数据类型
什么是数据类型?为什么需要数据类型?
数据类型是为了更好进行内存的管理,让编译器能确定分配多少内存。
我们现实生活中,狗是狗,鸟是鸟等等,每一种事物都有⾃⼰的类型,那么程序中使用数据类型也是来源于生活。
当我们给狗分配内存的时候,也就相当于给狗建造狗窝,给鸟分配内存的时候,也就是给鸟建造一个鸟窝,我们可以给他们各⾃建造一个别墅,但是会造成内存的浪费,不能很好的利用内存空间。
我们在想,如果给鸟分配内存,只需要鸟窝大小的空间就够了,如果给狗分配内存,那么也只需要狗窝大小的内存,而不是给鸟和狗都分配一座别墅,造成内存的浪费。
当我们定义一个变量 a = 10 ,编译器如何分配内存?计算机只是一个机器,它怎么知道用多少内存可以放得下10?
所以说,数据类型非常重要,它可以告诉编译器分配多少内存可以放得下我们的数据。
狗窝里面是狗,鸟窝里面是鸟,如果没有数据类型,你怎么知道冰箱里放的是一头大象!
基本概念
数据类型的定义
数据类型是编程语言中用于规范变量或表达式的性质的一个抽象概念。它确定了所存储数据的形式、大小和布局,并定义了可对该类型数据执行的操作集合。
这句话我们剥离本质,得到数据类型的定义:
在后续课程会详细讲解C语言的常用数据类型,本小节就以"int"和"float"为例子来帮助大家理解一下这个概念。
,是C语言当中常用的整数类型。一般而言,int类型的变量占用4个字节的内存空间,加上C语言中的整数默认是有符号整数,它的取值范围是[-231, 231 - 1]
除此之外,int还规定了该变量可以做加减乘除等操作,但显然没有求长度,求重量这样的操作。
,是C语言当中常用的浮点数类型。简单来说,它可以存储带小数位的数,比如0.1,123.6,-0.123等。浮点数通常遵循IEEE754标准,float占用4个字节的内存空间。同时,float类型的变量也可以执行加减乘除等操作,当然也没有求长度,求重量这样的操作。
作用
编译器预算对象(变量)分配的内存空间大小。
分类
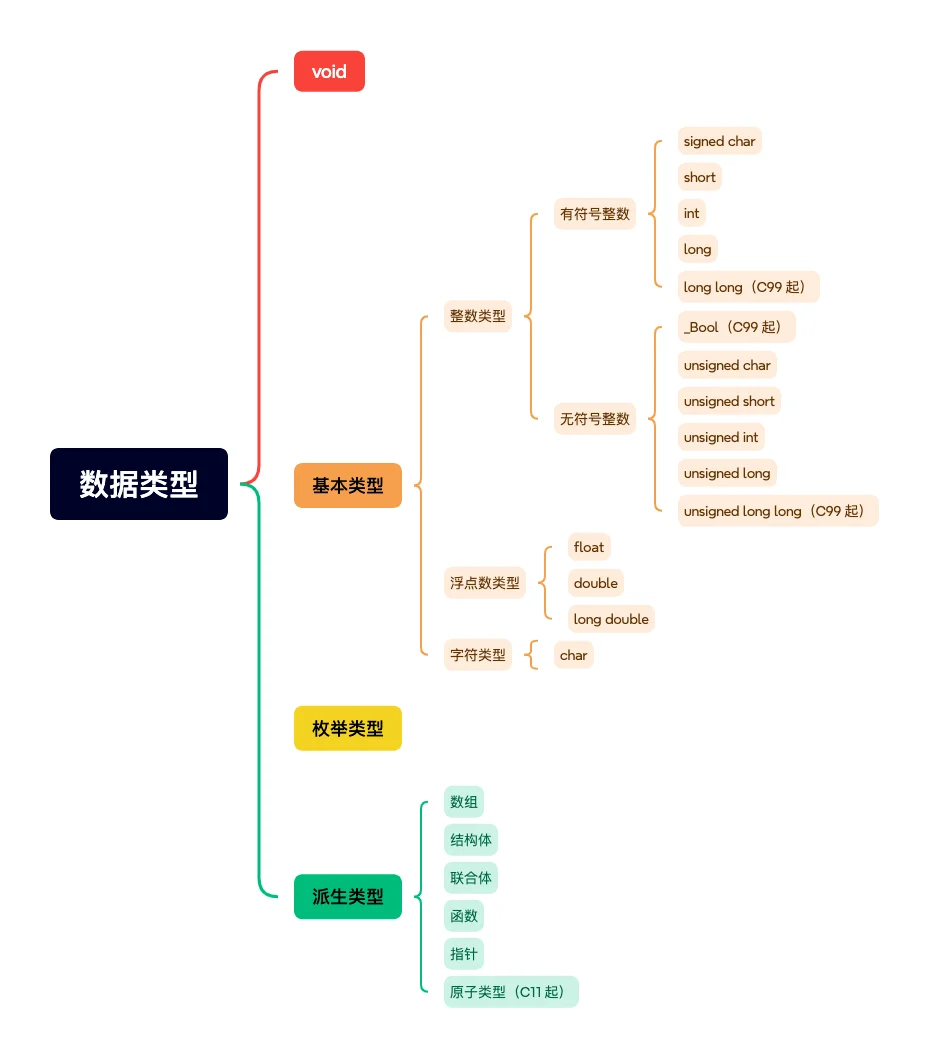
判断数据类型
在C语言中,没有直接的方式来输出一个变量的数据类型,因为C语言是一种静态类型的语言,在编译时就需要知道所有变量的数据类型。但是,你可以通过一些方法来间接地输出变量的数据类型。
具体方法参考:_Generic
sizeof关键字
sizeof是C语⾔中的一个运算符,类似于++、--等等。sizeof能够告诉我们编译器为某一特定数据或者某一个类型的数据在内存中分配空间时分配的大小,大小以字节为单位。
基本语法
sizeof(变量);
sizeof 变量;
sizeof(类型);注意
sizeof返回的占用空间大小是为这个变量开辟的大小,而不只是它用到的空间。和现今住房的建筑⾯积和实用⾯积的概念差不多。所以对结构体用的时候,大多情况下就得考虑字节对齐的问题了;sizeof返回的数据结果类型是unsigned int;- 要注意数组名和指针变量的区别。通常情况下,我们总觉得数组名和指针变量差不多,但是在用
sizeof的时候差别很大,对数组名用sizeof返回的是整个数组的大小,而对指针变量进行操作的时候返回的则是指针变量本⾝所占得空间,在32位机的条件下一般都是4。而且当数组名作为函数参数时,在函数内部,形参也就是个指针,所以不再返回数组的大小;
程序实例
#include <stdio.h>
#include <stdlib.h>
//1. sizeof基本用法
void test01() {
int a = 10;
printf("len:%zu\n", sizeof(a));
printf("len:%zu\n", sizeof(int));
printf("len:%zu\n", sizeof a);
}
//2. sizeof 结果类型
void test02() {
unsigned int a = 10;
if (a - 11 < 0) {
printf("结果小于0\n");
} else {
printf("结果大于0\n");
}
int b = 5;
if (sizeof(b) - 10 < 0) {
printf("结果小于0\n");
} else {
printf("结果大于0\n");
}
}
//3. sizeof 碰到数组
void TestArray(int arr[]) { printf("TestArray arr size:%zu\n", sizeof(arr)); }
void test03() {
int arr[] = {10, 20, 30, 40, 50};
printf("array size: %zu\n", sizeof(arr));//数组名在某些情况下等价于指针
int *pArr = arr;
printf("arr[2]:%d\n", pArr[2]);
printf("array size: %zu\n", sizeof(pArr));//数组做函数函数参数,将退化为指针,在函数内部不再返回数组大小
TestArray(arr);
}
int main(void) {
printf("test01 print:\n");
test01();
printf("\n\ntest02 print:\n");
test02();
printf("\n\ntest03 print:\n");
test03();
return 0;
}程序输出:
test01 print:
len:4
len:4
len:4
test02 print:
结果大于0
结果大于0
test03 print:
array size: 20
arr[2]:30
array size: 8
TestArray arr size:8- ,所以不需要包含任何头文件,它的功能是计算一个数据类型的大小,单位为 字节。
- sizeof的返回值为
size_t类型; size_t的位宽不小于 16 。size_t通常用于数组下标和循环计数。size_t类型的数据在格式化打印的时间使用%zu进行匹配。
在C语言中,
%u和%zu是用于格式化输出的格式说明符,它们用于表示整数类型。
%u:这是一个无符号整数类型格式说明符。它用于表示无符号整数类型,例如unsigned int。%zu:这是一个用于表示size_t类型的格式说明符。size_t是一个无符号整数类型,通常用于表示对象的大小和计数。在大多数情况下,
%u和%zu可以互换使用,因为它们都表示无符号整数类型。然而,使用%zu更为准确和推荐,因为它明确指定了size_t类型,而%u可能会根据平台的不同而具有不同的含义。使用
%zu可以确保代码的可移植性更好,因为size_t是一个固定宽度的类型,通常用于数组索引和循环计数等场景。使用%u可能会导致在不同的平台和编译器上具有不同的宽度和行为。因此,在进行格式化输出时,如果要表示
size_t类型的值,应该使用%zu,如果要表示其他无符号整数类型,可以根据具体需求选择%u或%zu。
#include <stdio.h>
#include <stdlib.h>
int main() {
int a;
int b = sizeof(a); // 使用int类型接收sizeof的值,不推荐
//sizeof得到指定值占用内存的大小,单位:字节
printf("b = %d\n", b);
size_t c = sizeof(a); // 使用size_T类型接收sizeof的值,推荐💕
printf("c = %zu\n", c);//用⽆符号数的⽅式输出c的值
return 0;
}程序输出:
b = 4
c = 4typedef别名
我们可以使用宏给某一类型创建一个别名,如:
#define BOOL int但是更好的做法是使用 typedef
typedef int Bool;注意
我们定义的别名是放在最后的,而且类型定义是一条语句,后面需要加分号。
使用 typedef 定义别名 Bool,编译器会把 Bool 加入它所能识别的类型名列表中。现在我们可以像使用 C 语言内置类型一样使用 Bool 类型了。如:
Bool flag; /* same as int flag */编译器会把 Bool 看作 int 的同义词;因此,flag 其实就是一个普通的 int 类型变量。
typedef为C语⾔的关键字,作用是为一种数据类型(基本类型或自定义数据类型)定义一个新名字,。
- 与
#define不同,typedef仅限于数据类型,而不是能是表达式或具体的值 #define发生在预处理,typedef发生在编译阶段
typedef unsigned int u32;
typedef struct _PERSON {
char name[64];
int age;
}Person;
void test() {
u32 val; //相当于 unsigned int val;
Person person; //相当于 struct _PERSON person;
}程序实例
#include <stdio.h>
#include <stdlib.h>
typedef int INT;
typedef char BYTE;
typedef BYTE T_BYTE;
typedef unsigned char UBYTE;
typedef struct type {
UBYTE a;
INT b;
T_BYTE c;
} TYPE, *PTYPE;
int main(void) {
TYPE t;
t.a = 254;
t.b = 10;
t.c = 'c';
PTYPE p = &t;
printf("%u, %d, %c\n", p->a, p->b, p->c);
return 0;
}程序输出:
254, 10, c为什么要定义别名?
使用别名主要有以下两个优点:
- 增加代码的可读性(前提是选择合适的类型名)
- 增加代码的可移植性
我们举个例子来说明这一点。把 C 语言程序从一台机器移植到另一台机器,可能出现的问题之一就是类型的取值范围不同。比如,i 是 int 类型的变量,那么 i = 100000 在 32-bit 的机器上是没有问题的,但在 16-bit 的机器上就会出错。
当然为了避免出现可移植性问题,我们可以变量 i 声明为 long int 类型。但是 int 类型的变量在运算时会比 long int 类型的变量更快,而且所占内存空间更少。
另一个解决方案就是使用别名。在 32-bit 的机器上,我们这样定义 Quantity 类型:
typedef int Quantity;而在 16-bit 的机器上,我们将 Quantity 的定义改为:
typedef long Quantity;C 语言库也经常使用 typedef 去定义一些类型;这些类型名经常以 _t 结尾。如: size_t, ptrdiff_t 和 wchar_t,这些类型的定义可能随着实现的不同而不同(所以才定义别名,增加代码的可移植性)。下面是它们的典型定义:
typedef long int ptrdiff_t;
typedef unsigned long int size_t;
typedef int wchar_t;C语言中的布尔值表示
在数据类型章节的最后,我们一起来看一下C语言中的布尔值表示,它是代码中十分常用的概念。
所以,为了表示布尔值C语言规定:
- 任何都被视为true(真)
- 任何都被视为false(假)
Tips
整数类型和浮点类型都是数值类型,它们的零值和非零值很容易理解,但C语言还有一个比较特殊的指针类型。在指针类型中:
- 零值代表空指针,即NULL
- 非零值代表指针指向一片内存区域,即非空针。
这种无布尔类型的设计,在早期为C程序员带来了很大的麻烦,使得程序员经常能写出一些可读性差的丑陋代码。为了改变这一局面,从C99开始,C语言支持了独立的布尔类型_Bool,但它不属于基本数据类型。
为了让程序员更容易地使用布尔类型,C99还提供了一个头文件<stdbool.h>。当你包含这个头文件时,你可以使用以下标识符更好的来使用布尔类型:
bool:实际上就是类型_Bool的别名。建议使用别名来使用该布尔类型,而不是
_Bool。true:表示真。实际上就是整数值1。flase:表示假。实际上就是整数值0。
以上。
关于在C语言中使用布尔值的建议
首先,我们强烈不建议大家直接把一个整数、指针类型变量作为布尔值在代码中直接使用。比如
int a = 0;
if (!a) { // 等价于 a == 0
printf("a is 0.\n");
}这样的做法虽然使得代码简洁,但牺牲了很多可读性,使得代码不够直观明确的表达含义,在现代C编程中是比较得不偿失的。(如果把a改成一个指针类型,这个代码将更加丑陋)
所以应该写成以下格式:
if (a == 0)除此之外,我们还建议,当你需要把布尔值作为函数的返回值和形参时,也尽量不要直接用int类型,而是包含头文件使用类型别名bool。
比如:
#include <stdbool.h>
bool fun(void) {
// ...
return true;
}总之,在现代的C编程中,我们更追求更好的可读性和明确性,尤其是当确定代码会在C99标准及以后的编译器平台上运行时,使用布尔类型bool是一个好习惯。
总结
数据类型本质是固定内存大小的别名,是个模具。C语⾔规定:
- 通过数据类型定义变量;
- 数据类型大小计算(sizeof);
- 可以给已存在的数据类型起别名typedef;
- 数据类型的封装(void 万能类型);
附录: ASCII码表
ASCII(American Standard Code for Information Interchange)美国信息交换标准代码),是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
表格中的每一个十进制ASCII编码值,都映射一个字符。ASCII表是最基本的字符编码表,现在常用的编码表大多是兼容ASCII表的。
| ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 | ASCII值 | 控制字符 |
|---|---|---|---|---|---|---|---|
| 0 | NUT | 32 | (space) | 64 | @ | 96 | 、 |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | " | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | , | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | HT | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | - | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DCI | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | 82 | R | 114 | r |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | TB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | (冒号) | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | / | 124 | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ` |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
不要去尝试完全记忆ASCII码表,没有太大的意义,只要记住部分比较常见的字符就可以了,其它字符需要用的时候查表即可。