数据的存储
对于任何开发语言而言,整型都是必须要使用的数据类型之一,对于C语言而言,整型数据类型包括short、int、long和long long四种以及它们的无符号整数形式。(当然char类型实际上也是整型的一种)
这些数据类型,都是以符合人类世界和自然世界的逻辑而出现的,说白了设计这些数据类型,是为了让人能更好得理解数据。但是计算机显然是不能直接识别这些数据类型的,因为计算机只能存储和处理二进制数据。
因此,符合我们人类思维的数据都要通过一定的转换才能被正确的存储到计算机中。
由于篇幅限制,这里仅讲解数据在计算机中的存储方式的一部分——。C语言的整型基本数据类型中的无符号类型非常简单,取值范围为不再赘述,我们仅讲解一下有符号数的编码存储。
要想理解数据的存储,首先要明白最基本的进制概念。
进制
,是人们规定的一种进位⽅法。 对于任何一种进制—X进制,就表示某一位置上的数运算时是逢X进一位。 常见的进制有:
- ,日常生活中应用最多的进制,逢十进一位,数字只能取值[0,9]之间,英文单词对应 。在C语言代码中规定,一个数字字面量不加任何限定的情况下,默认就是十进制的。
- ,计算机底层使用的数据存储方式,逢二进一位,数字只能取值[0,1]两个,英文单词对应 。在C语言代码中规定,一个数字如果以"0b"或"0B"开头(注意是零)时,它就是二进制的。
- ,十六进制的出现可以看成是二进制的补充,逢十六进一位,数字的取值除了十进制的0到9,还包括用A表示10,B表示11,依次推直到F表示15。英文单词对应 。
**在C语言代码中规定,一个数字如果以"0x"或"0X"开头(注意是零和字母X)时,它就是十六进制的。**二进制是计算机理解数据的方式,对于人来说,虽然不难理解,但是用二进制表示数实在太长了,十分不方便。而直接用十进制,又不利于理解计算机思维,所以就出现了十六进制,既简洁又能体现计算机思维。比如对于二进制的一个数:11111111,转换成十六进制就是:FF,恰好四位二进制对应一位十六进制数。
- ,介于十六进制和二进制之间,用途不是很广泛,了解一下即可。逢八进一位,数字只能取值[0,7]之间。英文单词对应 。在C语言代码中规定,一个数字如果以"0"(注意是零)开头时,它就是八进制的。
最后,进制之间还有一个非常重要的——转换问题,关于这一话题本小节就不进行扩展,大家可自行学习一下(如果你还不会的话)。
在这里,我推荐大家直接使用计算机自带的**计算器(程序员版)**去转换进制——手动转换太慢了,没必要!
| 十进制 | 二进制 | 八进制 | 十六进制 | 十进制 | 二进制 | 八进制 | 十六进制 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 10 | 1010 | 12 | A |
| 1 | 1 | 1 | 1 | 11 | 1011 | 13 | B |
| 2 | 10 | 2 | 2 | 12 | 1100 | 14 | C |
| 3 | 11 | 3 | 3 | 13 | 1101 | 15 | D |
| 4 | 100 | 4 | 4 | 14 | 1110 | 16 | E |
| 5 | 101 | 5 | 5 | 15 | 1111 | 17 | F |
| 6 | 110 | 6 | 6 | 16 | 10000 | 20 | 10 |
| 7 | 111 | 7 | 7 | ||||
| 8 | 1000 | 10 | 8 | ||||
| 9 | 1001 | 11 | 9 |
二进制
二进制是计算技术中广泛采用的一种数制。二进制数据是用0和1两个数码来表示的数。它的基数为2,进位规则是“逢二进一”,借位规则是“借一当二”。
十进制转化二进制的⽅法:用十进制数除以2,分别取余数和商数,商数为0的时候,将余数 倒着数就是转化后的结果。

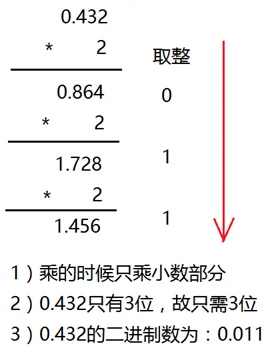
十进制的小数转换成二进制:小数部分和2相乘,取整数,不⾜1取0,,顺序看取整后的数就是转化后的结果。
八进制
八进制,Octal,缩写OCT或O,一种以8为基数的计数法,采用0,1,2,3,4,5,6,7八个数字,逢八进1。一些编程语⾔中常常以数字0开始表明该数字是八进制。
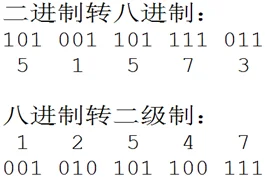
八进制的数和二进制数可以按位对应(),因此常应用在计算机语⾔中。
十进制转化八进制的方法:
用十进制数除以8,分别取余数和商数,商数为0的时候,将余数倒着数就是转化后的结果。

十六进制
十六进制(英文名称:Hexadecimal),同我们日常生活中的表示法不一样,它由0-9,A-F组成,。与10进制的对应关系是:0-9对应0-9,A-F对应10-15。
十六进制的数和二进制数可以按位对应(),因此常应用在计算机语⾔中。

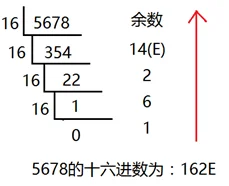
十进制转化十六进制的方法:
用十进制数除以16,分别取余数和商数,商数为0的时候,将余数倒着数就是转化后的结果。
如何表示相应进制数
| 十进制 | 以正常数字1-9开头,如123 |
|---|---|
| 八进制 | 以数字0开头,如0123 |
| 十六进制 | 以0x开头,如0x123 |
| 二进制 | C语⾔不能直接书写二进制数 |
#include <stdio.h>
#include <stdlib.h>
int main() {
int a = 123; //⼗进制⽅式赋值
int b = 0123; //⼋进制⽅式赋值, 以数字0开头
int c = 0xABC;//⼗六进制⽅式赋值
//如果在printf中输出一个⼗进制数那么用%d,⼋进制用%o,⼗六进制是%x
printf("⼗进制:%d\n", a);
printf("⼋进制:%o\n", b);//%o,为字母o,不是数字
printf("⼗六进制:%x\n", c);
return 0;
}程序输出:
十进制:123
八进制:123
十六进制:abc数据存储单位
当前的计算机系统使用的基本上是二进制系统,。
| 术语 | 含义 |
|---|---|
| bit(比特) | 一个二进制代表一位,一个位只能表示0或1两种状态。数据传输是习惯以“位” (bit)为单位。 |
| Byte(字节) | 一个字节为8个二进制,称为8位,。数据存储是习惯以“字节”(Byte)为单位。 |
| WORD(双字节) | 2个字节,16位 |
| DWORD | 两个WORD,4个字节,32位 |
| 1b | 1bit,1位 |
| 1B | 1Byte,1字节,8位 |
| 1k,1K | 1024 |
| 1M(1兆) | 1024k, 1024*1024 |
| 1G | 1024M |
| 1T | 1024G |
| 1Kb(千位) | 1024bit,1024位 |
| 1KB(千字 节) | 1024Byte,1024字节 |
| 1Mb(兆位) | 1024Kb = 1024 * 1024bit |
| 1MB(兆字 节) | 1024KB = 1024 * 1024Byte |
有符号整数
首先为了解释一下有符号整数的概念,我们需要知道以下前置知识点:
位(bit):计算机中数据存储的最小单位,每一位存储一个二进制数字,即0或1。
根据是否可以表示负数,机器数可以分为有符号数和无符号数。
- 有符号数可以表示正数、负数或零。
- 无符号数只能是非负的。
举个例子,比如我们可以规定计算机中存储一个数,最高位是符号位,0表示正数,1表示负数,然后再使用最高位以下的所有位来表示数值。这样我们就得到了一个有符号数的机器数表示形式:
这样,如果我们用8位来存储数+3,它的机器数就是00000011,而-3的机器数就是10000011。
这里的00000011和10000011都是机器数,而且是有符号整数。
真值和形式值:由于机器数有符号位,机器数的形式值(直接将二进制转换为十进制得到的值)并不等于它的真值。例如,机器数10000011的形式值是131,但它的真值是-3。
用以上设计来表示机器数看似合理,但问题很明显:
- 一个十进制的整数1,表示为二进制有符号数就是 (0000 0001)
- 一个十进制的整数-1,表示为二进制有符号数就是 (1000 0001)
将上述两个数相加,十进制相加很容易得到结果是0,但二进制有符号数相加却是(0000 0001)+(1000 0001)=(1000 0010) 这个数按照刚才设定的规则转换为十进制是-2,这显然是不对的。
因此,计算机中不能直接用这样的规则来进行数的存储、计算。那怎么办呢?
为了说清楚这个问题,就需要引入计算机中。
所以这里又可以回答一个问题:什么是原反补码——它们是计算机当中,有符号整数(机器数的一种)的三种表示形式。
原码
原码是有符号整数最简单的表示形式(就是我上面提到的规则),直接用最高位作为符号位,其余位都是数值位。如果是8位二进制:
[+1] = [0000 0001]原
[-1] = [1000 0001]原
原码是人脑最容易理解的机器数表示形式,无非就高位加一个符号位。但是我们上面已经说过了,如果计算机直接存储原码,进行计算将会出错,所以有符号整数还需要其它表示形式。
反码
但需要注意:- 正数的反码是其本身,不需要取反。
- 负数的反码是在其原码的基础上, 符号位不变,其余各个位取反。
举个例子,如果是8位的二进制数:
[+1] = [0000 0001]原 = [0000 0001]反
[-1] = [1000 0001]原 = [1111 1110]反
[-2] = [1000 0010]原 = [1111 1101]反
可以看出:如果一个反码表示的是一个负数,那么人脑就无法直观的看出它的数值了。当然这不重要,毕竟机器数也不是给你看的,计算机能看懂就行。
在原码的小节中,我们发现直接用原码计算会出错,那么如果直接用反码计算呢?试一试:
| 十进制运算 | 反码计算 | 反码计算结果(十进制) |
|---|---|---|
| 1 +(-1)= 0 | [0000 0001]反 + [1111 1110]反 = [1111 1111]反 = [1000 0000]原 | -0 |
| 1 +(-2)= -1 | [0000 0001]反 + [1111 1101]反 = [1111 1110]反 = [1000 0001]原 | -1 |
| -1 +(2)= 1 | [1111 1110]反 + [0000 0010]反 = [0000 0000]反 = [0000 0000]原 | 0(溢出归0) |
从上表可以看出,如果用反码直接进行计算,虽然有所改善,但仍然有问题,所以计算机中的运算也不能直接用反码。
这样就出现了补码的概念。
补码
补码是在反码的基础上得出的,它是这么规定的:
- 正数的补码是其本身,不需要做改变。
- 负数的补码等于反码加上1。
举个例子,如果是8位的二进制数:
[+1] = [0000 0001]原 = [0000 0001]反 = [0000 0001]补
[-1] = [1000 0001]原 = [1111 1110]反 = [1111 1111]补
[-2] = [1000 0010]原 = [1111 1101]反 = [1111 1110]补
可以看到,补码已经完全和真值没有什么二进制数值上的关系了,但是用补码进行计算,能够解决上面遇到的问题吗?
| 十进制运算 | 补码计算 | 补码计算结果(十进制) |
|---|---|---|
| 1 +(-1)= 0 | [0000 0001]补 + [1111 1111]补 = [0000 0000]补 = [0000 0000]原 | 0(溢出位舍弃) |
| 1 +(-2)= -1 | [0000 0001]补 + [1111 1110]补 = [1111 1111]补 = [1111 1110]反 = [1000 0001]原 | -1 |
| -1 +(2)= 1 | [1111 1111]补 + [0000 0010]补 = [0000 0001]补 = [0000 0001]原 | 1(溢出位舍弃) |
从上表可以看出,如果使用补码进行计算,就可以正常的进行加法算术运算了。
当然,有人可能会觉得我举的例子太少且比较简单,缺少代表性,那么你完全可以自己试一试。
那么至此,我们要总结两个非常重要的结论:
- 正数的原码反码补码是一致的,负数的反码是原码除符号位取反,补码是反码+1。
为什么使用补码?
上面我们已经大致解释了这个问题,实际上主要就是以下两点原因:
试想一下,如果使用补码存储整数,那么加减法都能够转换成加法进行,这样CPU就只需要设计加法器,而不需要专门设计减法器。结构的简化,不仅有利于实现,更能提升实际的运算效率。
现在,你已经懂得了原反补码是什么,以及它们分别如何得到,也知道了为什么要用补码。也就是说,如果只谈使用,对于有符号整数的理解,到此为止就可以了。
但如果你想知道其设计原理,可以继续往下看。
补码的设计原理
「 」
为什么原码和反码不行?
上面已经讲的很清楚了,使用原码和反码直接进行加法运算,由于错误的溢出和进位等,运算结果大概率是不正确的。所以我们需要另寻他法,这就是补码。
接下来,浅谈一下补码的原理。
补码为什么叫补码?
要谈补码的原理,首先就要知道补码这个名字的由来。
原码比较好理解,真值加上符号位就是原码,原码基本就还是原先的值。反码是原码取反所以叫反码。
那么补码呢?为什么叫补码?这是因为补码的提出依赖于 的概念。
什么是补数?
在我们日常的生活和学习中,补数是一个常见而重要的概念:
一个时钟,当前指示的时间为六点,想要它指向三点,可以按顺时针方向将时针转九格,也可以逆时针方向转动三格,结果是一致的。
一天是24小时,但时钟上只有12个数,时钟是不会显示超出12时的时间的,比如显示15点,实际上指针指向的位置是3。
即对时钟而言,超出12点的时间就存在概念,都必须减去12这个数,才是指针真实指向的位置。
想象一下,在时钟这个问题上,,我们将顺时针转向定义为做加法,逆时针转向定义为做减法。在这个案例中,就可以认为 -3 与 +9 是等价的。
那么我们在数学上,将本案例中的12定义成为模,写作(mod 12),而称 +9 是 -3 以 12 为模的补数记为:-3 ≡ +9(mod 12)
以此类,还有:
-4 ≡ +8(mod 12)
-5 ≡ +7(mod 12)
【以上截改自《计算机组成原理·第二版》唐朔飞著p221】
总结:
- 比如在时钟的运算中,模就是12,因为在时钟的运算里不可能超过这个正数。
- 补数是与模紧密相关的另一个概念,在同一个模系统的前提下,两个互为补数的数是等价的。
看到这里,你可能很疑惑,好好地为什么搞一个"补数"出来呢?
实际上,补数的意义是:在一个计算体系(模)中,补数的出现可以统一加法和减法为一种算法。
-4 ≡ +8(mod 12)也就是说,在时钟的体系中,-4 和 +8 是一个数,减去4就等于加上8,于是就能将加减法统一成加法或者减法。
明白这个道理后,那么把补数套用到计算机的机器数计算中,是不是也能够统一加减法呢?答案是肯定的,这就是补码的由来。
那么,看到这里你就已经明白了,,但是具体到底是怎么得出来的呢?
补码为什么可以统一加减法
数学意义上的加法和减法是有本质区别的,一个是让数变大,一个是让数变小,所以常规情况下加减法是不可能统一的,想要统一必须就要在特殊的场景中。
这时,我们就需要将眼光重新投到时钟上:
数轴在正常情况下是一条无限的直线,加减法的结果在数轴上的方向就不可能一致,那么:
于是,我们假设有一个圆形的数轴,取值范围是0~999,且规定999 + 1 = 0 而不是 1000。
这个1000就是这个数轴计算体系中的mod(模),那么减去200就可以变成加上800,减去300就可以变成加上700,只要减去的数和加上的数的绝对值和是模(1000),就可以统一加减法为加法。
计算过程如下:
700 - 327 = 373
327是"原码",计算补码:
1000 - 327 = 673
700 - 327 = 700 + 673 = 1373
因为我们已经规定了数轴是圆形而不是直线了,所以1373已经数值"溢出"了,1373真正表示的数应该是:
1373 - 1000 = 373
所以673是-327的"补码",运算结果也没问题。对上了!
上面的运算是基于十进制的,那么放在二进制里是否可行呢?
举一个简单例子,对于C语言中的short基本数据类型而言,一般而言它的取值范围是[-32768, 32767]
那么请问这个取值区间是一个数轴?还是一个圆环呢?
以上,就是补码能够统一加减法的原因。
补码设计体系的由来
假如计算机中存储了一个8位二进制数**(先看无符号数)**,最大取值位1111 1111,加上 1 就会出现数值溢出结果是0。
于是我们取mod为1 0000 0000,然后计算补码,那么整个8位二进制的减法,我们只需要求出补码就可以全部转换为加法了。
我们随便找一个数1011 0010去求补码,仍然按照上面的方法计算:
1 0000 0000 - 1011 0010 = 0100 1110
上述过程看起来没问题,但是不要忘记了我们的初衷:
所以计算机在算补码时,不能通过减法去算,那怎么算?继续看:
1 0000 0000 可以看成 1111 1111 加 1
所以:
1 0000 0000 - 1011 0010 = 1111 1111 + 1 - 1011 0010 = + 1 = 0100 1101 + 1 = 0100 1110
看到这里,你可能又疑惑了:不是说好了干掉减法,但还是有啊。
不要着急,在计算的步骤我们使用的 实际上并不是一个普通的减法。
观察一下减数 1011 0010 和结果 0100 1101 有什么关系?是不是恰好每位都取反?
对了,这种特殊的减法就是计算机中的 ,得到的结果就是。
所以在计算补码的过程中,也去掉了减法:
好了,看到这里,你已经知道了教科书里为什么教我们原码取反加1就是补码了吧?
到此为止,我们通过这种手段,统一了计算机中的二进制运算的加减法。
那么一切就万事大吉了吗?当然没有,继续看:
为了简单起见,以十进制为例,二进制是一样的,仍以mod = 1000为例。计算结果如果是负数的话,就有麻烦了:
300 - 700 = -400
-700相对于mod 1000的"补码"是300
于是300 - 700 变成了 300 + 300 = 600
这样看结果似乎不对了,但仔细一想 -400 的"补码" 实际上就是 600,它们是等价的,看来结果是对的,只是结果都是需要用补码等价换算一下罢了。
但一个表达式中的数如果还不能统一形式,实在太难以理解了,如果人都会被难住,何况计算机呢?
所以,既然结果中出现了需要等价换算的补码,那么我们干脆做出规定:
做出这种规定后,那么问题就又来了:
在上面这个案例中,我们只把减数变成了补码的形式表示,用于消除减法。被减数仍然是一个“原码”,现在要求表达式全部用“补码”表示,于是就需要做出换算,如下:
300 - 700 = -700补 + 300补 = -400补 = 600
上述计算式就太离谱了啊,出错的原因也很简单:补码本身就是为了消除减法而生的,将负数变成正数。而如果这个数本身就是一个正数,补码应该和原码一样才对。
所以我们又必须规定:
于是我们就有了以下两个消除减法,统一成加法的运算方式:
300 - 700 = 300补 + 300补 = = -400
我们可以测试一个被减数是负数的例子,比如:
-300 - 300 = 700补 + 700补 = 1400补 = 400补 = -600
其实你高兴得太早了,观察一下上面两个表达式的结果补码(标红色的部位)600 和 400,请问:
你怎么知道补码 600 的原码是 -400 而不是正数600呢?补码400的原码是-600而不是正数400呢?
换句话说,-600的补码一定是400(因为补码就是要将负数变成正数),而400的补码就不一定是-600了(正数的补码可能就是它本身),还有可能就是400。
新的问题来了:
路是自己选的,那么多困难都解决了,这次也要解决问题,于是迎难而上吧。
出现这个问题的根源在于,缺少一种标志告诉我们结果的正负,如果能够像数字前带正负号一样,明确指示出数的正负不就可以了?
结合计算机的二进制表示,我们能不能在计算机存储数时,用1/0来表示数值的正负呢?总要试一试吧,于是就出现了有符号数,我们规定:
有了符号位后,我们就可以通过结果的最高位判断:如果最高位是0,就表示正数,原码就是补码本身。如果最高位是1,就表示负数,原码就要做相应运算得到。
理想是很好的,但是能不能这么做还需要做测试,在具体测试之前,我们先梳理一下思路:
我们的目的是想通过加法来表示减法,从而统一加减法。
我们发明了一个叫做补码的东西,还规定以后所有的计算都用补码形式进行,正数的补码是它本身,负数的补码是取反 + 1。
但是现在这个东西产生了岐义,为了区分正负补码,我们决定:
现在最后需要做的就是测试了,首先我们要明确的是:
并且我们之所以使用符号位,目的是为了区分正负数的补码,所以原码和补码的符号位必须是一致的(不然就白瞎了)。
所以我们必须规定:
现在我们要规范一下原码、反码和补码的计算规则:
在固定存储位长得基础上,可以按照以下规则计算:
- 原码
- 其有效数字是该数绝对值的二进制表示。
- 最高位是符号位,如果是负数符号位是1,正数符号位是0。
- 有效数值和最高位之间如果有空隙,加0。
- 最高位是符号位,其它位都是数值位。
- 反码
- 正数的反码与原码相同。
- 负数的反码是对其原码逐位取反,但符号位除外。
- 补码
- 正数的补码与原码相同。
- 负数的补码是在其反码的基础上再加1。
注意:
- 只有原码的最高位是符号位,其它位是数值位。反码和补码的最高位能仍然表示正负,但后面的位和数值就没啥关系的。
- 计算机内部是用补码存储数值的,只要补码没有超出位数就可以了。
一个比较典型的例子就是:-128
我们都知道一个byte字节型所表示的整数的取值范围是[-128,127],所以-128是可以用8位存储的。
-128的原码是:1 1000 0000(超出位数,表示不了)
-128的反码是:1 0111 1111(超出位数,表示不了)
但是这并不妨碍补码:10111 1111 + 1 = 11000 0000 (最高位溢出舍去)= 1000 0000
所以你看,-128的补码是在8位范围内的,最高位1表示负数,后面都是0,但并不意味着它表示"负0",后面不是数值位。
总之,我们做了这么多规定,那么结果还正确吗?需要验证一番,可以分四种情况:
- 正数 + 正数 = 正数
- 正数 - 正数 = 正数
- 正数 - 正数 = 负数
- 负数 - 正数 = 负数
限于篇幅(我懒,这里就不放验证了),大家感兴趣可以去试一试。
总结
最后再总结一下吧:
- 我们搞这一套都是为了消除减法,简化CPU结构/指令集,提升计算机运行效率。
- 计算机中的所有机器数都以补码的形式存储,最高位不再是数值位,而是符号位,符号位用 0 表示正数,1表示负数。
- 正数的补码是它自身,负数的补码为绝对值取反加一(不带符号位取反)
- 计算机中只有加法,没有减法。减去一个数可以转换成加上减数的补码。
以上,本节的主体内容就写完了。当然你还可以想一想其中的一些细节问题:
我在这里,就不再给出具体的解释了,大家可以自己想一想,查一查(如果你感兴趣的话)
写完这东西还是比较有感慨的,
当然还有一个映像深刻的道理就是:
如果想要在一套已存在的体系上(生活中的加减法)搞一套新体系(计算机中的加减法),首先是需要思维方式上的创新,其次在设计之初它一定是漏洞百出的,需要反复修改最终才能合理(迭代)。