二叉树
基本概念
定义:
n(n≥0)个结点的有限集合,由一个根结点以及的、分别称为左子树和右子树的二叉树组成 。
逻辑结构:
一对二(1:2)
基本特征:
每个结点最多只有两棵子树();
左子树和右子树次序不能颠倒()。
基本形态:
二叉树性质
性质1: 在二叉树的第i层上至多有2^i-1^个结点(i>0)
性质2: 深度为k的二叉树至多有2^k^-1个结点(k>0)
性质3: 对于任何一棵二叉树,若度为2的结点数有n2个,则叶子数(n0)必定为n2+1 (即n0=n2+1)
性质4: 具有n个结点的完全二叉树的深度必为(log~2~n)+1
性质5: 对完全二叉树,若从上至下、从左至右编号,则编号为i 的结点,其左孩子编号必为2*i,其右孩子编号必为2*i+1;其双亲的编号必为i/2(i=1 时为根,除外)
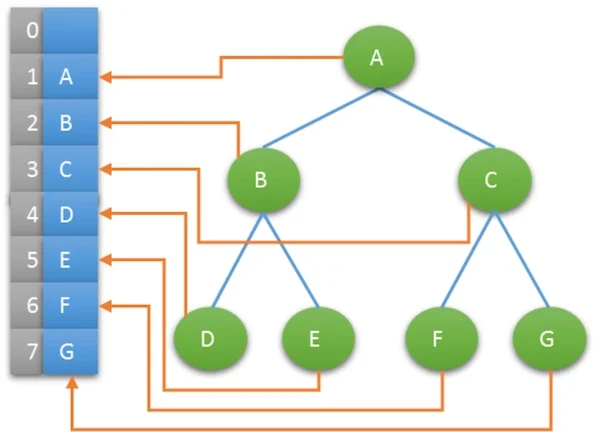
使用此性质可以使用完全二叉树实现树的顺序存储。
如果不是完全二叉树咋整???
------ 将其转换成完全二叉树即可
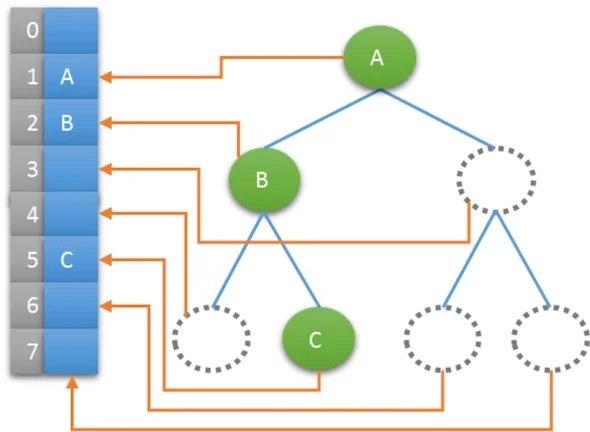
缺点:①浪费空间;②插入、删除不便
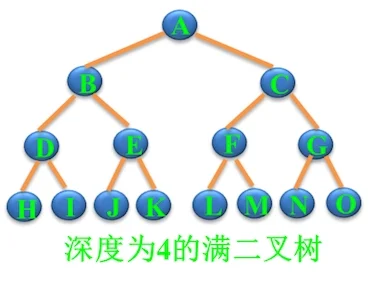
满二叉树
一棵深度为k 且有2^k^ -1个结点的二叉树。
特点:每层都“充满”了结点
完全二叉树
除最后一层外,每一层上的节点数均达到最大值;在最后一层上只缺少右边的若干结点。
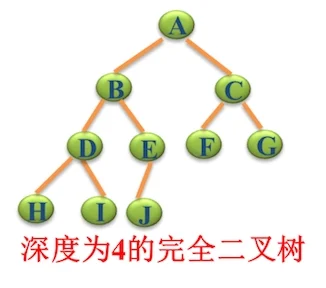
理解:k-1层与满二叉树完全相同,第k层结点尽力靠左
二叉树的表示
二叉链表示法
一般从根结点开始存储。相应地,访问树中结点时也只能从根开始。
- 存储结构
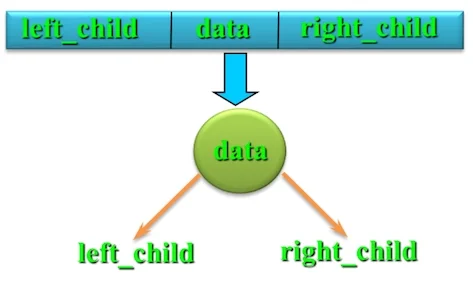
- 结点数据类型定义:
typedef struct BiTNode{
int data;
struct BiTNode *lchild, *rchild;
}BiTNode, *BiTree;三叉链表表示法
- 存储结构

每个节点有三个指针域,其中两个分别指向子节点(左孩子,右孩子),还有一共指针指向该节点的父节点。
- 节点数据类型定义
//三叉链表
typedef struct TriTNode {
int data;
//左右孩子指针
struct TriTNode *lchild, *rchild;
struct TriTNode *parent;
}TriTNode, *TriTree;树和森林的转换
二叉树和树、森林之间是可以相互转换的。
我们可以使用下面的规律将一棵普通的树转换为一棵二叉树:
- 最左边孩子结点 -> 左子树结点(左孩子)
- 兄弟结点 -> 右子树结点(右孩子)
我们以下面的这棵树为例:
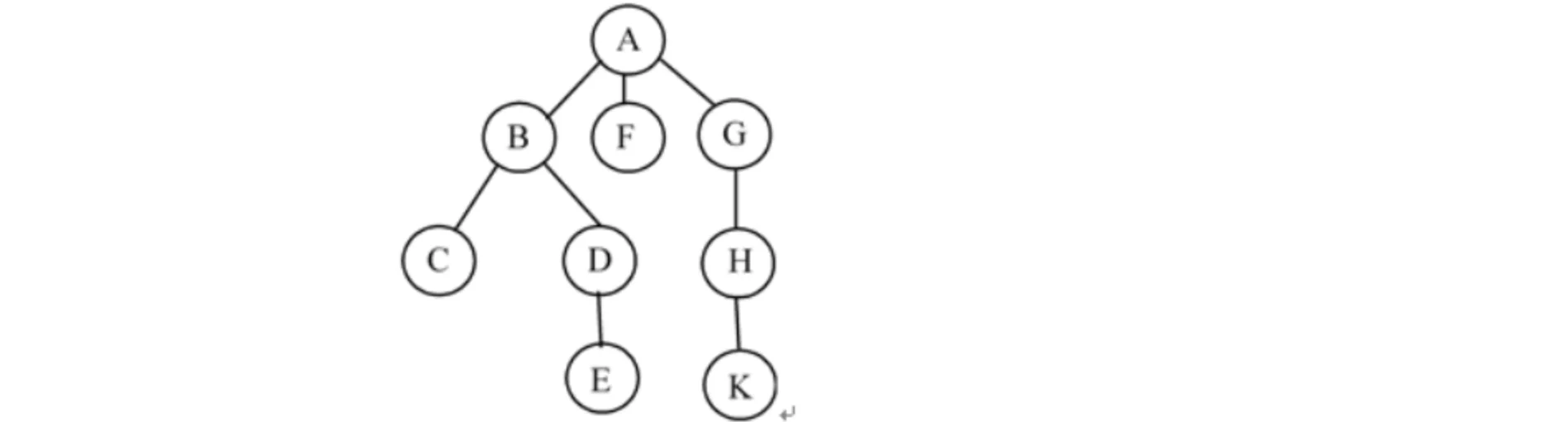
我们优先从左边开始看,B、F、G都是A的子结点,根据上面的规律,我们将B作为左子树:

接着继续从左往右看,由于F是B的兄弟结点,那么根据规律,F作为B的右子树:
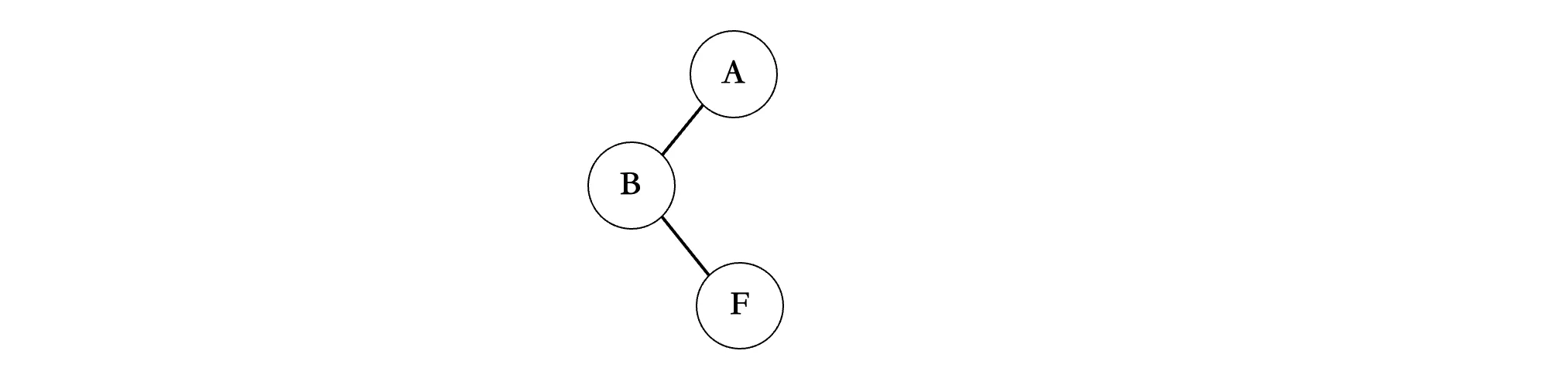
接着是G,G是F的兄弟结点,那么G继续作为F的右子树:
我们接着来看第三排,依然是从左往右,C是B的子节点,所以C作为B的左子树:
接着,D是C的兄弟节点,那么D就作为C的右子树了:
此时还有一个H结点,它是G的子结点,所以直接作为G的左子树:
现在只剩下最后一排了,E是D的子结点,K是H的子结点,所以最后就像这样了:
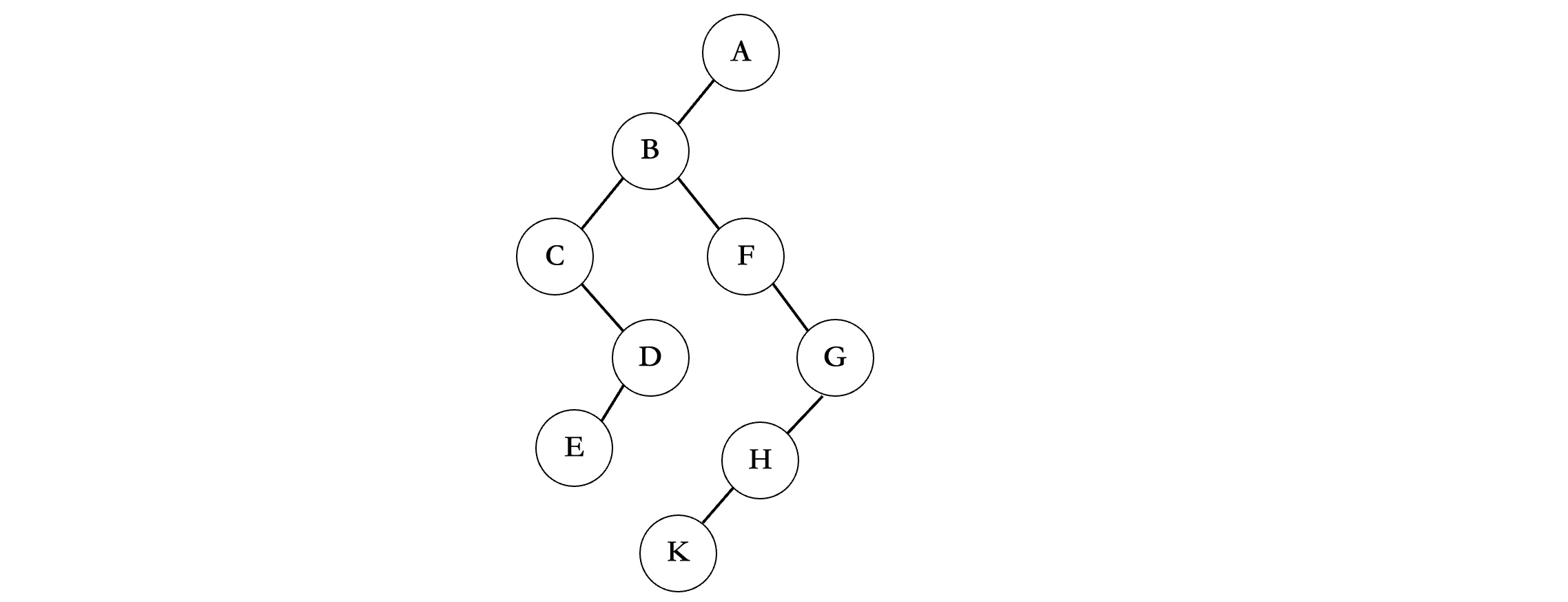
按照规律,我们就将一棵树转换为了二叉树。当然还有一种更简单的方法,我们可以直接将所有的兄弟结点连起来(橙色横线):
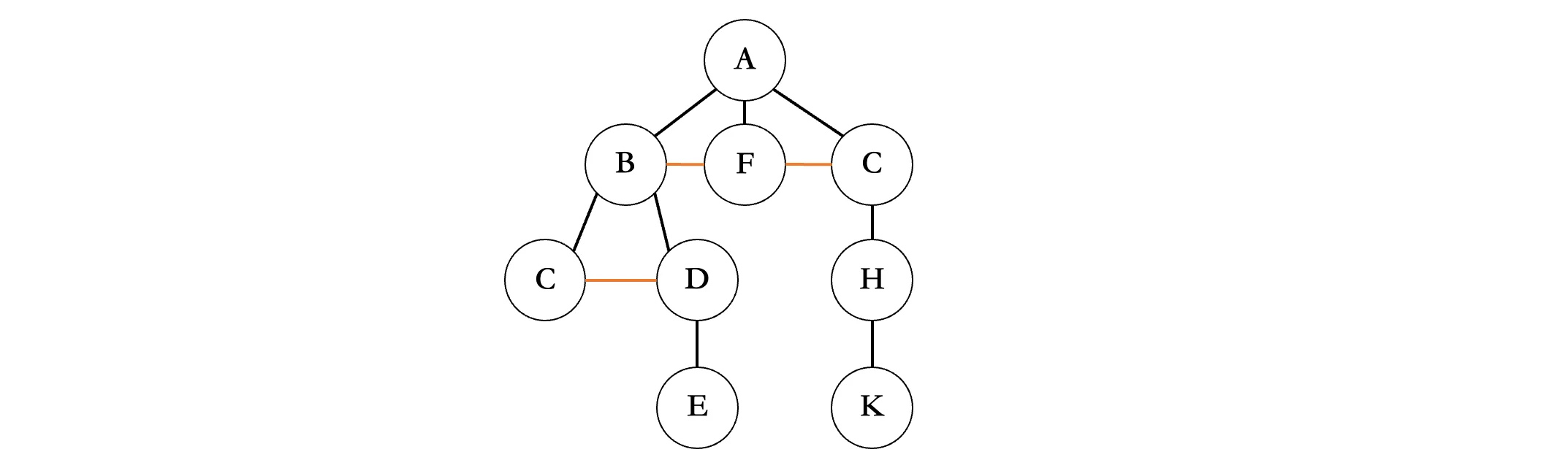
接着擦掉所有结点除了最左边结点以外的连线:
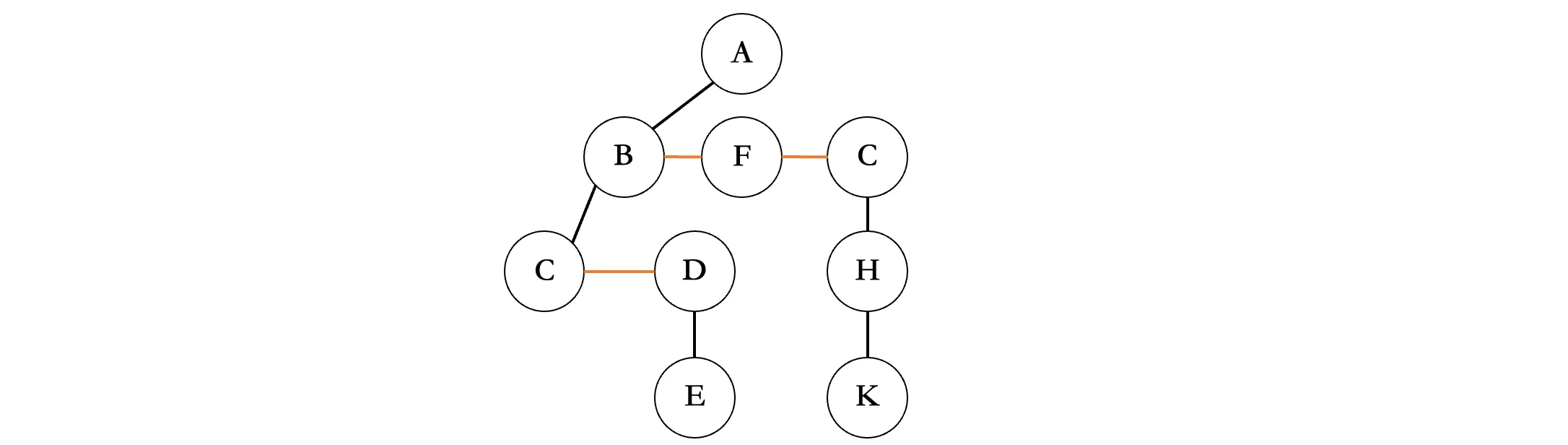
所有的黑色连线偏向左边,橙色连线偏向右边:
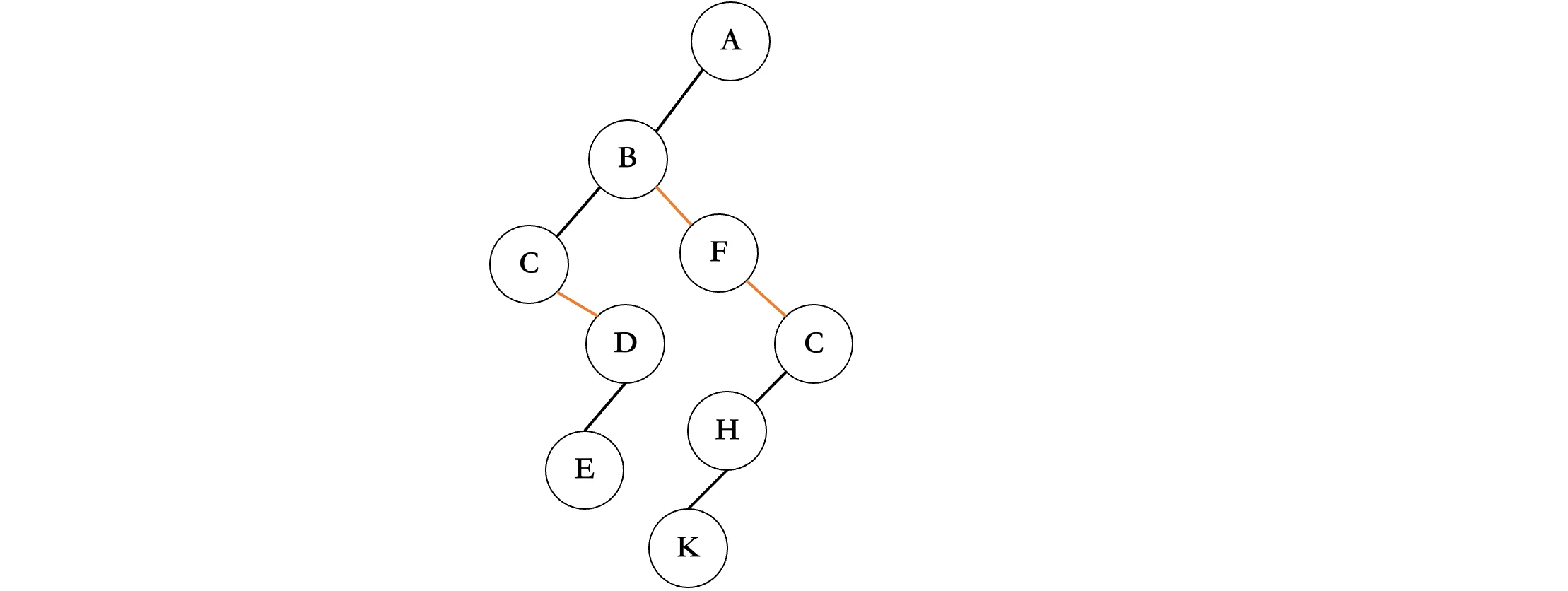
效果是一样的,这两种方式都可以,你觉得哪一种简单就使用哪一种就行了。我们会发现,无论一棵树长成啥样,转换为二叉树后,根节点一定没有右子树。
思考:那二叉树咋变回普通的树呢?实际上我们只需要反推回去就行了。
那么森林呢,森林如何转换为一棵二叉树呢?其实很简单:
首先我们还是按照二叉树转换为树的规则,将森林中所有树转换为二叉树,接着我们只需要依次连接即可:
注意连接每一棵树的时候,一律从根结点的右边开始,不断向右连接。
我们发现,相比树转换为二叉树,森林转换为二叉树之后,根节点就存在右子树了,右子树连接的都是森林中其他的树。
思考:现在有一棵二叉树,我们想要转回去,我们怎么知道到底是将其转换为森林还是转换为树呢?
二叉树的性质
由于二叉树结构特殊,我们可以总结出以下的五个性质:
性质一:对于一棵二叉树,第
i层的最大结点数量为个,比如二叉树的第一层只有一个根结点,也就是 ,而二叉树的第三层可以有 个结点。 性质二:对于一棵深度为
k的二叉树,可以具有的最大结点数量为:我们发现,实际上每一层的结点数量,组成了一个等比数列,公比
q为2,结合等比数列求和公式,我们可以将其简化为:所以一棵深度为
k的二叉树最大结点数量为,顺便得出,结点的边数为 。 性质三:假设一棵二叉树中度为0、1、2的结点数量分别为
、 、 ,由于一棵二叉树中只有这三种类型的结点,那么可以直接得到结点总数: 我们不妨换一个思路,我们从二叉树的边数上考虑,因为每个结点有且仅有一条边与其父结点相连,那么边数之和就可以表示为:
度为1的结点有一条边,度为2的结点有两条边,度为0的结点没有,加在一起就是整棵二叉树的边数之和,结合我们在性质二中推导的结果,可以得到另一种计算结点总数的方式:
再结合我们第一个公式:
综上,对于任何一棵二叉树,如果其叶子结点个数为
,度为2的结点个数为 ,那么两者满足以下公式: (性质三的推导过程比较复杂,如果觉得麻烦推荐直接记忆)
性质四:完全二叉树除了最后一层有空缺外,其他层数都是饱满的,假设这棵二叉树为满二叉树,那么根据我们前面得到的性质,假设层数为
k,那么结点数量为:,根据完全二叉树的性质,最后一层可以满可以不满,那么一棵完全二叉树结点数 n满足:因为
n肯定是一个整数,那么可以写为:现在我们只看左边的不等式,我们对不等式两边同时取对数,得到:
综上所述,一棵具有
n个结点的完全二叉树深度为。 (性质四的推导过程比较复杂,如果觉得麻烦推荐直接记忆)
性质五:一颗有
n个结点的完全二叉树,由性质四得到深度为现在对于任意一个结点 i,结点的顺序为从上往下,从左往右:- 对于一个拥有左右孩子的结点来说,其左孩子为
2i,右孩子为2i + 1。 - 如果
i = 1,那么此结点为二叉树的根结点,如果i > 1,那么其父结点就是,比如第3个结点的父结点为第1个节点,也就是根结点。 - 如果
2i > n,则结点i没有左孩子,比如下面图中的二叉树,n为5,假设此时i = 3,那么2i = 6 > n = 5说明第三个结点没有左子树。 - 如果
2i + 1 > n,则结点i没有右孩子。
- 对于一个拥有左右孩子的结点来说,其左孩子为
以上五条二叉树的性质一般是笔试重点内容,还请务必牢记,如果觉得推导过程比较麻烦,推荐直接记忆结论。
二叉树练习题:
由三个结点可以构造出多少种不同的二叉树?
这个问题我们可以直接手画得到结果,一共是五种,当然,如果要求N个结点的话,可以利用动态规划求解,如果这道题是求N个结点可以构造多少二叉树,我们可以分析一下:
- 假设现在只有一个结点或者没有结点,那么只有一种,
- 假设现在有两个结点,那么其中一个拿来做根结点,剩下这一个可以左边可以右边,要么左边零个结点右边一个结点,要么左边一个结点右边零个结点,所以说
- 假设现在有三个结点,那么依然是其中一个拿来做根节点,剩下的两个结点情况就多了,要么两个都在左边,两个都在右边,或者一边一个,所以说
我们发现,它是非常有规律的,N每+1,项数多一项,所以我们只需要按照规律把所有情况的结果相加就行了,我们按照上面推导的结果,编写代码:
cint main(){ int size; scanf("%d", &size); //读取需要求的N int dp[size + 1]; dp[0] = dp[1] = 1; //没有结点或是只有一个结点直接得到1 for (int i = 2; i <= size; ++i) { dp[i] = 0; //一开始先等于0再说 for (int j = 0; j < i; ++j) { //内层循环是为了计算所有情况,比如i等于3,那么就从j = 0开始,计算dp[0]和dp[2]的结果,再计算dp[1]和dp[1]... dp[i] += dp[j] * dp[i - j - 1]; } } printf("%d", dp[size]); //最后计算的结果就是N个结点构造的二叉树数量了 }
成功得到结果,当然,实际上我们根据这个规律,还可以将其进一步简化,求出的结果序列为:1, 1, 2, 5, 14, 42, 132...,这种类型的数列我们称为卡特兰数,以中国蒙古族数学家明安图 (1692-1763)和比利时的数学家欧仁·查理·卡塔兰 (1814–1894)的名字来命名,它的通项公式为:
所以说不需要动态规划了,直接一个算式解决问题:
cint factorial(int n){ int res = 1; for (int i = 2; i <= n; ++i) res *= i; return res; } int main(){ int n; scanf("%d", &n); printf("%d", factorial(2*n) / (factorial(n) * factorial(n + 1))); }只不过这里用的是int,运算过程中如果数字太大的话就没办法了
- 假设现在只有一个结点或者没有结点,那么只有一种,
一棵完全二叉树有1001个结点,其中叶子结点的个数为?
既然是完全二叉树,那么最下面这一排肯定是按顺序排的,并且上面各层应该是排满了的,那么我们先求出层数,根据性质四:
所以此二叉树的层数为10,也就是说上面9层都是满满当当的,最后一层不满,那么根据性质二,我们求出前9层的结点数:
那么剩下的结点就都是第十层的了,得到第十层所有叶子结点数量 $ = 1001 - 511 = 490$,因为第十层并不满,剩下的叶子第九层也有,所以最后我们还需要求出第九层的叶子结点数量,先计算第九层的所有结点数量:
接着我们需要去掉那些第九层度为一和度为二的结点,其实只需要让第十层都叶子结点除以2就行了:
注意在除的时候+1,因为有可能会出现一个度为1的结点,此时也需要剔除,所以说+1变成偶数这样才可以正确得到结果。最后剔除这些结点,得到最终结果:
所以这道题的答案为501。
深度为h的满m叉树的第k层有多少个结点?
这道题只是看着复杂,但是实际上我们把之前推导都公式带进来就行了。但是注意,难点在于,这道题给的是满m叉树,而不是满二叉树,满二叉树根据性质一我们已经知道:
那m叉树呢?实际上也是同理的,我们以三叉树为例,每向下一层,就划分三个孩子结点出来:
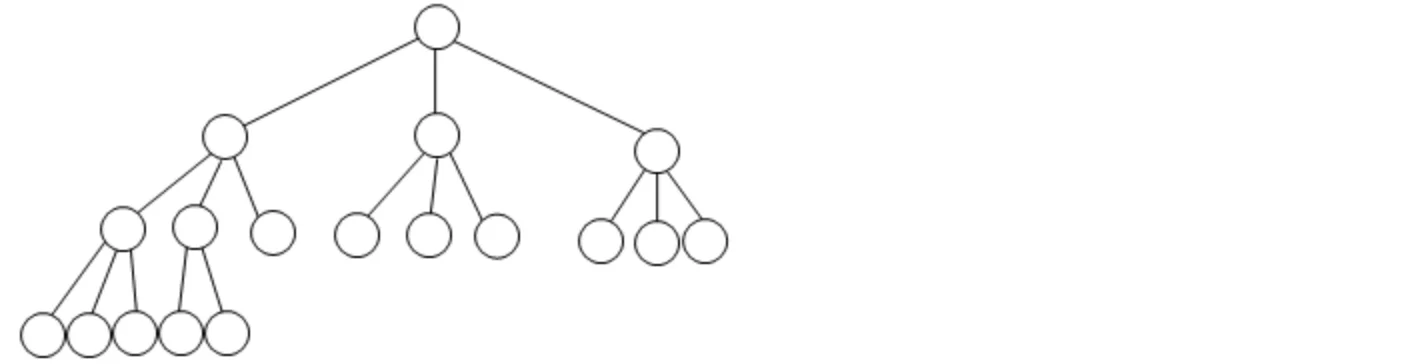
每一层的最大结点数依次为:1、3、9、27....
我们发现,实际上每一层的最大结点数,正好是3的次方,所以说无论多少叉树,实际上变化的就是底数而已,所以说深度为h(h在这里没卵用,障眼法罢了)的满m叉树第k层的结点数:
一棵有1025个结点的二叉树的层数k的取值范围是?
这个问题比较简单,层数的最小值实际上就是为完全二叉树的情况,层数的最大值实际上就是连成一根线的情况,结点数就是层数,所以说根据性质四得到最小深度为11,最大深度就直接1025了,k的范围是11 - 1025
将一棵树转换为二叉树时,根节点的右边连接的是?
根据我们前面总结得到的性质,树转换为二叉树之后,根节点一定没有右子树,所以为空
二叉树的构建
前面我们介绍了二叉树的几个重要性质,那么现在我们就来尝试在程序中表示和使用一棵二叉树。
二叉树的存储形式也可以使用我们前面的两种方式,一种是使用数组进行存放,还有一种就是使用链式结构,只不过之前链式结构需要强化一下才可以表示为二叉树。
首先我们来看数组形式的表示方式,利用前面所推导的性质五,我们可以按照以下顺序进行存放:
这颗二叉树的顺序存储:

从左往右,编号i从1开始,比如现在我们需要获取A的右孩子,那么就需要根据性质五进行计算,因为右孩子为2i + 1,所以A的右边孩子的编号就是3,也就是结点C。
这种表示形式使用起来并不方便,而且存在大量的计算,所以说我们只做了解即可,我们的重点是下面的链式存储方式。
我们在前面使用链表的时候,每个结点不仅存放对应的数据,而且会存放一个指向下一个结点的指针:

而二叉树也可以使用这样的链式存储形式,只不过现在一个结点需要存放一个指向左子树的指针和一个指向右子树的指针了:

通过这种方式,我们就可以通过连接不同的结点形成一颗二叉树了,这样也更便于我们去理解它,我们首先定义一个结构体:
typedef char E;
struct TreeNode {
E element; //存放元素
struct TreeNode * left; //指向左子树的指针
struct TreeNode * right; //指向右子树的指针
};
typedef struct TreeNode * Node;比如我们现在想要构建一颗像这样的二叉树:
首先我们需要创建好这几个结点:
int main(){
Node a = malloc(sizeof(struct TreeNode)); //依次创建好这五个结点
Node b = malloc(sizeof(struct TreeNode));
Node c = malloc(sizeof(struct TreeNode));
Node d = malloc(sizeof(struct TreeNode));
Node e = malloc(sizeof(struct TreeNode));
a->element = 'A';
b->element = 'B';
c->element = 'C';
d->element = 'D';
e->element = 'E';
}接着我们从最上面开始,挨着进行连接,首先是A这个结点:
int main(){
...
a->left = b; //A的左孩子是B
a->right = c; //A的右孩子是C
}然后是B这个结点:
int main(){
...
b->left = d; //B的左孩子是D
b->right = e; //B的右孩子是E
//别忘了把其他的结点改为NULL
...
}这样的话,我们就成功构建好了这棵二叉树:
int main(){
...
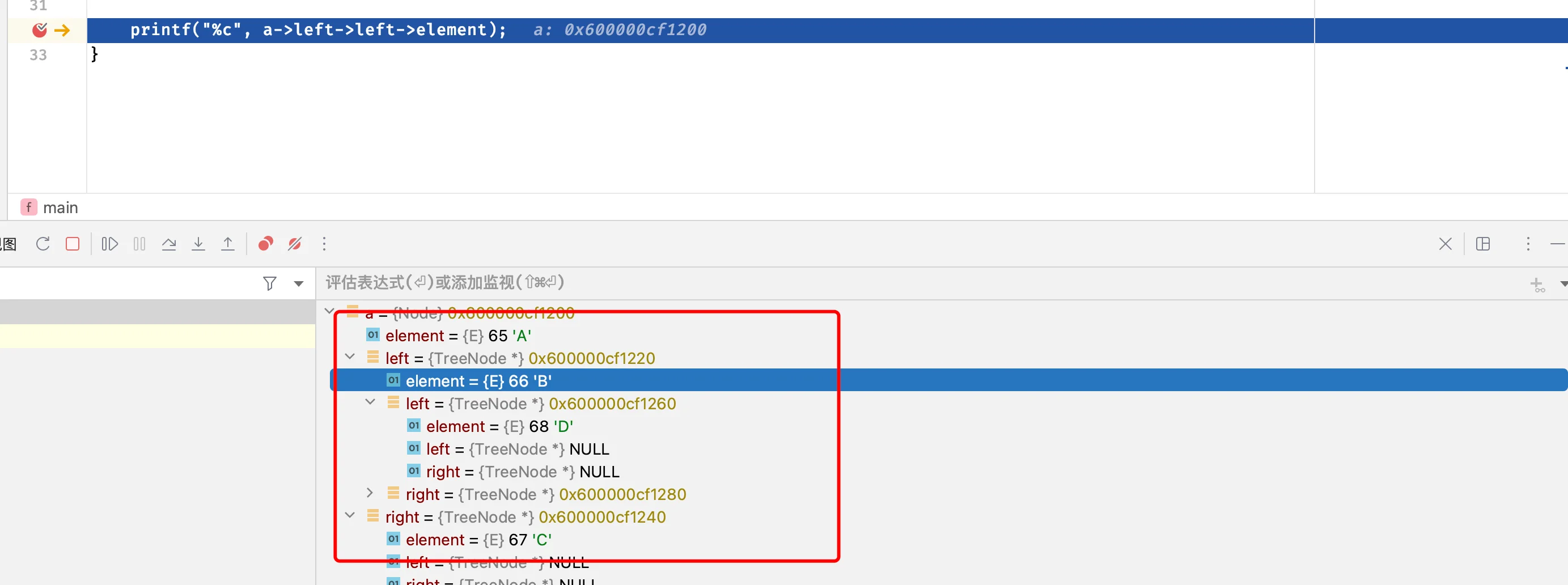
printf("%c", a->left->left->element); //比如现在我想要获取A左孩子的左孩子,那么就可以直接left二连
}断点调试也可以看的很清楚:
二叉树的遍历
遍历定义
指按某条搜索路线遍访每个结点且不重复(又称周游)。
遍历用途
它是树结构插入、删除、修改、查找和排序运算的前提,是二叉树一切运算的基础和核心。
遍历方法
牢记一种约定,对每个结点的查看都是“先左后右” 。
限定先左后右,树的遍历有三种实现方案:

DLR — 先序遍历,即先根再左再右
LDR — 中序遍历,即先左再根再右
LRD — 后序遍历,即先左再右再根
注:“先、中、后”的意思是指访问的结点D是先于子树出现还是后于子树出现。
首先我们来看最简单的前序遍历:
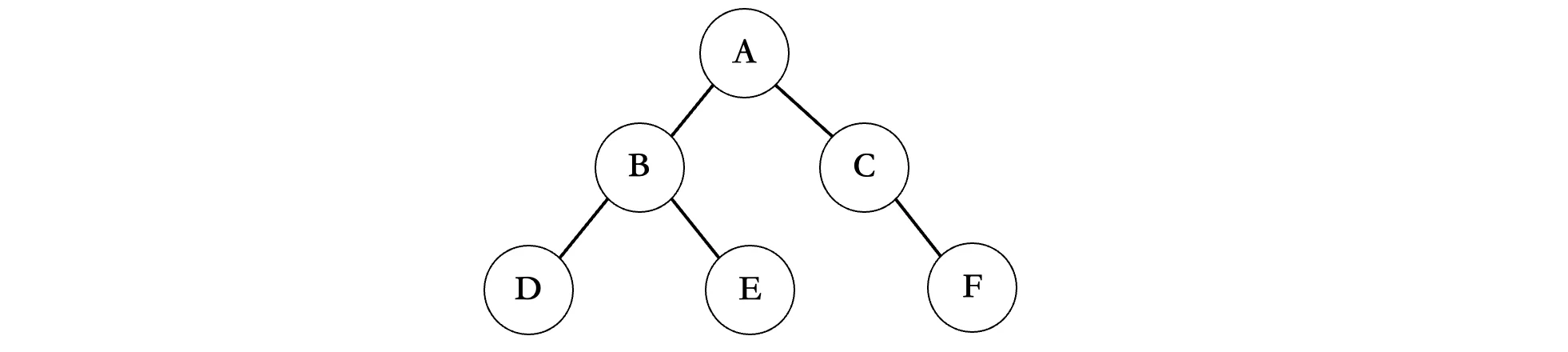
前序遍历是一种勇往直前的态度,走到哪就遍历到那里,先走左边再走右边,比如上面的这个图,首先会从根节点开始:
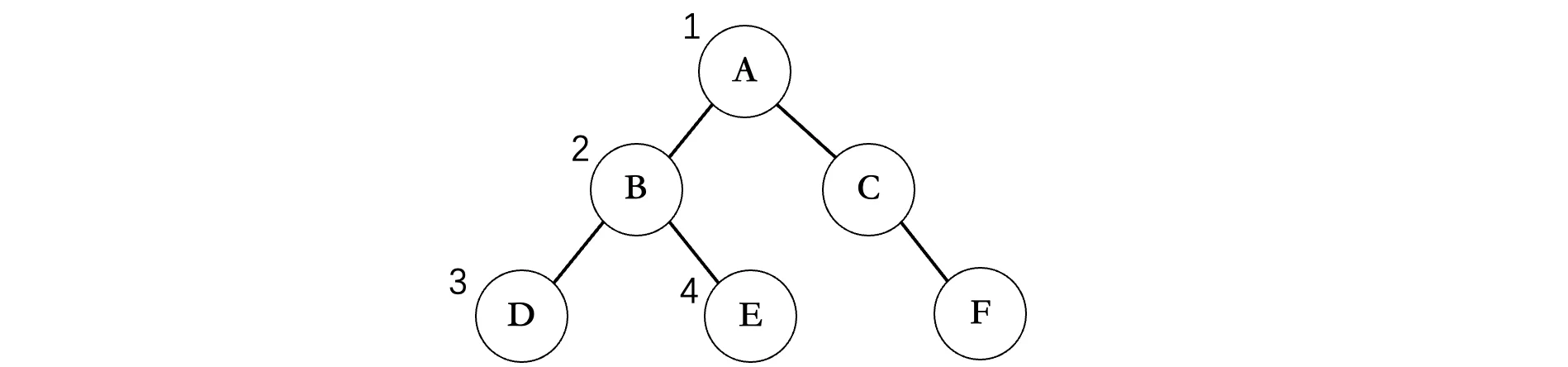
从A开始,先左后右,那么下一个就是B,然后继续走左边,是D,现在ABD走完之后,B的左边结束了,那么就要开始B的右边了,所以下一个是E,E结束之后,现在A的左子树已经全部遍历完成了,然后就是右边,接着就是C,C没有左子树了,那么只能走右边了,最后输出F,所以上面这个二叉树的前序遍历结果为:ABDECF
- 打印根节点
- 前序遍历左子树
- 前序遍历右子树
我们不难发现规律,整棵二叉树(包括子树)的根节点一定是出现在最前面的,比如A在最前面,A的左子树根结点B也是在最前面的。
接着我们来通过代码实现一下,首先先把咱们这棵二叉树组装好:
int main(){
Node a = malloc(sizeof(struct TreeNode));
Node b = malloc(sizeof(struct TreeNode));
Node c = malloc(sizeof(struct TreeNode));
Node d = malloc(sizeof(struct TreeNode));
Node e = malloc(sizeof(struct TreeNode));
Node f = malloc(sizeof(struct TreeNode));
a->element = 'A';
b->element = 'B';
c->element = 'C';
d->element = 'D';
e->element = 'E';
f->element = 'F';
a->left = b;
a->right = c;
b->left = d;
b->right = e;
c->right = f;
c->left = NULL;
d->left = e->right = NULL;
e->left = e->right = NULL;
f->left = f->right = NULL;
}组装好之后,我们来实现一下前序遍历的函数:
void preOrder(Node root){ //传入的是二叉树的根结点
}那么现在我们拿到根结点之后该怎么去写呢?既然是走到哪里打印到哪里,那么我们就先打印一下当前结点的值:
void preOrder(Node root){
printf("%c", root->element); //不多bb先打印再说
}打印完成之后,我们就按照先左后右的规则往后遍历下一个结点,这里我们就直接使用递归来完成:
void preOrder(Node root){
printf("%c", root->element);
preOrder(root->left); //将左孩子结点递归交给下一级
preOrder(root->right); //等上面的一系列向左递归结束后,再以同样的方式去到右边
}不过还没,我们的递归肯定是需要一个终止条件的,不可能无限地进行下去,如果已经走到底了,那么就不能再往下走了,所以:
void preOrder(Node root){
if(root == NULL) return; //如果走到NULL了,那就表示已经到头了,直接返回
printf("%c", root->element);
preOrder(root->left);
preOrder(root->right);
}最后我们来测试一下吧:
int main(){
...
preOrder(a);
}可以看到结果为:

这样我们就通过一个简单的递归操作完成了对一棵二叉树的前序遍历,如果不太好理解,建议结合调试进行观察。
当然也有非递归的写法,我们使用循环,但是就比较麻烦了,我们需要使用栈来帮助我们完成(实际上递归写法本质上也是在利用栈),我们依然是从第一个结点开始,先走左边,每向下走一步,先输出节点的值,然后将对应的结点丢到栈中,当走到尽头时,表示左子树已经遍历完成,接着就是从栈中依次取出栈顶节点,如果栈顶结点有右子树,那么再按照同样的方式遍历其右子树,重复执行上述操作,直到栈清空为止。
- 一路向左,不断入栈,直到尽头
- 到达尽头后,出栈,看看有没有右子树,如果没有就继续出栈,直到遇到有右子树的为止
- 拿到右子树后,从右子树开始,重复上述步骤,直到栈清空
比如我们还是以上面的这棵树为例:
首先我们依然从根结点A出发,不断遍历左子树,沿途打印结果并将节点丢进栈中:

当遍历到D结点时,没有左子树了,此时将栈顶结点D出栈,发现没有右节点,继续出栈,得到B结点,接着得到当前结点的右孩子E结点,然后重复上述步骤:

接着发现E也没有左子树了,同样的,又开始出栈,此时E没有右子树,接着看A,A有右子树,所以继续从C开始,重复上述步骤:

由于C之后没有左子树,那么就出栈获取右子树,此时得到结点F,继续重复上述步骤:

最后F出栈,没有右子树了,栈空,结束。
按照这个思路,我们来编写一下程序吧:
typedef char E;
struct TreeNode {
E element;
struct TreeNode * left;
struct TreeNode * right;
};
typedef struct TreeNode * Node;
//------------- 栈 -------------------
typedef Node T; //这里栈内元素类型定义为上面的Node,也就是二叉树结点指针
struct StackNode {
T element;
struct StackNode * next;
};
typedef struct StackNode * SNode; //这里就命名为SNode,不然跟上面冲突了就不好了
void initStack(SNode head){
head->next = NULL;
}
_Bool pushStack(SNode head, T element){
SNode node = malloc(sizeof(struct StackNode));
if(node == NULL) return 0;
node->next = head->next;
node->element = element;
head->next = node;
return 1;
}
_Bool isEmpty(SNode head){
return head->next == NULL;
}
T popStack(SNode head){
SNode top = head->next;
head->next = head->next->next;
T e = top->element;
free(top);
return e;
}
//-------------------------------------
void preOrder(Node root){
struct StackNode stack; //栈先搞出来
initStack(&stack);
while (root || !isEmpty(&stack)){ //两个条件,只有当栈空并且节点为NULL时才终止循环
while (root) { //按照我们的思路,先不断遍历左子树,直到没有为止
pushStack(&stack, root); //途中每经过一个结点,就将结点丢进栈中
printf("%c", root->element); //然后打印当前结点元素值
root = root->left; //继续遍历下一个左孩子结点
}
root = popStack(&stack); //经过前面的循环,明确左子树全部走完了,接着就是右子树了
root = root->right; //得到右孩子,如果有右孩子,下一轮会重复上面的步骤;如果没有右孩子那么这里的root就被赋值为NULL了,下一轮开始会直接跳过上面的while,继续出栈下一个结点再找右子树
}
}这样,我们就通过非递归的方式实现了前序遍历,可以看到代码是相当复杂的,也不推荐这样编写。
那么前序遍历我们了解完了,接着就是中序遍历了,中序遍历在顺序上与前序遍历不同,前序遍历是走到哪就打印到哪,而中序遍历需要先完成整个左子树的遍历后再打印,然后再遍历其右子树。
我们还是以上面的二叉树为例:
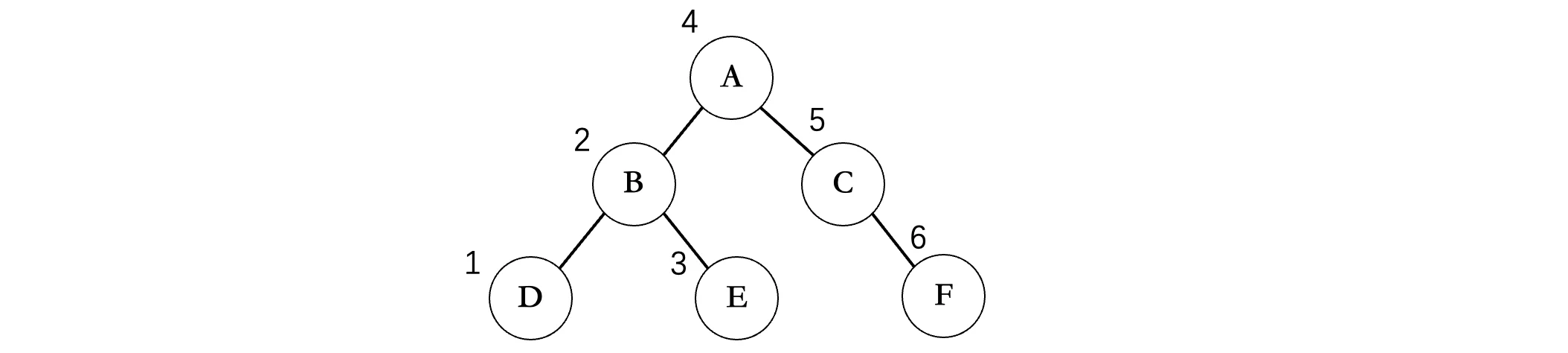
首先需要先不断遍历左子树,走到最底部,但是沿途并不进行打印,而是到底之后,再打印,所以第一个打印的是D,接着由于没有右子树,所以我们回到B,此时再打印B,然后再去看B的右结点E,由于没有左子树和右子树了,所以直接打印E,左边遍历完成,接着回到A,打印A,然后对A的右子树重复上述操作。所以说遍历的基本规则还是一样的,只是打印值的时机发生了改变。
- 中序遍历左子树
- 打印结点
- 中序遍历右子树
所以这棵二叉树的中序遍历结果为:DBEACF,我们可以发现一个规律,就是在某个结点的左子树中所有结点,其中序遍历结果也是按照这样的规律排列的,比如A的左子树中所有结点,中序遍历结果中全部都在A的左边,右子树中所有的结点,全部都在A的右边(这个规律很关键,后面在做一些算法题时会用到)
那么怎么才能将打印调整到左子树全部遍历结束之后呢?其实很简单:
void inOrder(Node root){
if(root == NULL) return;
inOrder(root->left); //先完成全部左子树的遍历
printf("%c", root->element); //等待左子树遍历完成之后再打印
inOrder(root->right); //然后就是对右子树进行遍历
}我们只需要将打印放到左子树遍历之后即可,这样打印出来的结果就是中序遍历的结果了:

同样的,如果采用的是非递归,那么我也只需要稍微改动一个地方即可:
...
void inOrder(Node root){
struct StackNode stack;
initStack(&stack);
while (root || !isEmpty(&stack)){ //其他都不变
while (root) {
pushStack(&stack, root);
root = root->left;
}
root = popStack(&stack);
printf("%c", root->element); //只需要将打印时机延后到左子树遍历完成
root = root->right;
}
}这样,我们就实现了二叉树的中序遍历,实际上还是很好理解的。
接着我们来看一下后序遍历,后序遍历继续将打印的时机延后,需要等待左右子树全部遍历完成,才会去进行打印。
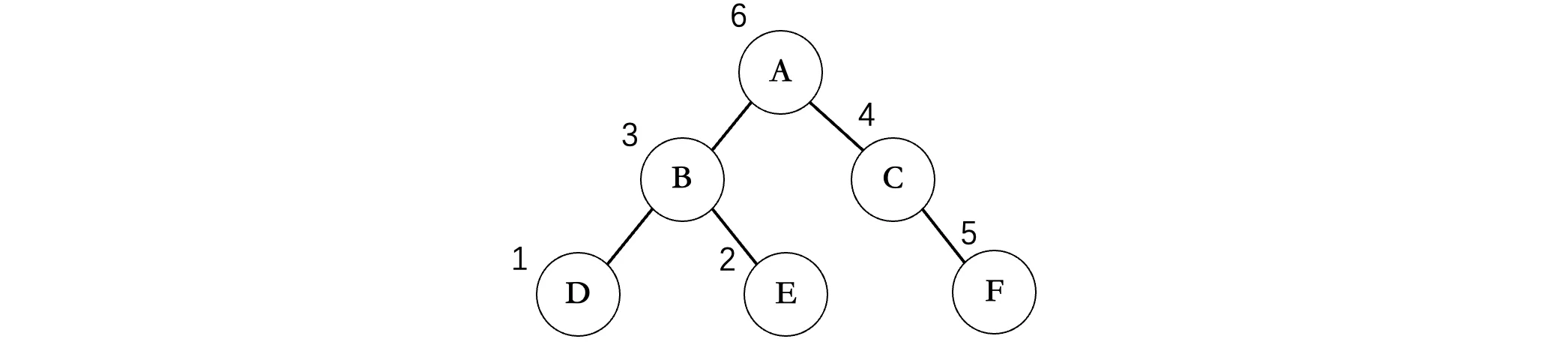
首先还是一路向左,到达结点D,此时结点D没有左子树了,接着看结点D还有没有右子树,发现也没有,左右子树全部遍历完成,那么此时再打印D,同样的,D完事之后就回到B了,此时接着看B的右子树,发现有结点E,重复上述操作,E也打印出来了,接着B的左右子树全部OK,那么再打印B,接着A的左子树就完事了,现在回到A,看到A的右子树,继续重复上述步骤,当A的右子树也遍历结束后,最后再打印A结点。
- 后序遍历左子树
- 后序遍历右子树
- 打印结点
所以最后的遍历顺序为:DEBFCA,不难发现,整棵二叉树(包括子树)根结点一定是在后面的,比如A在所有的结点的后面,B在其子节点D、E的后面,这一点恰恰和前序遍历相反(注意不是得到的结果相反,是规律相反)
所以,按照这个思路,我们来编写一下后序遍历:
void postOrder(Node root){
if(root == NULL) return;
postOrder(root->left);
postOrder(root->right);
printf("%c", root->element); //时机延迟到最后
}结果如下:

不过难点来了,后序遍历使用非递归貌似写不了啊?因为按照我们的之前的思路,最多也就实现中序遍历,我们没办法在一次循环中得知右子树是否完成遍历,难点就在这里。那么我们就要想办法先让右子树完成遍历,由于一个结点需要左子树全部完成+右子树全部完成,而目前只能明确左子树完成了遍历(也就是内层while之后,左子树一定结束了)所以我们可以不急着将结点出栈,而是等待其左右都完事了再出栈,这里我们需要稍微对结点的结构进行修改,添加一个标记变量,来表示已经完成左边还是左右都完成了:
struct TreeNode {
E element;
struct TreeNode * left;
struct TreeNode * right;
int flag; //需要经历左右子树都被遍历才行,这里用flag存一下状态,0表示左子树遍历完成,1表示右子树遍历完成
};
T peekStack(SNode head){ //这里新增一个peek操作,用于获取栈顶元素的值,但是不出栈,仅仅是值获取
return head->next->element;
}
void postOrder(Node root){
struct StackNode stack;
initStack(&stack);
while (root || !isEmpty(&stack)){ //其他都不变
while (root) {
pushStack(&stack, root);
root->flag = 0; //首次入栈时,只能代表左子树遍历完成,所以flag置0
root = root->left;
}
root = peekStack(&stack); //注意这里只是获取到结点,并没有进行出栈操作,因为需要等待右子树遍历完才能出栈
if(root->flag == 0) { //如果仅仅遍历了左子树,那么flag就等于0
root->flag = 1; //此时标记为1表示遍历右子树
root = root->right; //这里跟之前是一样的
} else {
printf("%c", root->element); //当flag为1时走这边,此时左右都遍历完成了,这时再打印值出来
popStack(&stack); //这时再把对应的结点出栈,因为左右都完事了
root = NULL; //置为NULL,下一轮直接跳过while,然后继续取栈中剩余的结点,重复上述操作
}
}
}所以,后序遍历的非递归写法的最大区别是将结点的出栈时机和打印时机都延后了。
最后我们来看层序遍历,实际上这种遍历方式是我们人脑最容易理解的,它是按照每一层在进行遍历:
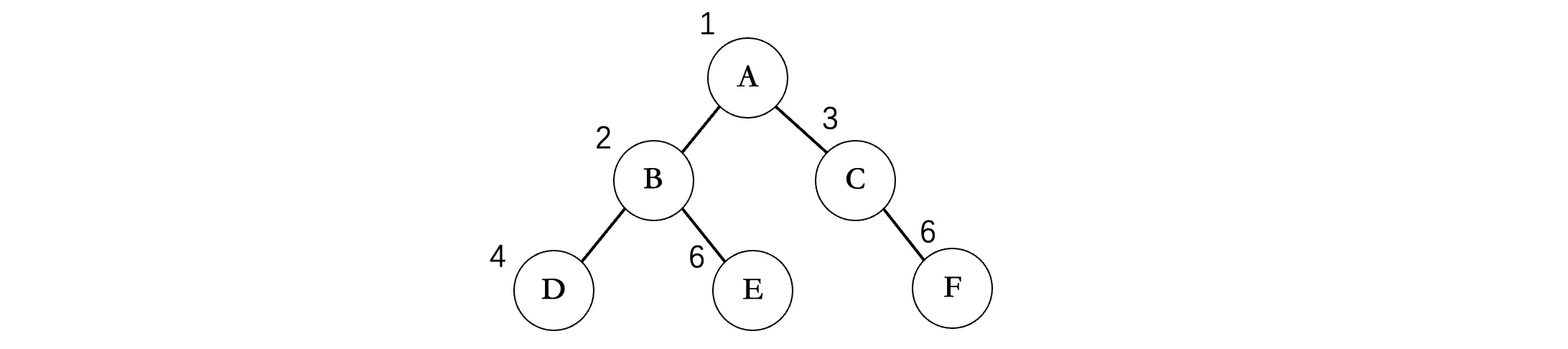
层序遍历实际上就是按照从上往下每一层,从左到右的顺序打印每个结点,比如上面的这棵二叉树,那么层序遍历的结果就是:ABCDEF,像这样一层一层的挨个输出。
虽然理解起来比较简单,但是如果让你编程写出来,该咋搞?是不是感觉有点无从下手?
我们可以利用队列来实现层序遍历,首先将根结点存入队列中,接着循环执行以下步骤:
- 进行出队操作,得到一个结点,并打印结点的值。
- 将此结点的左右孩子结点依次入队。
不断重复以上步骤,直到队列为空。
我们来分析一下,首先肯定一开始A在里面:

接着开始不断重复上面的步骤,首先是将队首元素出队,打印A,然后将A的左右孩子依次入队:

现在队列中有B、C两个结点,继续重复上述操作,B先出队,打印B,然后将B的左右孩子依次入队:

现在队列中有C、D、E这三个结点,继续重复,C出队并打印,然后将F入队:

我们发现,这个过程中,打印的顺序正好就是我们层序遍历的顺序,所以说队列还是非常有用的。
那么现在我们就来上代码吧:
typedef char E;
struct TreeNode {
E element;
struct TreeNode * left;
struct TreeNode * right;
int flag;
};
typedef struct TreeNode * Node;
//--------------- 队列 ----------------
typedef Node T; //还是将Node作为元素
struct QueueNode {
T element;
struct QueueNode * next;
};
typedef struct QueueNode * QNode;
struct Queue{
QNode front, rear;
};
typedef struct Queue * LinkedQueue;
_Bool initQueue(LinkedQueue queue){
QNode node = malloc(sizeof(struct QueueNode));
if(node == NULL) return 0;
queue->front = queue->rear = node;
return 1;
}
_Bool offerQueue(LinkedQueue queue, T element){
QNode node = malloc(sizeof(struct QueueNode));
if(node == NULL) return 0;
node->element = element;
queue->rear->next = node;
queue->rear = node;
return 1;
}
_Bool isEmpty(LinkedQueue queue){
return queue->front == queue->rear;
}
T pollQueue(LinkedQueue queue){
T e = queue->front->next->element;
QNode node = queue->front->next;
queue->front->next = queue->front->next->next;
if(queue->rear == node) queue->rear = queue->front;
free(node);
return e;
}
//--------------------------------
void levelOrder(Node root){
struct Queue queue; //先搞一个队列
initQueue(&queue);
offerQueue(&queue, root); //先把根节点入队
while (!isEmpty(&queue)) { //不断重复,直到队列空为止
Node node = pollQueue(&queue); //出队一个元素,打印值
printf("%c", node->element);
if(node->left) //如果存在左右孩子的话
offerQueue(&queue, node->left); //记得将左右孩子入队,注意顺序,先左后右
if(node->right)
offerQueue(&queue, node->right);
}
}可以看到结果就是层序遍历的结果:

当然,使用递归也可以实现,但是需要单独存放结果然后单独输出,不是很方便,所以说这里就不演示了。
二叉树练习题:
现在有一棵二叉树前序遍历结果为:ABCDE,中序遍历结果为:BADCE,那么请问该二叉树的后序遍历结果为?
对二叉树的结点从1开始连续进行编号,要求每个结点的编号大于其左右孩子的编号,那么请问需要采用哪种遍历方式来实现?
A. 前序遍历 B. 中序遍历 C. 后序遍历 D. 层序遍历
编程实践
计算叶子节点数目
计算高度(深度)
思想:
求根结点左子树高度,根结点右子树高度,比较的子树最大高度,再+1。
若左子树还是树,重复步骤1;若右子树还是树,重复步骤1。
编程实现
int height(struct TriTNode *root){
if(root ==NULL){
return 0;
}
int lheight = height(root->lchild);
int rheight = height(root->rchild);
int height = lheight > rheight ? leight +1 : rheight +1;
return height;
}拷贝二叉树
思想:
malloc新结点,
拷贝左子树,拷贝右子树,让新结点连接左子树,右子树。
若左子树还是树,重复步骤1、2;若右子树还是树,重复步骤1、2。
编程实现
struct TriTNode * copy(struct TriTNode *root){
if(root ==NULL){
return NULL;
}
struct TriTNode *lnode = copy(root->lchild);
struct TriTNode *rnode = copy(root->rchild);
struct TriTNode *newnode = malloc(struct TriTNode);
newnode->data = root->data;
newnode->lchild = lnode;
newnode->rchild = rnode;
return newnode;
}非递归遍历
利用栈容器可以实现二叉树的非递归遍历
首先将每个节点都设置一个标志,默认标志为假,根据节点的的状态进行如下流程。

执行上述流程,可以得到先序遍历的结果,如果想得到其他二叉树遍历结果,修改2.4步骤即可。
//节点结构体定义
struct TriTNode{
void *data;
struct TriTNode *lchild;
struct TriTNode *rchild;
//在结构体内设置一个标志位
int flags;
};线索化二叉树
前面我们学习了二叉树,我们知道一棵二叉树实际上可以由多个结点组成,每个结点都有一个左右指针,指向其左右孩子。我们在最后也讲解了二叉树的遍历,包括前序、中序、后序以及层序遍历。只不过在遍历时实在是太麻烦了,我们需要借助栈来帮助我们完成这项遍历操作。
实际上我们发现,一棵二叉树的某些结点会存在NULL的情况,我们可以利用这些为NULL的指针,将其线索化为某一种顺序遍历的指向下一个按顺序的结点的指针,这样我们在进行遍历的时候,就会很方便了。
例如,一棵二叉树的前序遍历顺序如下:
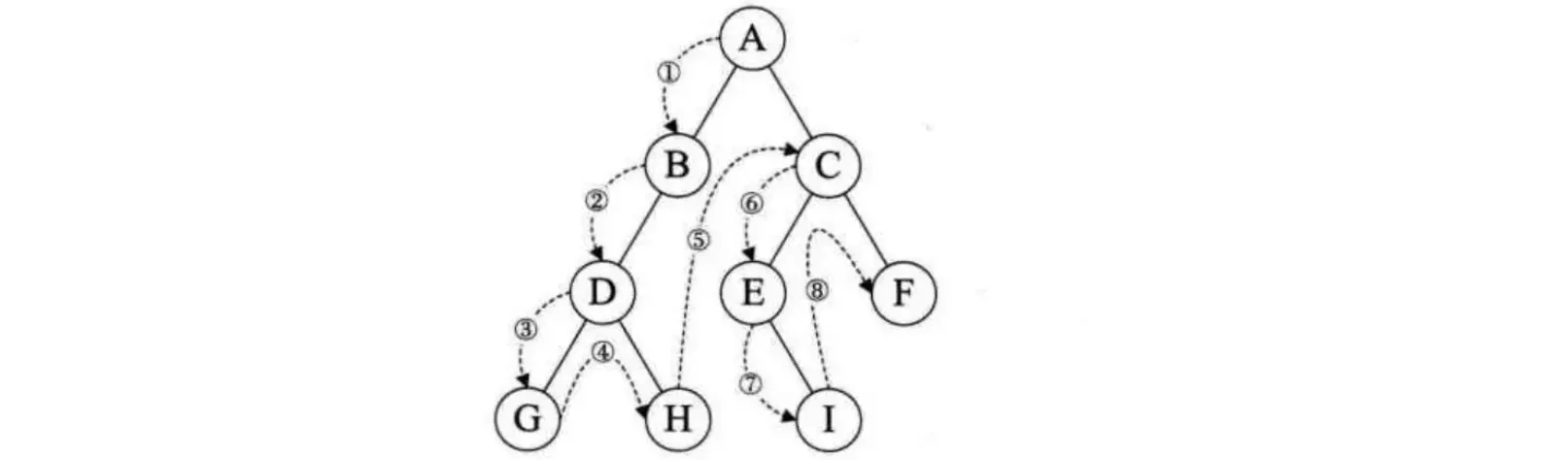
我们就可以将其进行线索化,首先还是按照前序遍历的顺序依次寻找:
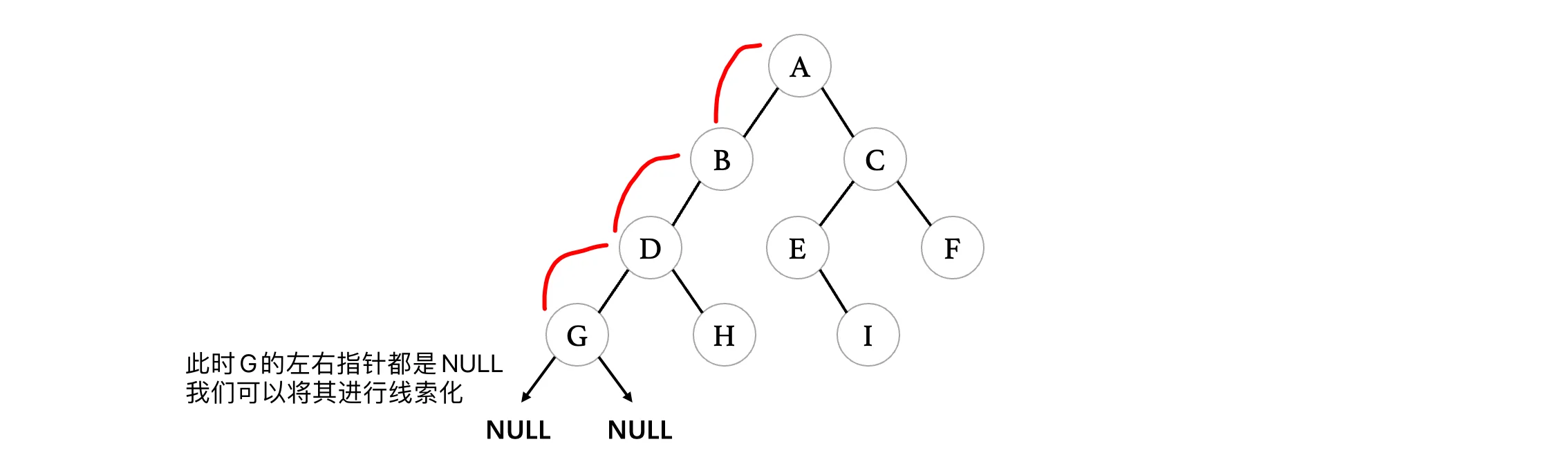
线索化的规则为:
- 结点的左指针,指向其当前遍历顺序的前驱结点。
- 结点的右指针,指向其当前遍历顺序的后继结点。
所以在线索化之后,G的指向情况如下:
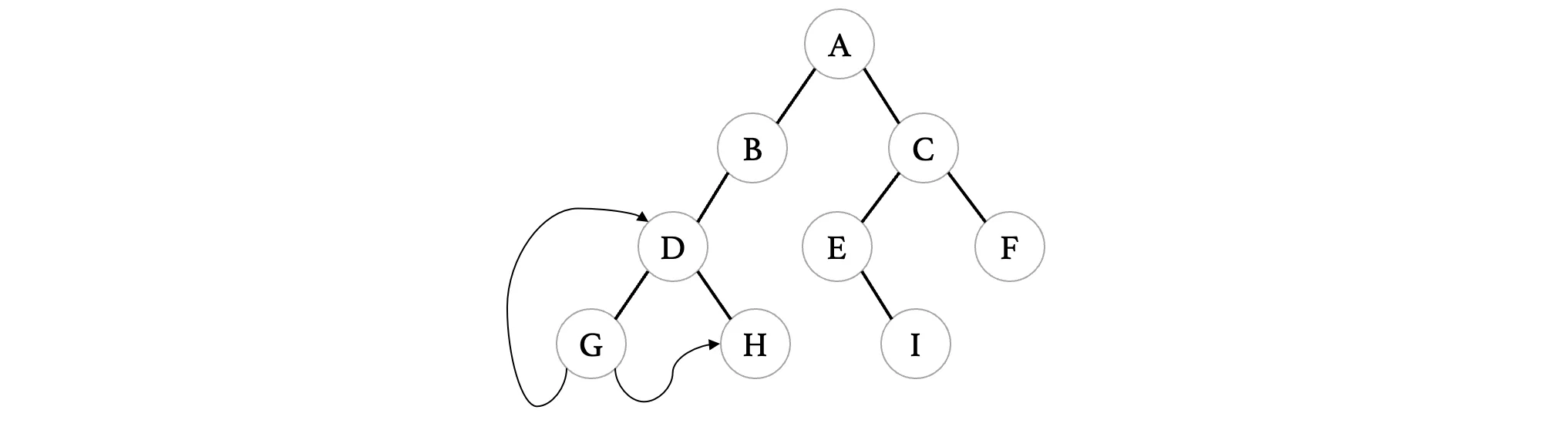
这样,G原本两个为NULL的指针就被我们利用起来了,但是现在有一个问题,我们怎么知道,某个结点的指针到底是指向的其左右孩子,还是说某种遍历顺序下的前驱或是后继结点呢?所以,我们还需要分别为左右添加一个标志位,来表示左右指针到底指向的是孩子还是遍历线索:
typedef char E;
typedef struct TreeNode {
E element;
struct TreeNode * left;
struct TreeNode * right;
int leftTag, rightTag; //标志位,如果为1表示这一边指针指向的是线索,不为1就是正常的孩子结点
} * Node;接着是H结点,同样的,因为H结点的左右指针都是NULL,那么我们也可以将其线索化:
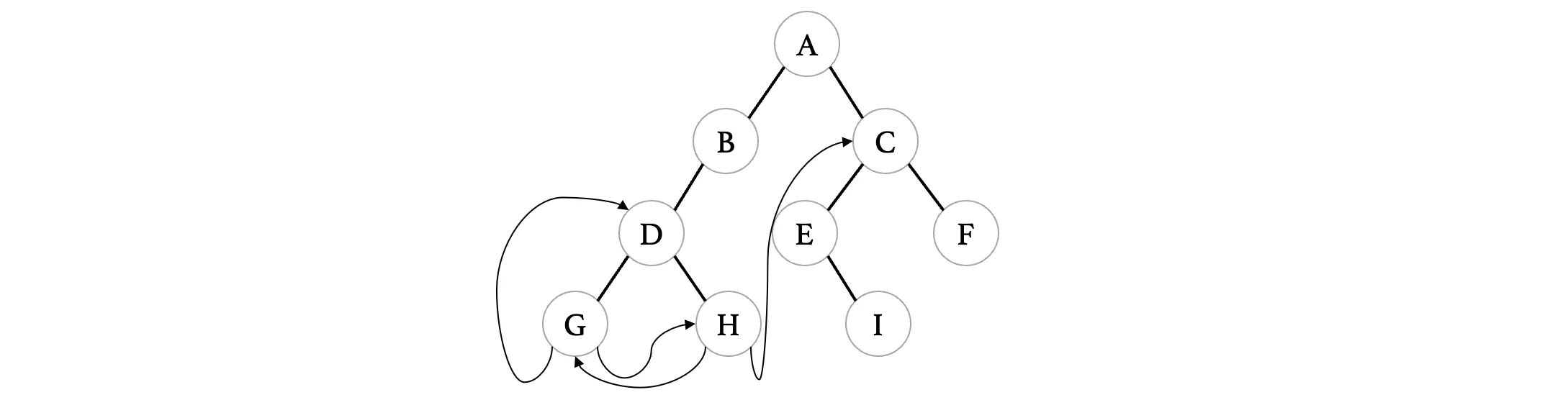
接着我们来看结点E,这个结点只有一个右孩子,没有左孩子,左孩子指针为NULL,我们也可以将其线索化:
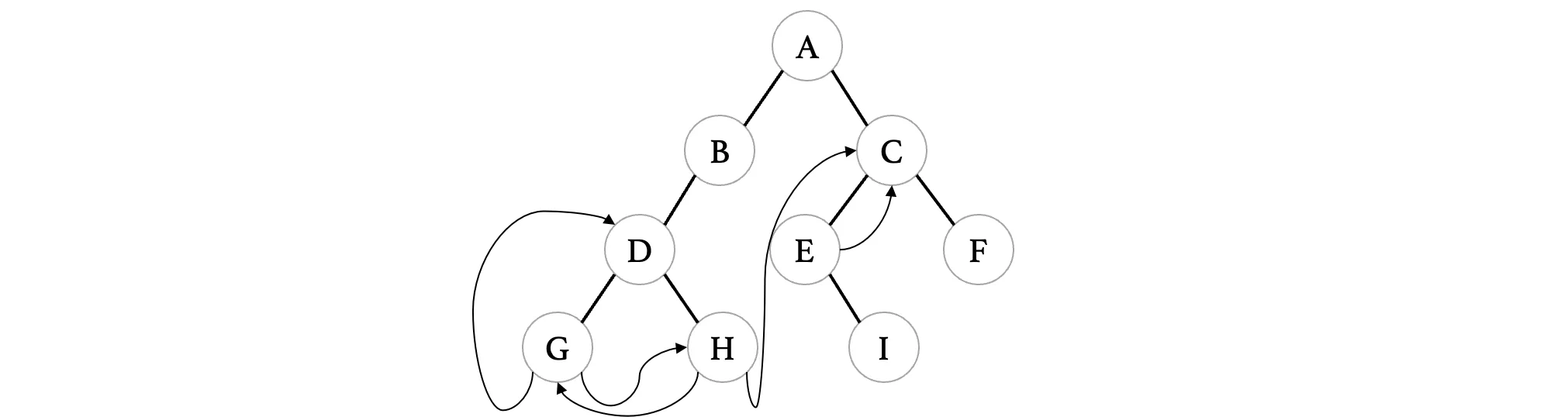
最后,整棵二叉树完成线索化之后,除了遍历顺序的最后一个结点没有后续之外,其他为NULL的指针都被利用起来了:
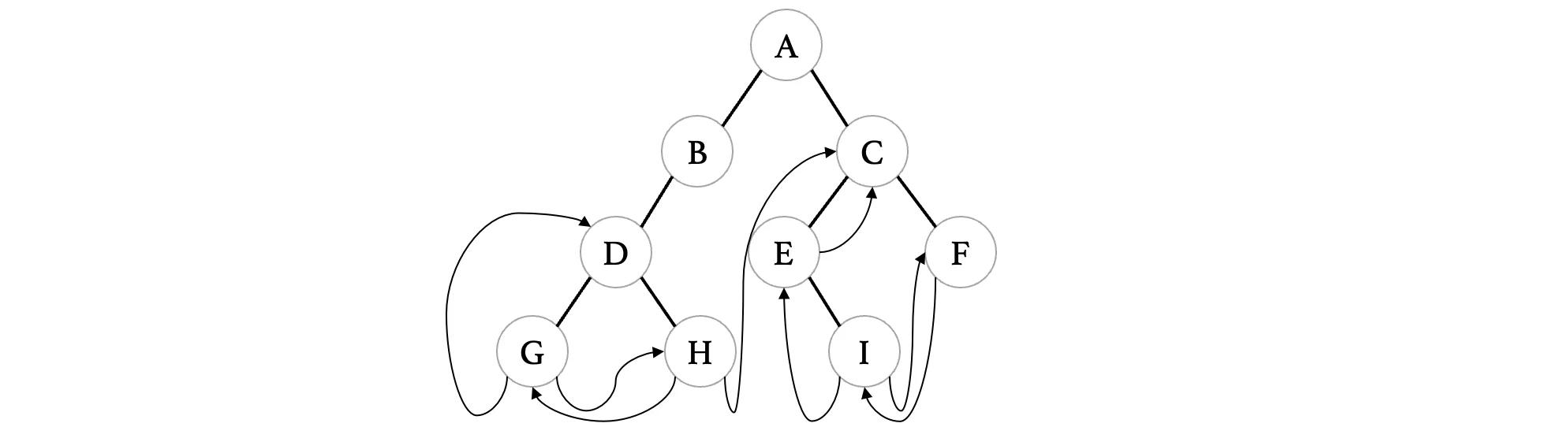
我们可以发现,在利用上那些为NULL的指针之后,当我们再次进行前序遍历时,我们不需要再借助栈了,而是可以一路向前。
这里我们弄一个简单一点的线索化二叉树,来尝试对其进行遍历:
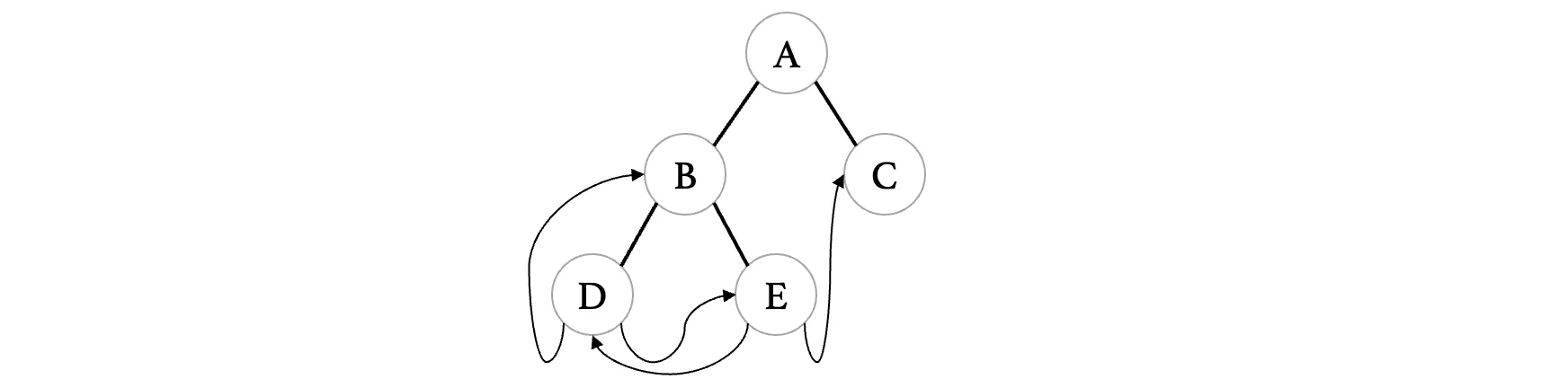
首先我们要对这棵二叉树进行线索化,将其变成一棵线索化二叉树:
Node createNode(E element){ //单独写了个函数来创建结点
Node node = malloc(sizeof(struct TreeNode));
node->left = node->right = NULL;
node->rightTag = node->leftTag = 0;
node->element = element;
return node;
}
int main() {
Node a = createNode('A');
Node b = createNode('B');
Node c = createNode('C');
Node d = createNode('D');
Node e = createNode('E');
a->left = b;
b->left = d;
a->right = c;
b->right = e;
}实际上要将其进行线索化,我们只需要正常按照对应的遍历顺序进行即可,不过在遍历过程中需要留意那些存在空指针的结点,我们需要修改其指针的指向:
void preOrderThreaded(Node root){ //前序遍历线索化函数
if(root == NULL) return;
//别急着写打印
preOrderThreaded(root->left);
preOrderThreaded(root->right);
}首先还是老规矩,先把前序遍历写出来,然后我们需要进行判断,如果存在指针指向为NULL,那么就将其线索化:
Node pre = NULL; //这里我们需要一个pre来保存后续结点的指向
void preOrderThreaded(Node root){ //前序遍历线索化函数
if(root == NULL) return;
if(root->left == NULL) { //首先判断当前结点左边是否为NULL,如果是,那么指向上一个结点
root->left = pre;
root->leftTag = 1; //记得修改标记
}
if(pre && pre->right == NULL) { //然后是判断上一个结点的右边是否为NULL,如果是那么进行线索化,指向当前结点
pre->right = root;
pre->rightTag = 1; //记得修改标记
}
pre = root; //每遍历完一个,需要更新一下pre,表示上一个遍历的结点
if(root->leftTag == 0) //注意只有标志位是0才可以继续向下,否则就是线索了
preOrderThreaded(root->left);
if(root->rightTag == 0)
preOrderThreaded(root->right);
}这样,在我们进行二叉树的遍历时,会自动将其线索化,线索化完成之后就是一棵线索化二叉树了。
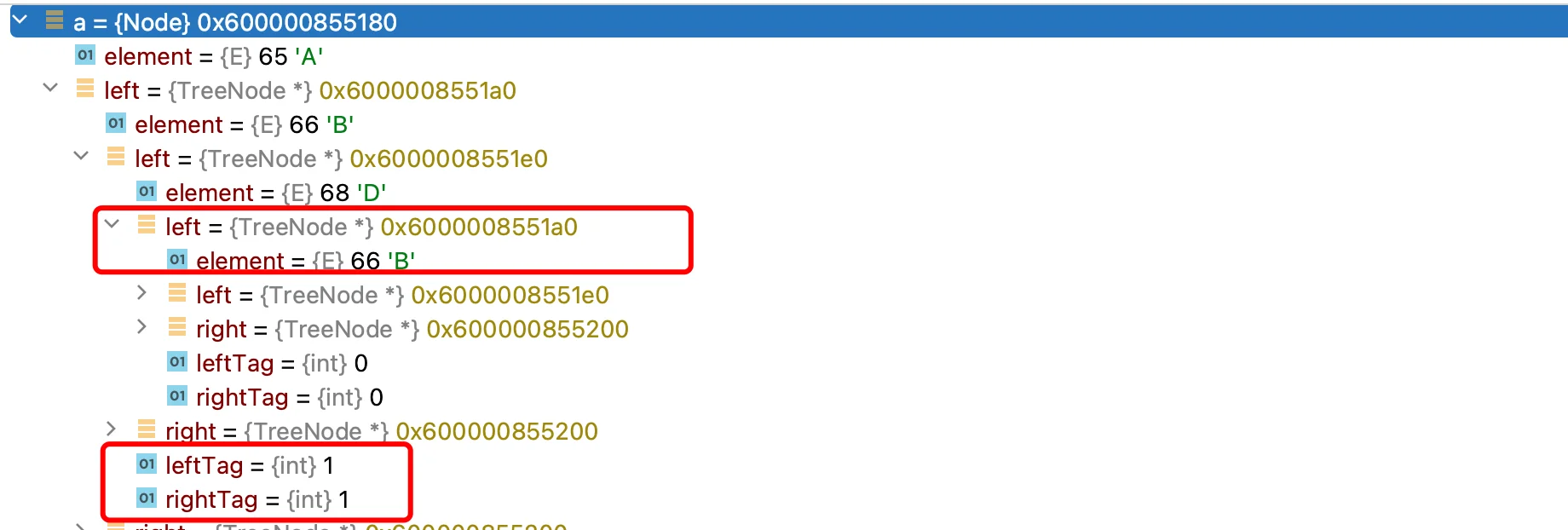
可以看到结点D的左右标记都是1,说明都被线索化了,并且D的左边指向的是其前一个结点B,右边指向的是后一个结点E,这样我们就成功将其线索化了。
现在我们成功得到了一棵线索化之后的二叉树,那么怎么对其进行遍历呢?我们只需要一个简单的循环就可以了:
void preOrder(Node root){ //前序遍历一棵线索化二叉树非常简单
while (root) { //到头为止
printf("%c", root->element); //因为是前序遍历,所以直接按顺序打印就行了
if(root->leftTag == 0)
root = root->left; //如果是左孩子,那么就走左边
else
root = root->right; //如果左边指向的不是孩子,而是线索,那么就直接走右边,因为右边无论是线索还是孩子,都要往这边走了
}
}我们接着来看看中序遍历的线索化二叉树,整个线索化过程我们只需要稍微调整位置就行了:
Node pre = NULL; //这里我们需要一个pre来保存后续结点的指向
void inOrderThreaded(Node root){ //前序遍历线索化函数
if(root == NULL) return;
if(root->leftTag == 0)
inOrderThreaded(root->left);
//------ 线索化 ------- 现在放到中间去,其他的还是一样的
if(root->left == NULL) {
root->left = pre;
root->leftTag = 1;
}
if(pre && pre->right == NULL) {
pre->right = root;
pre->rightTag = 1;
}
pre = root;
//--------------------
if(root->rightTag == 0)
inOrderThreaded(root->right);
}最后我们线索化完成之后,长这样了:
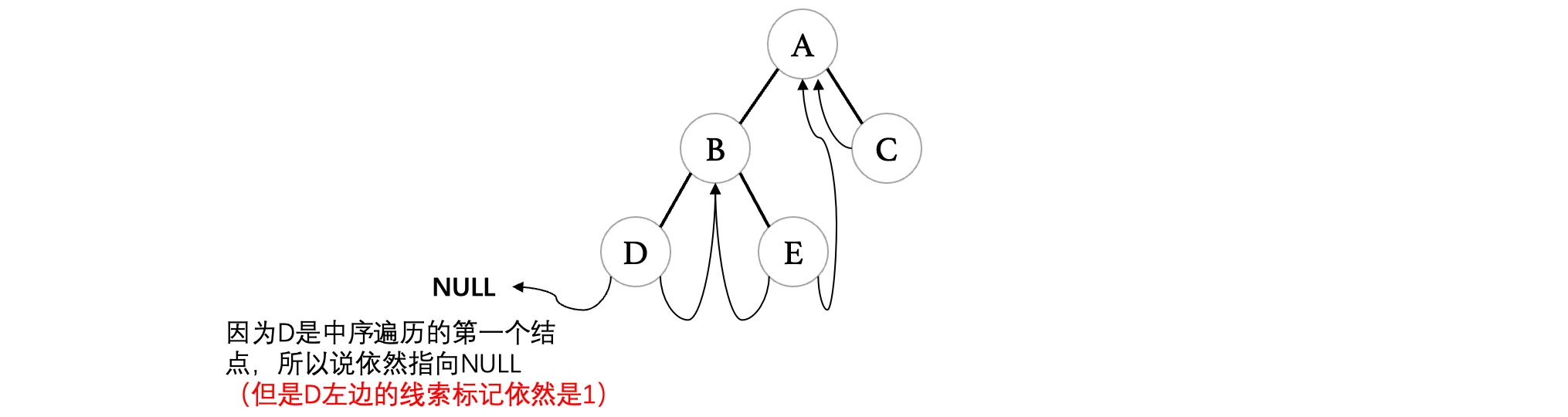
那么像这样的一棵树,我们怎么对其进行遍历呢?中序遍历要稍微麻烦一些:
void inOrder(Node root){
while (root) { //因为中序遍历需要先完成左边,所以说要先走到最左边才行
while (root && root->leftTag == 0) //如果左边一直都不是线索,那么就一直往左找,直到找到一个左边是线索的为止,表示到头了
root = root->left;
printf("%c", root->element); //到最左边了再打印,中序开始
while (root && root->rightTag == 1) { //打印完就该右边了,右边如果是线索化之后的结果,表示是下一个结点,那么就一路向前,直到不是为止
root = root->right;
printf("%c", root->element); //注意按着线索往下就是中序的结果,所以说沿途需要打印
}
root = root->right; //最后继续从右结点开始,重复上述操作
}
}最后我们来看看后序遍历的线索化,同样的,我们只需要在线索化时修改为后序就行了
Node pre = NULL; //这里我们需要一个pre来保存后续结点的指向
void inOrderThreaded(Node root){ //前序遍历线索化函数
if(root == NULL) return;
if(root->leftTag == 0)
inOrderThreaded(root->left);
if(root->rightTag == 0)
inOrderThreaded(root->right);
//------ 线索化 ------- 现在这一坨移到最后,就是后序遍历的线索化了
if(root->left == NULL) {
root->left = pre;
root->leftTag = 1;
}
if(pre && pre->right == NULL) {
pre->right = root;
pre->rightTag = 1;
}
pre = root;
//--------------------
}线索化完成之后,变成一棵后续线索化二叉树:
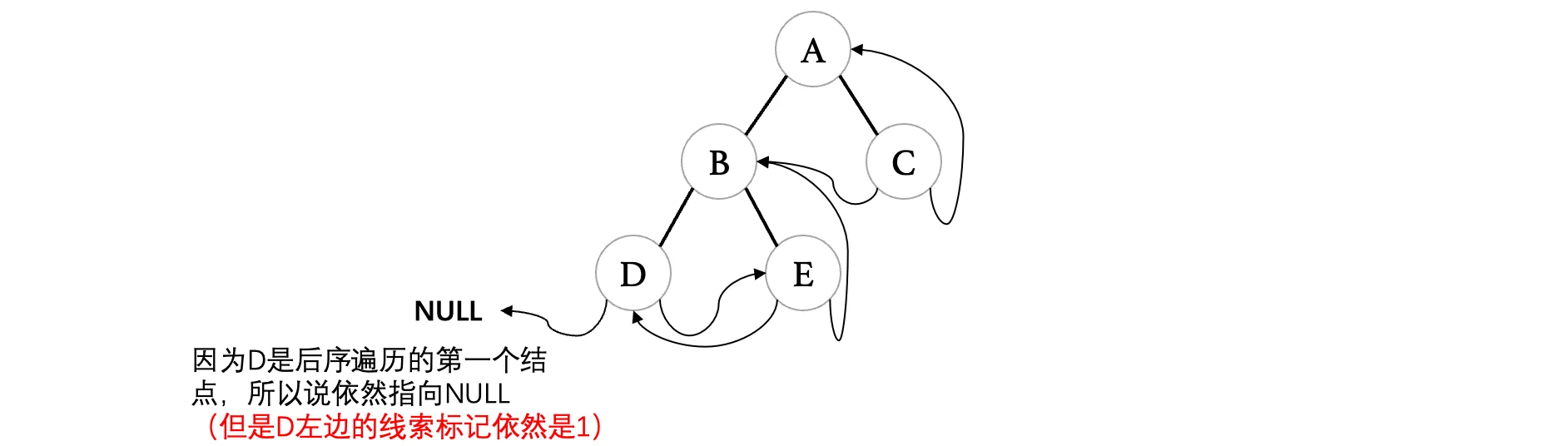
后序遍历的结果看起来有点怪怪的,但是这就是后序,那么怎么对这棵线索化二叉树进行后续遍历呢?这就比较复杂了。首先后续遍历需要先完成左右,左边还好说,关键是右边,右边完事之后我们并不一定能找到对应子树的根结点,比如我们按照上面的线索,先从D开始,根据线索找到E,然后继续跟据线索找到B,但是此时B无法找到其兄弟结点C,所以说这样是行不通的,因此要完成后续遍历,我们只能对结点进行改造:
typedef struct TreeNode {
E element;
struct TreeNode * left;
struct TreeNode * right;
struct TreeNode * parent; //指向双亲(父)结点
int leftTag, rightTag;
} * Node;现在每个结点都保存其父结点,这样就可以顺利地找上去了。现在我们来编写一下吧:
Node pre = NULL; //这里我们需要一个pre来保存后续结点的指向
void postOrderThreaded(Node root){ //前序遍历线索化函数
if(root == NULL) return;
if(root->leftTag == 0) {
postOrderThreaded(root->left);
if(root->left) root->left->parent = root; //左边完事之后,如果不为空,那么就设定父子关系
}
if(root->rightTag == 0) {
postOrderThreaded(root->right);
if(root->right) root->right->parent = root; //右边完事之后,如果不为空,那么就设定父子关系
}
//------ 线索化 -------
if(root->left == NULL) {
root->left = pre;
root->leftTag = 1;
}
if(pre && pre->right == NULL) {
pre->right = root;
pre->rightTag = 1;
}
pre = root;
//--------------------
}后序遍历代码如下:
void postOrder(Node root){
Node last = NULL, node = root; //这里需要两个暂存指针,一个记录上一次遍历的结点,还有一个从root开始
while (node) {
while (node->left != last && node->leftTag == 0) //依然是从整棵树最左边结点开始,和前面一样,只不过这里加入了防无限循环机制,看到下面就知道了
node = node->left;
while (node && node->rightTag == 1) { //左边完了还有右边,如果右边是线索,那么直接一路向前,也是跟前面一样的
printf("%c", node->element); //沿途打印
last = node;
node = node->right;
}
if (node == root && node->right == last) {
//上面的操作完成之后,那么当前结点左右就结束了,此时就要去寻找其兄弟结点了,我们可以
//直接通过parent拿到兄弟结点,但是如果当前结点是根结点,需要特殊处理,因为根结点没有父结点了
printf("%c", node->element);
return; //根节点一定是最后一个,所以说直接返回就完事
}
while (node && node->right == last) { //如果当前结点的右孩子就是上一个遍历的结点,那么一直向前就行
printf("%c", node->element); //直接打印当前结点
last = node;
node = node->parent;
}
//到这里只有一种情况了,是从左子树上来的,那么当前结点的右边要么是线索要么是右子树,所以直接向右就完事
if(node && node->rightTag == 0) { //如果不是线索,那就先走右边,如果是,等到下一轮再说
node = node->right;
}
}
}至此,有关线索化二叉树,我们就讲解到这样。