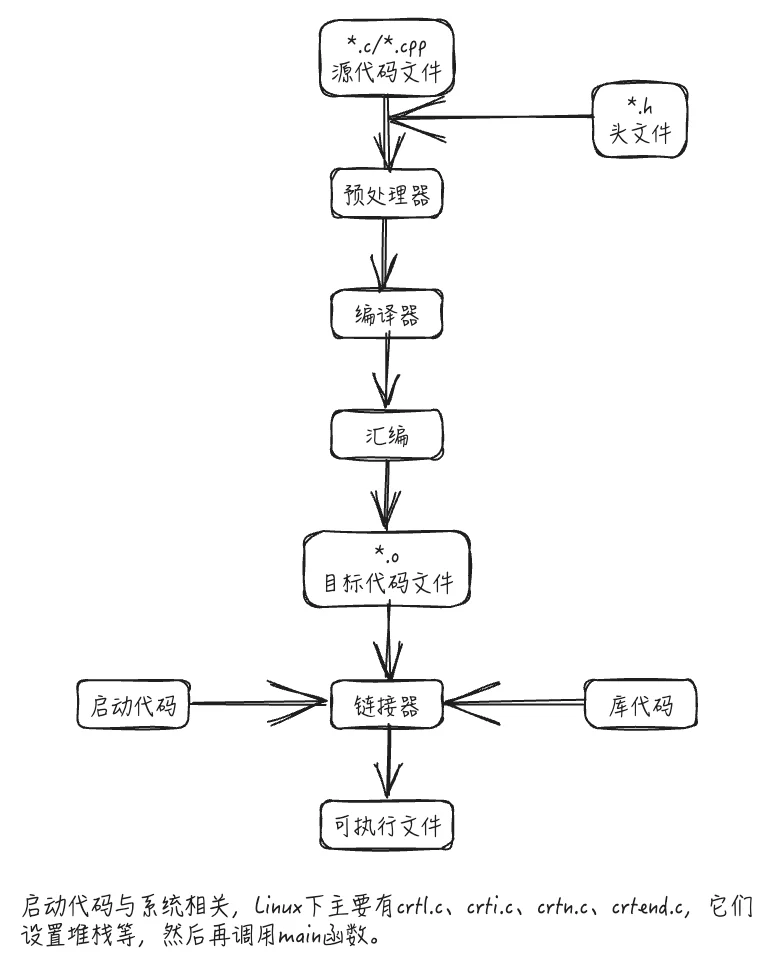
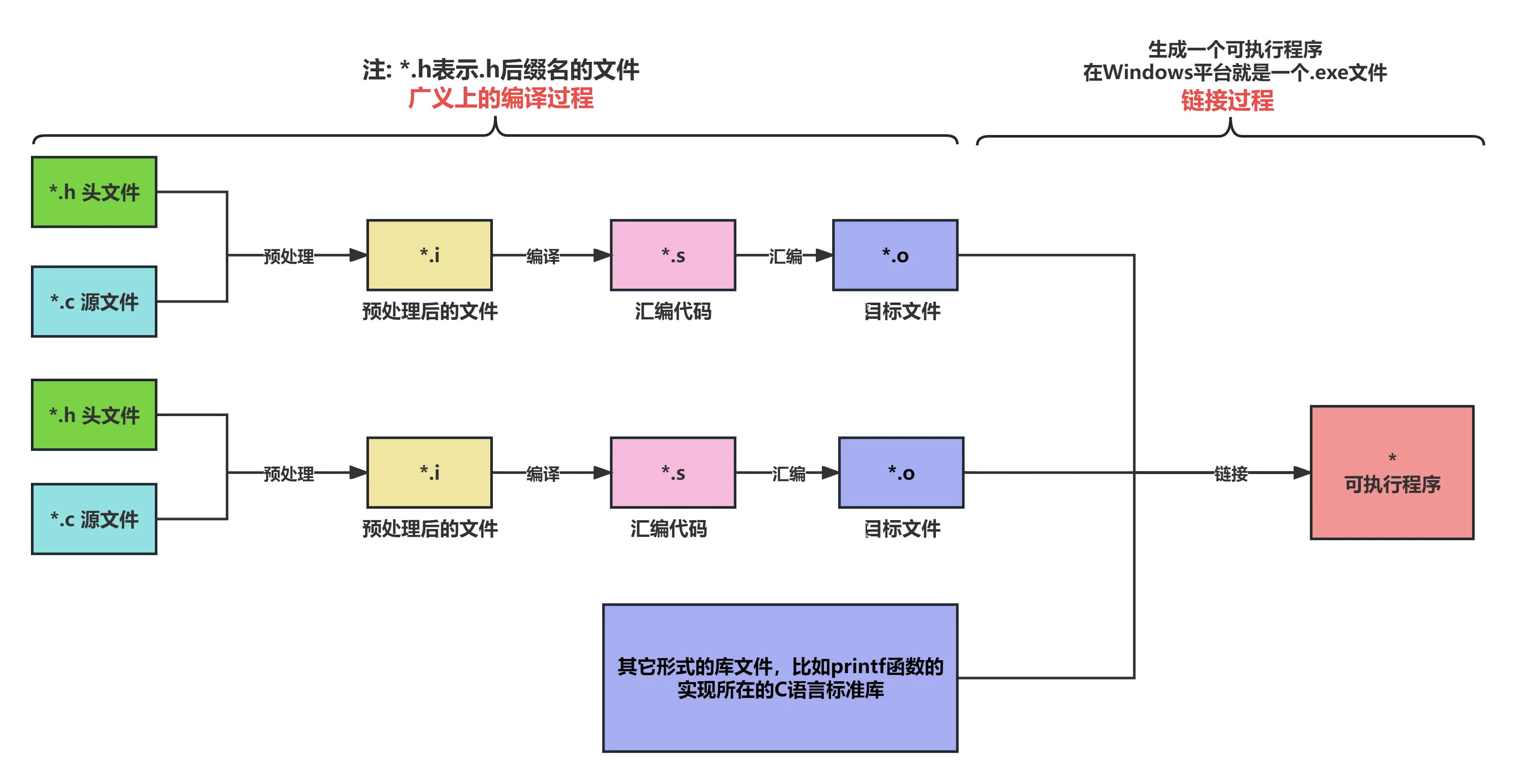
C/C++程序编译过程
C代码编译成可执行程序经过4步
- 预处理:宏定义展开、头文件展开、条件编译等,同时将代码中的注释删除,这里并不会检查语法
- 编译:检查语法,将预处理后文件编译生成汇编文件
- 汇编:将汇编文件生成目标文件(二进制文件)
- 链接:C语⾔写的程序是需要依赖各种库的,所以编译之后还需要把库链接到最终的可执行程序中去
广义编译的过程
从广义上来说,一个C语言源文件编译的过程可以分为以下三个小步骤:
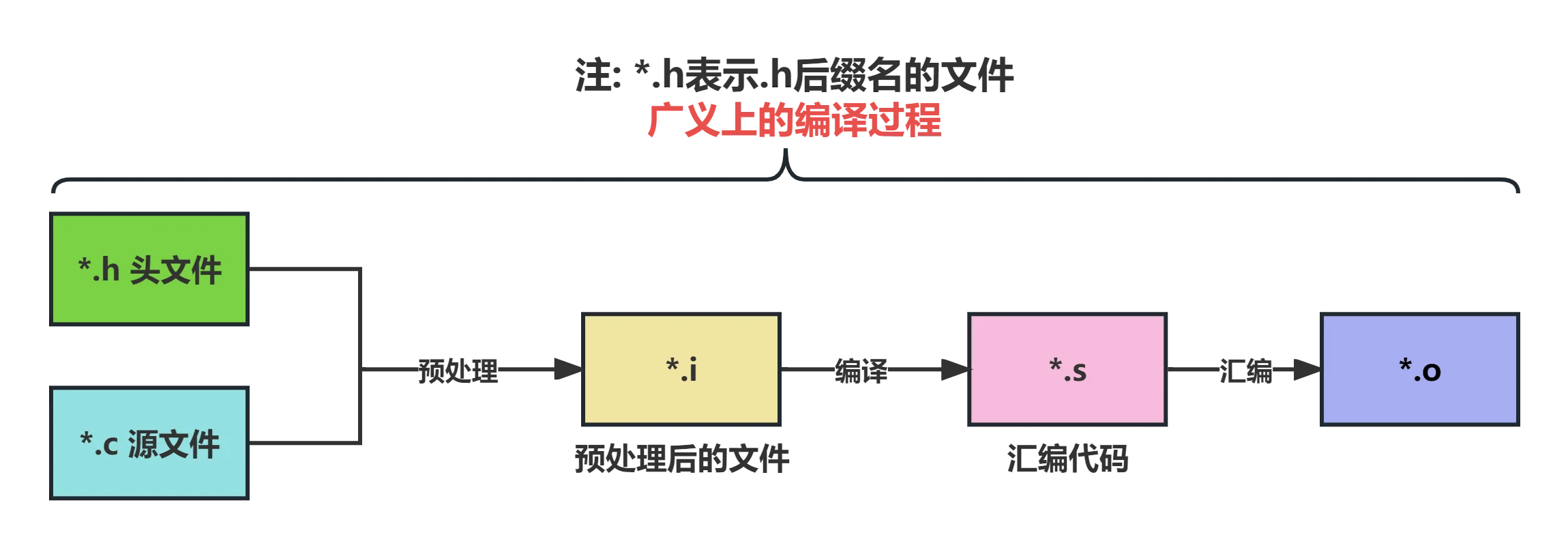
- 预处理:把一个
.c文件处理成.i文件。 - 编译:把
.i文件进一步处理成.s文件。狭义上来说,编译就是指编译器处理.i文件生成.s文件的过程。 - 汇编:把
.s文件最终处理得到.o文件。
注意事项
汇编过程结束后,实际还需要一个链接过程,才能得到一个可执行文件。
预处理过程
预处理是C语言源文件编译处理的第一步,由预处理器来完成。那么预处理器到底干啥呢?
答:预处理是在程序源代码被编译之前,由预处理器(Preprocessor)对程序源代码进行的处理。 这个过程并不对程序的源代码语法进行解析,但它会把源代码分割或处理成为特定的符号为下一步的编译做准备工作。
预处理是编译器的一个重要组成部分,主要负责词法分析和语法分析之前的文本转换工作。
预处理器通常包含以下几个功能
- 宏定义(Macro Definition) :允许开发者定义符号或表达式,在代码中使用这些符号代替较长表达式或重复代码片段。例如,
#define PI 3.14159将PI用于程序中需要圆周率的地方。 - 宏展开(Macro Expansion):将程序中所有宏替换为其定义内容。(注意:避免与文本替换重复描述)
- 条件编译(Conditional Compilation):通过指令控制代码块编译与否,编写可移植性更好的代码。例如,使用
#ifdef,#ifndef,#endif等关键字实现条件编译。 - 文件包含(File Inclusion):允许程序引入其他文件代码,提高代码重用性和模块化程度。例如,
#include <stdio.h>插入标准输入输出库头文件内容。 - 行控制(Line Control):改变源代码行编号,有助于调试和错误追踪。例如,
#line 100 "newfile"将后续行号标记为来自 "newfile" 的第 100 行。 - 删除注释:移除源代码中所有 C 风格和 C++ 风格注释。
- 文本替换:将程序中特定标记(如
#define定义的宏)替换为相应文本。(注意:与宏展开不同,这里更强调标记替换为文本的过程) - 条件编译:根据特定条件(如
#ifdef,#ifndef等)决定是否包含某些代码段。
预处理阶段结束后,编译器将接收一个经过宏展开、条件编译和文件包含处理的源代码副本。
在前面我们已经简单讲解过了hello world程序,也知道了一条预处理指令:
#include <stdio.h>实际上,在C语言代码中,以 # 开头的指令就是预处理指令。预处理指令有多种形式,在今天我们先学习两种最常见的形式:
#include:用于包含头文件。#define:用于定义宏或者常量。
下列讲解一下这两种预处理指令,分别完成什么操作。
注释的处理
我们都知道注释是不参与编译更不会影响代码的执行的。而实际上,注释的处理是在预处理阶段完成的:
那么从预处理器过程开始,后续的所有过程注释都不会参与了。
#include包含头文件
include具有包含的意思。预处理指令 #include 用于包含头文件。
头文件
即以 .h 为后缀的文件,头文件一般用于声明函数、结构体类型、变量等。(关于头文件的详细使用,我们后面再讲)
简单来说,你可以认为该预处理指令的作用就是:
比如预处理一个基础的hello world程序
#include <stdio.h>
int main() {
printf("Hello, world!\n");
return 0;
}在命令行中执行预处理过程的指令:
gcc -E hello.c -o hello.i预处理完成后打开得到的 hello.i 文件,和源文件 hello.c 文件进行对比。你会发现 hello.i 文件中 #include <stdio.h> 这一句不见了!并且 int main() { 这一行的上方多出了很多内容!!
其实预处理器会先找到stdio.h头文件,然后将其内容处理后复制到#include <stdio.h>的位置。大体上,可以把 #include 当成一次文本复制的过程。这样,编译器在编译代码时就可以访问stdio.h中定义的所有函数和变量。
就是由于预处理机制,printf函数才能够被我们自己的程序去调用。
了解/扩展
包含头文件的预处理过程并不仅仅是一个简单的文本替换或复制粘贴操作。
预处理器会执行一系列任务,其中包括条件编译、宏替换等,这会影响头文件内容如何整合到源文件中。
所以,预处理后的 .i 文件可能不会简单地是原 .c 文件和 .h 文件内容的组合,而是这些文件在经过预处理器处理后的结果。但大体上,预处理后的结果文件会包含两个文本的原本内容。
#define定义符号常量
预处理指令 #define 的第一个常见作用,是给字面常量起个名字,使得程序员可以更方便得在程序中使用一个字面常量。
这种使用 #define 指令定义的常量,被称之为。
例如以下程序
#include <stdio.h>
#define PI 3.14f
#define N 6
int main(void) {
printf("圆的半径是2,周长是:%f\n", PI * 2 * 2);
printf("N * 2 + 2 = %d\n", N * 2 + 2);
return 0;
}最终程序的输出结果是:
圆的半径是2,周长是:12.560000
N * 2 + 2 = 14通过查看 .i 的预处理后的文件:该指令实际上就是把代码中的符号常量替换成实际的字面常量,比如上述两行printf代码预处理后就会变成:
printf("圆的半径是2,周长是:%f\n", 3.14f * 2 * 2);
printf("N * 2 + 2 = %d\n", 6 * 2 + 2);为什么非要给字面常量起个名字?直接用不好吗?
主要有两个好处:
- 提高代码的可读性。使用名称而非直接用字面常量可以使代码更易于理解。
- 易于维护。如果某个常量需要更改,你只需要在
#define指令中更改它,而不需要遍历整个代码库去替换。 - 。编程领域把代码中直接出现的、意义不明的一个字面常量称为"魔法数字、魔数",避免魔数在代码中直接出现是一个好的编程习惯。建议使用有意义的符号常量名字,来提高代码的可读性和可维护性。
注意事项
使用 #define 定义符号常量,应注意:
- 符号常量的本质是文本替换,它的定义和使用,没有任何数据类型、取值范围等的限制。这既是优点带来了灵活性,但也会带来一定的安全隐患。
- 定义时,添加必要的符号后缀,比如float类型的字面常量可以明确加"f"后缀。这有利于增加代码可读性,以及为编译器提供更多信息。
#define定义函数宏
在C语言中,是一种由处理的代码生成机制。简单地说,宏可以看作是一种用于在编译前、预处理阶段自动替换代码片段的方式。在C语言中,#define 指令通常用于创建宏。
上面讲的通过 #define 定义符号常量,也是定义了一个宏,你可以叫常量宏或者宏常量。
当然,这里要讲C语言中的函数宏,函数宏的定义会稍微复杂一点。
一个简单宏函数的应用如下
/**
* 最简单的的宏函数
*/
#include <stdio.h>
// 定义了一个函数宏,用于求长方形的周长
#define RECTANGLE_PERIMETER(length, width) (((length) + (width)) * 2)
// 定义了一个函数宏,用于求两个数的平方差
#define SQUARE_DIFF(x, y) ((x) * (x) - (y) * (y))
int main(void) {
// 调用函数宏
printf("长和宽分别是10和5的长方形,其周长是:%d\n",
RECTANGLE_PERIMETER(10, 5));
printf("3和2的平方差是:%d\n", SQUARE_DIFF(3, 2));
return 0;
}很显然,运行结果是:
长和宽分别是10和5的长方形,其周长是:30
3和2的平方差是:5函数宏的本质仍然是文本替换,但会复杂一点,相当于把调用宏函数时的参数传入公式直接计算,比如上述两行printf代码预处理后就会变成:
printf("长和宽分别是10和5的长方形,其周长是:%d\n", (((10) + (5)) * 2));
printf("3和2的平方差是:%d\n", ((3) * (3) - (2) * (2)));宏函数进阶一点的使用方法就是 具有多条语句的宏函数。
一个具有判断字符是否是英文字符功能宏函数的实例如下
/**
* 带语句的宏函数
*/
#include <stdio.h>
// 定义一个用于判断字符是否是英文字符的宏函数
#define ISChar(useKey) \
if (useKey >= 'A' && useKey <= 'Z') { \
printf("大写字母\n"); \
} else if (useKey >= 'a' && useKey <= 'z') { \
printf("小写字母\n"); \
} else { \
printf("不是字母\n"); \
}
int main(void) {
char s = 's';
char S = 'S';
char other = '@';
ISChar(s);
ISChar(S);
ISChar(other);
return 0;
}程序输出:
小写字母
大写字母
不是字母在使用具有多条语句的宏函数时也要注意它可能引发的一些问题,比如会影响原有代码并可能造成程序错误
例如以下示例程序
/**
* 为了避免宏函数与代码形成错误的解析,多条语句的宏函数可以使用 do_while(0)
*/
#include <stdio.h>
// 问题复现
#define TEST01 \
int result = 10; \
printf("result = %d\n", result);
// 使用 do_while(0) 解决问题
#define TEST02 \
do { \
int result = 10; \
printf("result = %d\n", result); \
} while (0)
int main(void) {
int result = 0;
// TEST01;
TEST02;
return 0;
}编译时就会有以下报错
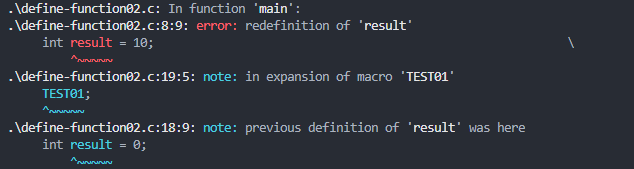
此时,我们把 TEST01 的宏函数调用注释起来,使用 TEST02 的宏函数调用即可解决问题。
然后编译并执行就会得到
result = 10函数宏的优点
使用函数宏在C语言中能带来一些好处:
- 代码复用,简化代码,提高可读性啥。
- 提升性能。函数宏虽然叫函数,但本质是文本替换,而且是预处理阶段就完成替换,这完全不会消耗运行时性能。
- 灵活。既然本质是文本替换,那么带使用函数宏时给不同类型的参数都是可以的。
注意事项
使用函数宏时,主要注意以下几点:
- 函数宏调用的本质是在预处理阶段的文本替换,要切记函数宏和函数完全不是一回事。(这一点在后续讲函数后,可以加深理解)
- 这样命名的宏
- 函数宏适用于替换程序中一些简短的、但反复执行的函数。
函数宏定义时"()"的运用
我们先给出三条结论:
- 定义函数宏的表达式内部在有必要时要用小括号括起来,以确保函数宏内部的运算的顺序是正确的。
下面逐一举例说明为什么要这么做。
比如宏函数定义:
#define RECTANGLE_PERIMETER(length, width) (((length) + (width)) * 2)((length + width) * 2)当中的(length + width)小括号就是必须要添加的,不添加宏内部的运算顺序就不正确了。
第二条要求宏函数表达式的每一个参数都要用小括号括起来,这是为什么呢?
假如宏函数如下:
#define SQUARE_DIFF(x, y) x * x - y * y // 这个宏定义是错误的,这里只是演示参考下列代码:
printf("%d\n", SQUARE_DIFF(1 + 2, 1 + 1));结果是表达式"32 - 22"的值吗?
显然不是,这是因为预处理替换的结果是:
printf("%d\n", (1 + 2 * 1 + 2) - (1 + 1 * 1 + 1));计算出来的结果是: (5) - (3) = 2
第三条要求宏函数的整个表达式要用小括号括起来,原因也类似。比如下列宏函数定义:
#define SQUARE_DIFF(x, y) (x) * (x) - (y) * (y) // 这个宏定义是错误的,这里只是演示假如按照下列方式调用宏:
printf("%d\n", SQUARE_DIFF(3, 2) * 10);结果是表达式"(32 - 22) * 10"吗?
显然也不是,这是因为预处理替换的结果是:
printf("%d\n", ((3) * (3)) - ((2) * (2)) * 10);计算出来的结果是:9 - 4 * 10 = 9 - 40 = -31
总之,由于函数宏调用的本质是文本替换,本身不涉及任何计算规则优先级,所以以上三点加括号的原则是一定要注意遵守的!!
查看预处理.i文件
在VS当中,默认情况下,点击按钮启动程序,并不会保留预处理后的 .i 文件。为了能够看到这个 .i 文件,我们需要让VS的编译过程停留在预处理阶段。可以按照以下步骤设置:
右键点击项目 --> 属性 --> C/C++ --> 预处理器 --> 预处理到文件 --> 设置从否改成是。效果图如下:
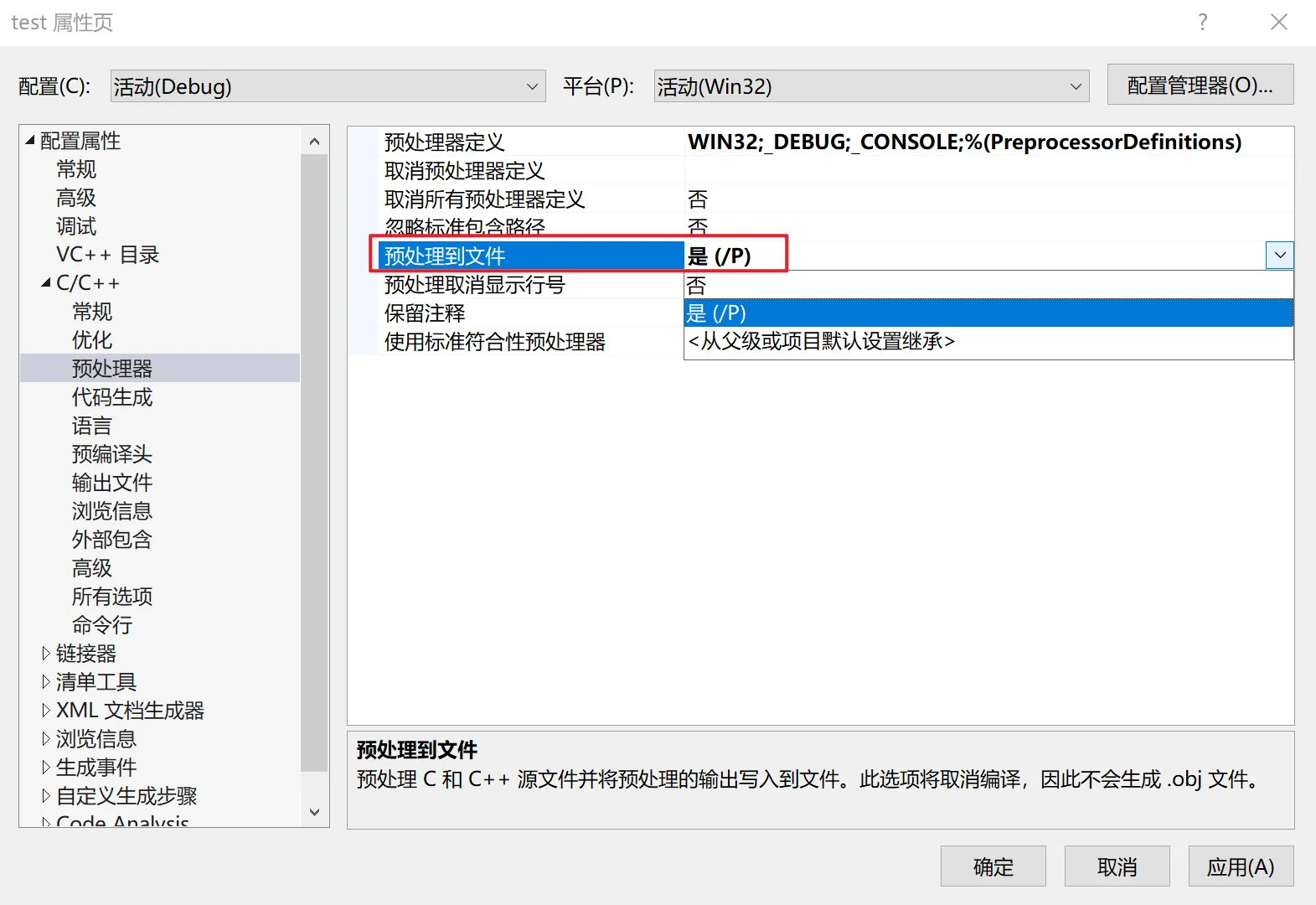
完成以上设置后,再重新点击按钮启动程序,打开项目的本地文件,在Debug文件夹下就可以找到该 .i 文件。(当然项目此时是无法运行成功的。)
Tips
如果项目仍成功运行,可以打开项目的本地文件删除Debug这个文件夹,或者点击"VS主界面 --> 生成 --> 重新生成解决方案"即可。
预处理过程总结
预处理过程主要就两个作用:
- 执行预处理指令,展开宏(进行处理文本替换)。
- 丢弃代码中的注释。
通俗的说,你可以认为预处理后得到的.i文件是一个无预处理指令,无注释以及无宏定义的源代码文件。
预处理过程得到的仍然是一个源代码文件,这个文件的内容人肉眼是完全可以看懂的。
最后再谈几个细节问题:
预处理指令包含字符
#,还存在一些单词如define、include等,需要注意的是:#不是C语言标识符中允许出现的字符,所以不要把预处理指令理解成标识符。define、include等也不属于关键字,不要理解成关键字。
预处理指令也不要理解成语句,不要在预处理指令的末尾加
;,也不要使用=字符。诸如下列预处理指令的写法都是不正确的:c#include <stdio.h>; // 末尾不能加分号, 预处理指令不是语句 #define MESSAGE = "Happy new year!" // 宏常量定义不需要使用等号以上
编译过程(狭义)
在预处理完成后,编译器(Compiler)就开始处理预处理生成的 .i 文件了,这个过程就被称为为(狭义上的)编译。那么相对的,广义上的编译就是把源代码文件处理生成可执行程序文件的过程。
编译器在这个过程,主要完成以下工作:
- 进行词法分析、语法分析、类型检查等操作。
- 编译器还在此阶段对代码进行各种优化,以提高效率,减少最终生成代码的大小。
- 最终,将预处理后的源代码转换成汇编语言。也就是将
.i文件转换成.s文件。
一个汇编代码的演示
#include <stdio.h>
int main(void){
printf("hello world! \n");
return 0;
}其可能生成的汇编代码如下,因为汇编语言的格式与硬件的关联较大,使用相同的源文件和不同厂家的硬件生成的汇编代码可能是不同的。
.LC0:
.string "hello world! "
main:
push rbp
mov rbp, rsp
mov edi, OFFSET FLAT:.LC0
call puts
mov eax, 0
pop rbp
ret值得注意的是,C语言最初是为了替代更低级的B语言和汇编语言而设计的。因此,C语言源代码被编译成汇编代码是完全符合其设计初衷的。
生成汇编代码的过程中,编译器还会自动对代码进行优化,但对于一般的C程序员而言,编译器或汇编语言都不是必须掌握的知识点。
汇编过程
编译器完成编译后,会将这些汇编指令转换为目标代码(机器代码),生成了一个.o(或者.obj)文件。从这一步生成的文件开始,文件中的内容就不是程序员能够肉眼看懂的文本代码了,而是二进制代码指令。
.o 文件还不是一个能直接执行的文件,因为它可能依赖于其他外部代码,比如在代码中调用printf函数。
预处理阶段不是已经包含头文件,为什么还说要依赖外部代码?
头文件中往往只有函数的声明,包含头文件大概只意味着预处理器告诉编译器:
“这里有一个函数叫做printf,它大概是这个鬼样子,后续的代码中会用到这个函数。你先知道有这么个玩意,别给我报错,至于这个函数到底是干啥的,做什么的,你先别管。”
所以汇编后的代码,还需要经历一个链接的步骤,来依赖外部代码才能够真正的运行。
比如有以下程序
#include "sayHello.h"
int main(void) {
sayHello();
return 0;
}#ifndef __SAYHELLO_H__
#define __SAYHELLO_H__
void sayHello(void);
#endif#include "sayHello.h"
#include <stdio.h>
void sayHello(void) {
printf("Hello");
}只包含头文件进行编译,有以下命令
gcc -E main.c -o main.i
gcc -S main.i -o main.s
gcc -c main.s -o main.o
gcc main.o -o maingcc分步编译的前几步都能正常进行,但是要将 .o 文件生成可执行文件的时间将会产生以下报错信息
main.o:main.c:(.text+0xe): undefined reference to `sayHello'
collect2.exe: error: ld returned 1 exit status此时,将外部代码也编译成 .o 文件,然后一起进行编译将能够编译成功,并正常运行编译后的可执行程序
gcc -E sayHello.c -o sayHello.i
gcc -S sayHello.i -o sayHello.s
gcc -c sayHello.s -o sayHello.o
gcc main.o sayHello.o -o main
./main
Hello链接的过程
在链接阶段,链接器(Linker)会把项目中,经过汇编过程生成的多个(至少有1个).o文件和程序所需要的其它附加代码整合在一起,生成最终的可执行程序。
比如你在代码中调用了标准库函数,那么链接器会将库中的代码包含到最终的可执行文件中。
链接器的主要工作包括以下几个步骤
- 符号解析:链接器会遍历所有
.o文件,找出其中的符号(函数、变量等),并将它们与程序中的符号进行匹配。如果符号在.o文件中找不到,链接器会报告错误。 - 地址分配:链接器会为每个符号分配内存地址。这通常是通过在内存中分配一块连续的区域来实现的。
- 符号重定位:链接器会根据符号的地址,将
.o文件中的代码和数据复制到最终的可执行文件中。如果.o文件中的代码或数据引用了其他.o文件中的符号,链接器会将这些引用的符号的地址更新为正确的地址。 - 库文件处理:链接器还会处理程序所依赖的库文件。库文件是预先编译好的代码,包含了许多函数和数据,可以被程序直接使用。链接器会将库文件中的代码和数据复制到最终的可执行文件中。
链接过程的示例
比如有以下程序
extern int gi;
int add(int, int);
int gi1 = 10;
static int gi2 = 20;
int main(void) {
int a = 3;
int b = 5;
int ret = add(a, b);
int c = 4;
return 0;
}int gi = 30;
int add(int lhs, int rhs){
return lhs + rhs;
}把它们分别编译成 .o 文件,然后进行链接,分别查看各自的 .o 文件和链接后的可执行文件 的符号表
gcc -c *.c
ld *.o
# 查看符号表
objdump -t xxx.o
# 或者使用readelf命令
readelf -s xxx.o
# 或者使用nm命令
nm xxx.omain.o: 文件格式 elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 main.c
0000000000000000 l d .text 0000000000000000 .text
0000000000000004 l O .data 0000000000000004 gi2
0000000000000000 g O .data 0000000000000004 gi1
0000000000000000 g F .text 000000000000003a main
0000000000000000 *UND* 0000000000000000 addadd.o: 文件格式 elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 add.c
0000000000000000 l d .text 0000000000000000 .text
0000000000000000 g O .data 0000000000000004 gi
0000000000000000 g F .text 0000000000000018 adda.out: 文件格式 elf64-x86-64
SYMBOL TABLE:
0000000000000000 l df *ABS* 0000000000000000 add.c
0000000000000000 l df *ABS* 0000000000000000 main.c
0000000000403008 l O .data 0000000000000004 gi2
0000000000403004 g O .data 0000000000000004 gi1
0000000000403000 g O .data 0000000000000004 gi
0000000000401000 g F .text 0000000000000018 add
000000000040300c g .data 0000000000000000 __bss_start
0000000000401018 g F .text 000000000000003a main
000000000040300c g .data 0000000000000000 _edata
0000000000403010 g .data 0000000000000000 _end从符号表中可以看到,各自的.o文件中符号表一开始都是没有地址的,并且main的符号表中add是undefined,经过链接后,才有了地址,并且add也不再是undefined。
总结编译和链接
经过预处理、编译、汇编和链接这四个主要步骤,源代码最终会被转换成可执行文件。
虽然具体的转换过程可能因平台、编译器等因素有所不同,但这四个核心步骤是通用的。对于大多数C程序员来说,掌握这些基本概念有助于更深入地理解和应用C语言。
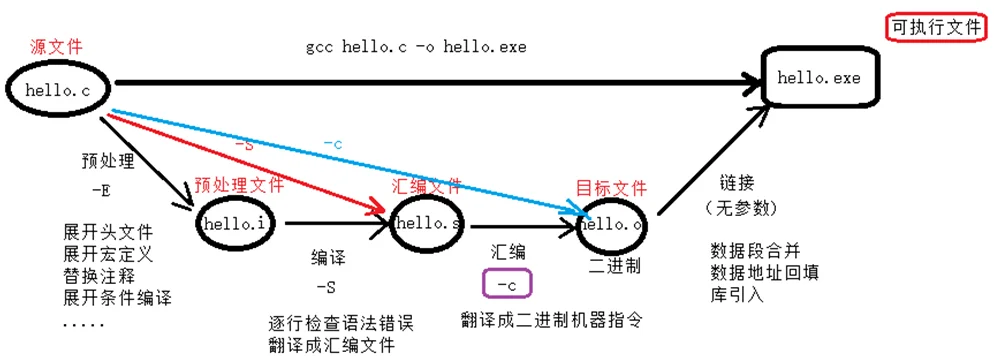
整个流程参考下图:
当然幸运的是,这些工作在普通的开发中,也确实不需要我们操心了。我们只需要点几个按钮,或者输入几行命令就可以自动完成编译和链接的过程。比如:
- 在Windows平台,我们使用集成开发环境Visual Studio,它提供了易用的界面和命令行工具来自动化编译和链接过程。
- 在Linux平台,GCC(GNU Compiler Collection)是最常用的编译工具套件。我们也只需要在终端使用几行简短的命令,也可以快速完成编译和链接的过程。
使用GCC编译的过程
gcc(GNU Compiler Collection,GNU 编译器套件),是由 GNU 开发的编程语⾔编译器。gcc原本作为GNU操作系统的官⽅编译器,现已被⼤多数类Unix操作系统(如Linux、BSD、MacOS X等)采纳为标准的编译器,gcc同样适用于微软的Windows。
gcc最初用于编译C语⾔,随着项目的发展gcc已经成为了能够编译C、C++、Java、Ada、fortran、Object C、Object C++、Go语⾔的编译器⼤家族。
编译命令格式:
gcc [-option1] [-option2] ... <filename>
g++ [-option1] [-option2] ... <filename>- 命令、选项和源文件之间使用空格分隔
- 一行命令中可以有零个、一个或多个选项
- 文件名可以包含文件的绝对路径,也可以使用相对路径
- 如果命令中不包含输出可执行文件的文件名,可执行文件的文件名会⾃动生成一个默认名,Linux平台为
a.out,Windows平台为a.exe
option参数说明
| 选项 | 含义 |
|---|---|
-o file | 指定生成的输出文件名为file |
-E | 只进行预处理 |
-S(⼤写) | 只进行预处理和编译 |
-c(⼩写) | 只进行预处理、编译和汇编 |
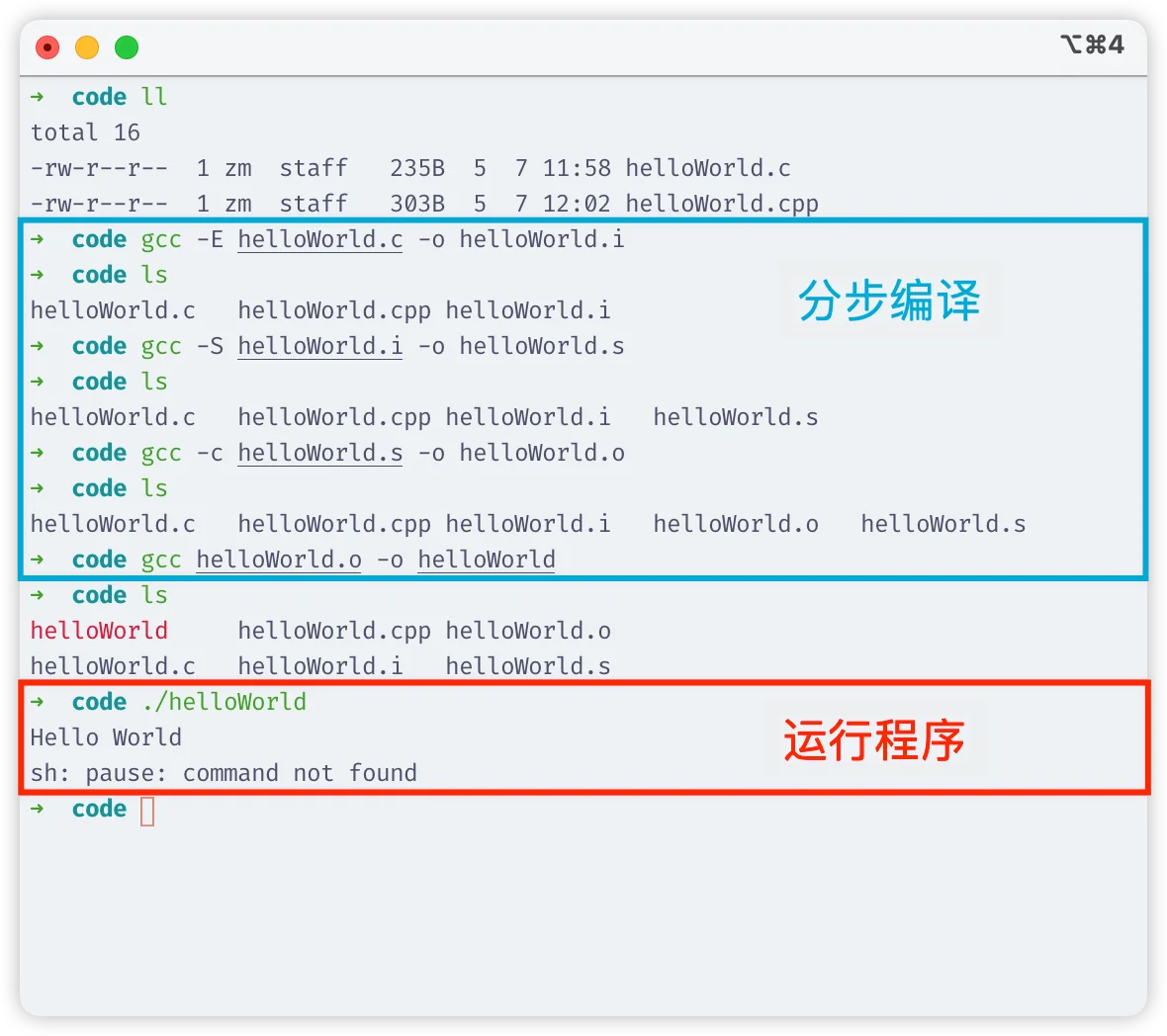
分步编译
- 预处理:
gcc -E helloWorld.c -o helloWorld.i - 编译:
gcc -S helloWorld.i -o helloWorld.s - 汇编:
gcc -c helloWorld.s -o helloWorld.o - 链接:
gcc helloWorld.o -o helloWorld
| 参数 | 含义 | 生成文件 | 生成文件的含义 |
|---|---|---|---|
-E | 只进行预处理 | .c | C 语⾔文件 |
-S(⼤写) | 只进行预处理和编译 | .i | 预处理后的 C 语⾔文件 |
-c(⼩写) | 只进行预处理、编译和汇编 | .s | 编译后的汇编文件 |
-o file | 指定生成的输出文件名为file | .o | 编译后的目标文件 |
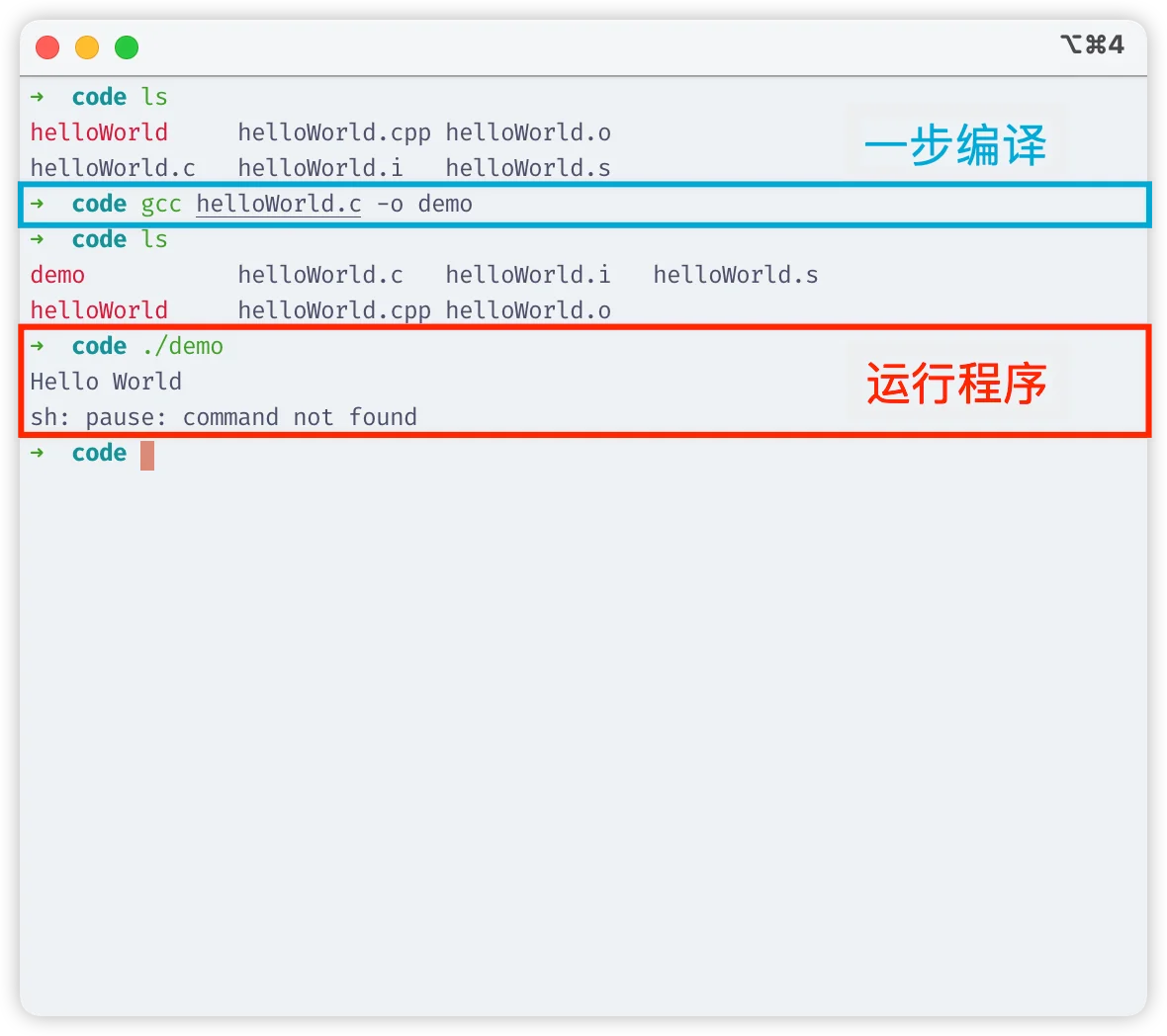
一步编译
gcc helloWorld.c -o demo(还是经过:预处理、编译、汇编、链接的过程)
可能遇到的错误
遇到
TERM environment variable not set错误详细情况及解决方法
Mac 使用CLion/VS Code工具书写C/C++代码执行清屏操作:
system(“clear”);的时候出现。VS Code环境下⽰例代码:
cpp#include <stdio.h> #include <stdlib.h> int main() { printf("输出测试01\n"); system("clear"); printf("输出测试02\n"); return 0; }没有正确设置环境变量运行的情况
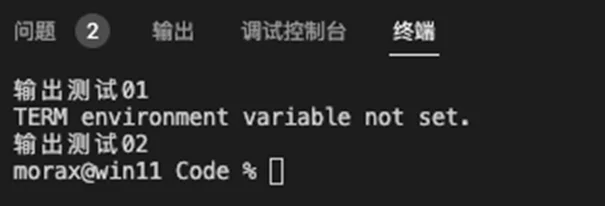
正确设置了环境变量运行后
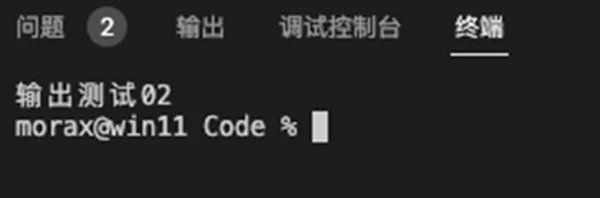
解决办法:
- Clion:Edit Configurations --> Environment variables 里⾯添加一个键值对即可,键:
TERM值:xterm-256color。 - VS Code:在设置搜索“Environment variables”,然后添加上述键值对即可。
- Clion:Edit Configurations --> Environment variables 里⾯添加一个键值对即可,键:
为什么.o文件不能直接运行
.o文件是一个二进制可重定向的目标文件,并不是可执行程序,它只是一个中间文件,需要与其他的.o文件和库文件一起链接才能生成可执行程序。