f0 03 00 00 00 movl $0x3,-0x10(%rbp)
1161: c7 45 f4 05 00 00 00 movl $0x5,-0xc(%rbp)
1168: 8b 55 f4 mov -0xc(%rbp),%edx
116b: 8b 45 f0 mov -0x10(%rbp),%eax
116e: 89 d6 mov %edx,%esi
1170: 89 c7 mov %eax,%edi
1172: e8 b2 ff ff ff call 1129 <add>
1177: 89 45 f8 mov %eax,-0x8(%rbp)
117a: c7 45 fc 04 00 00 00 movl $0x4,-0x4(%rbp)
1181: b8 00 00 00 00 mov $0x0,%eax
1186: c9 leave
1187: c3 ret