B树和B+树
前面我们介绍了多种多样的二叉树,有线索化二叉树,平衡二叉树等等,这些改造版二叉树无疑都是为了提高我们的程序运行效率而生的,我们接着来看一种同样为了提升效率的树结构。
这里首先介绍一下B树(Balance Tree),它是专门为磁盘数据读取设计的一种度为 m 的查找树(多用于数据库)它同样是一棵平衡树,但是不仅限于二叉了,之前我们介绍的这些的二叉树都是基于内存读取的优化,磁盘读取速度更慢,它同样需要优化,一棵度为4的(4阶)B树大概长这样:
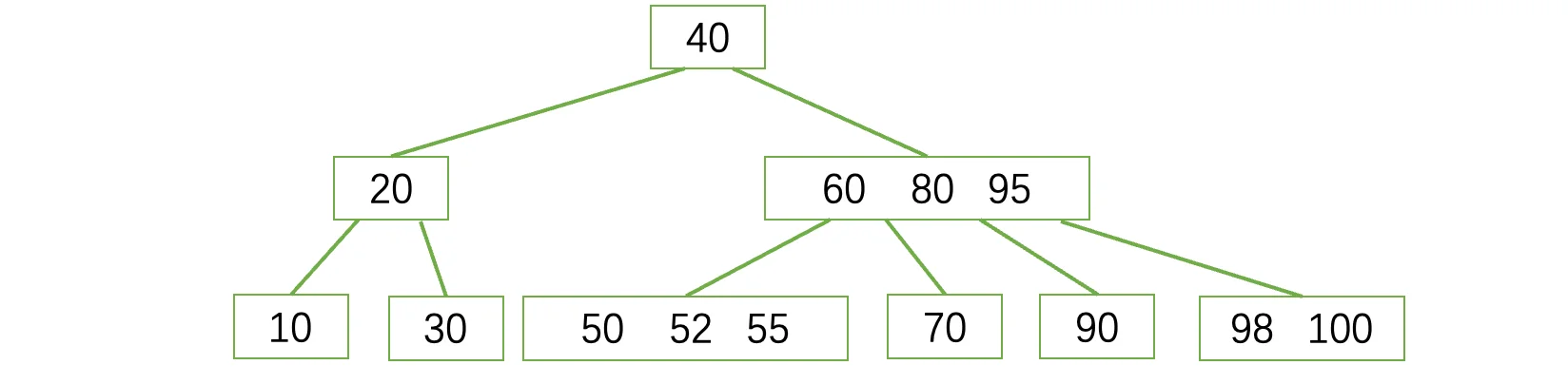
第一眼看上去,感觉好像没啥头绪,不能发现啥规律,但是只要你仔细观察,你会发现,它和二叉查找树很相似,左边的一定比根节点小,右边的一定比根节点大,并且我们发现,每个结点现在可以保存多个值,每个结点可以连接多个子树,这些值两两组合划分了一些区间,比如60左边,一定是比60小的,60和80之间那么就是大于60小于80的值,以此类推,所以值有N个,就可以划分出N+1个区间,那么子树最多就可以有N+1个。它的详细规则如下:
- 树中每个结点最多含有m个孩子(m >= 2)比如上面就是m为4的4阶B树,最多有4个孩子。
- 除根结点和叶子结点外,其它每个结点至少有⌈m/2⌉个孩子,同理键值数量至少有⌈m/2⌉-1个。
- 若根结点不是叶子结点,则至少有2个孩子。
- 所有叶子结点都出现在同一层。
- 一个结点的包含多种信息(P0,K1,P1,K2,…,Kn,Pn),其中P为指向子树的指针,K为键值(关键字)
- Ki (i=1...n)为键值,也就是每个结点保存的值,且键值按顺序升序排序K(i-1)< Ki
- Pi为指向子树的指针,且指针Pi指向的子树中所有结点的键值均小于Ki,但都大于K(i-1)
- 键值的个数n必须满足: ⌈m/2⌉-1 <= n <= m-1
在线动画网站:https://www.cs.usfca.edu/~galles/visualization/BTree.html
是不是感觉怎么要求这么多呢?我们通过感受一下B树的插入和删除就知道了,首先是B树的插入操作,这里我们以度为3的B树为例:

插入1之后,只有一个结点,我们接着插入一个2,插入元素满足以下规则:
- 如果该节点上的元素数未满,则将新元素插入到该节点,并保持节点中元素的顺序。
所以,直接放进去就行,注意顺序:

接着我们再插入一个3进去,但是此时因为度为3,那么键值最多只能有两个,肯定是装不下了:
- 如果该节点上的元素已满,则需要将该节点平均地分裂成两个节点:
- 首先从该节点中的所有元素和新元素中先出一个中位数作为分割值。
- 小于中位数的元素作为左子树划分出去,大于中位数的元素作为右子树划分。
- 分割值此时上升到父结点中,如果没有父结点,那么就创建一个新的(这里的上升不太好理解,一会我们推过去就明白了)
所以,当3来了之后,直接进行分裂操作:

就像爱情一样,两个人的世界容不下第三者,如果来了第三者,那么最后的结果大概率就是各自分道扬镳。接着我们继续插入4、5看看会发生什么,注意插入还是按照小的走左边,大的走右边的原则,跟我们之前的二叉查找树是一样的:

此时4、5来到了右边,现在右边这个结点又被撑爆了,所以说需要按照上面的规则,继续进行分割:

可能各位看着有点奇怪,为啥变成这样了,首先3、4、5三个都分开了,然后4作为分割值,3、5变成两个独立的树,此时4需要上升到父结点,所以直接跑到上面去了,然后3和5出现在4的左右两边。注意这里不是向下划分,反而有点向上划分的意思。为什么不向下划分呢?因为要满足B树第四条规则:所有叶子结点都出现在同一层。
此时我们继续插入6、7,看看会发生什么情况:

此时右下角结点又被挤爆了,右下角真是多灾多难啊,那么依然按照我们之前的操作进行分裂:

我们发现当新的分割值上升之后最上面的结点又被挤爆了,此时我们需要继续分裂:
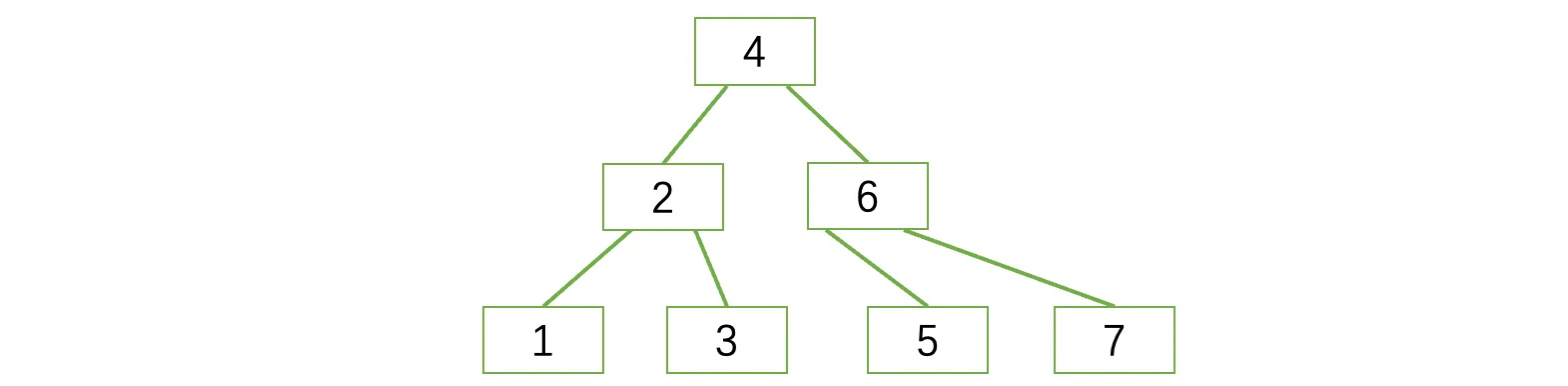
在2、4、6中寻找一个新的分割值,分裂后将其上升到新的父结点中,就像上图那样了。在了解了B树的插入操作之后,是不是有一点感受到这种结构带来的便捷了?
我们再来看看B树的删除操作,这个要稍微麻烦一些,这里我们以一颗5阶B树为例,现在我们想删除16结点:
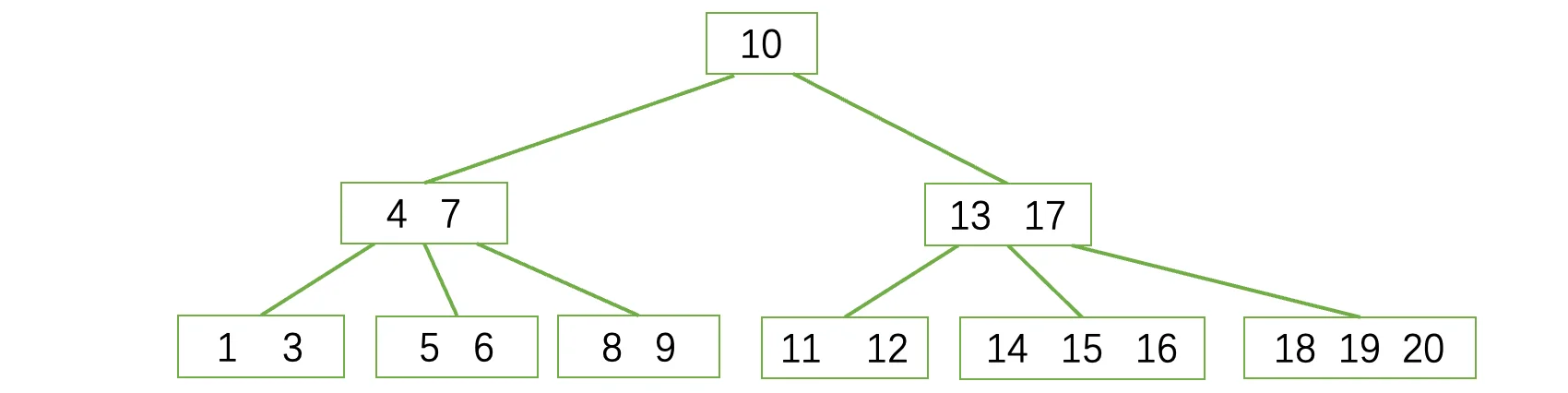
删除后,依然满足B树的性质,所以说什么都不管用:
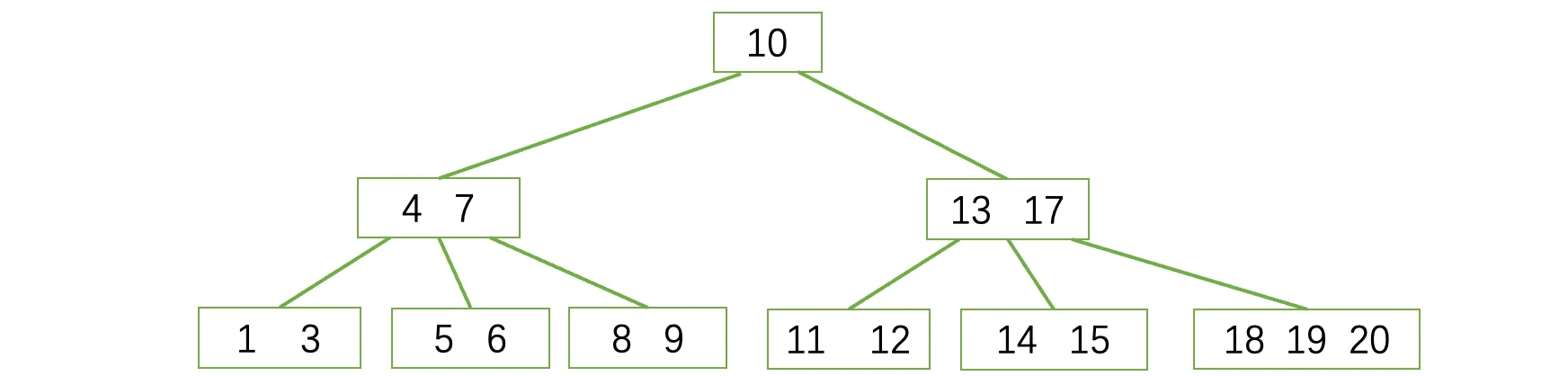
此时我们接着去删除15结点:
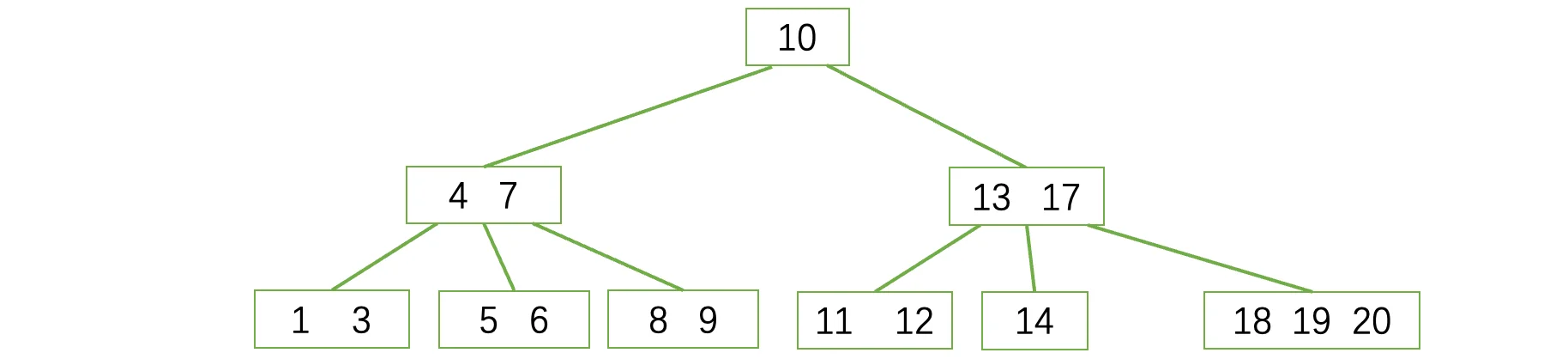
删除后,现在结点中只有14了,不满足B树的性质:除根结点和叶子结点外,其它每个结点至少有⌈m/2⌉个孩子,同理键值数量至少有⌈m/2⌉-1个,现在只有一个肯定是不行的。此时我们需向兄弟(注意只能找左右两边的兄弟)借一个过来:
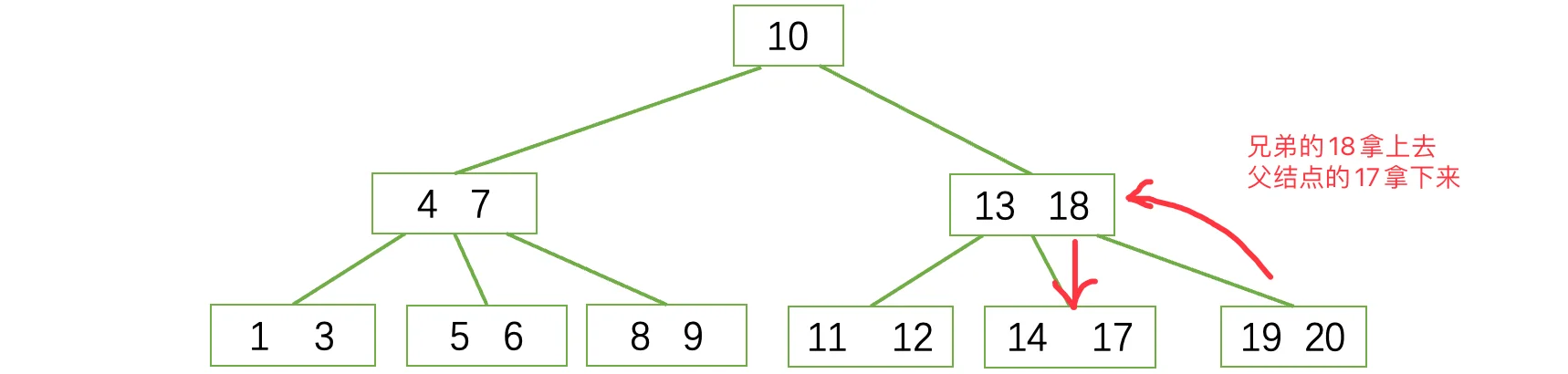
此时我们继续删掉17,但是兄弟已经没办法再借给我们一个元素了,此时只能采取方案二,合并兄弟节点与分割键。这里我们就合并左边的这个兄弟吧:
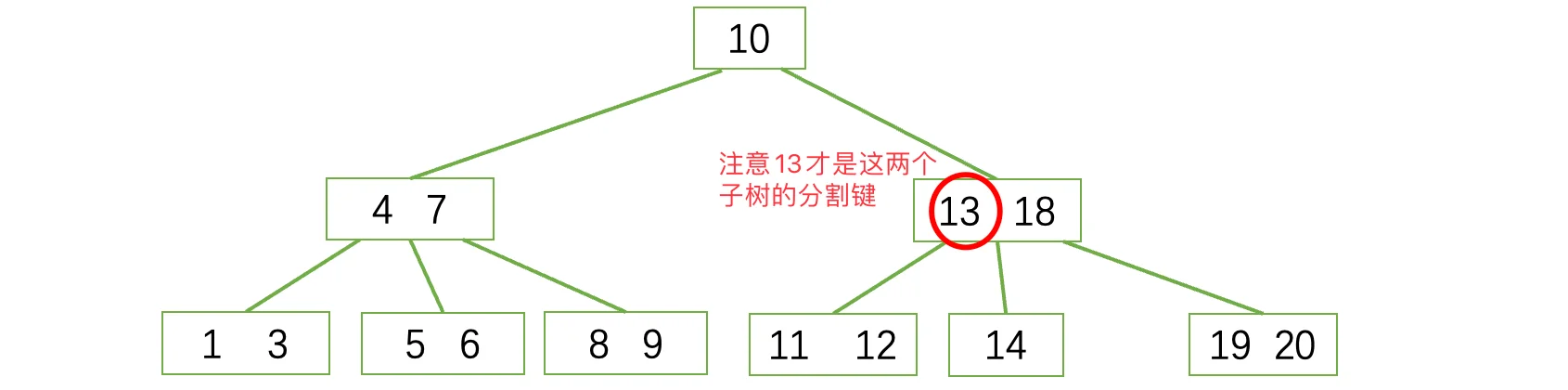
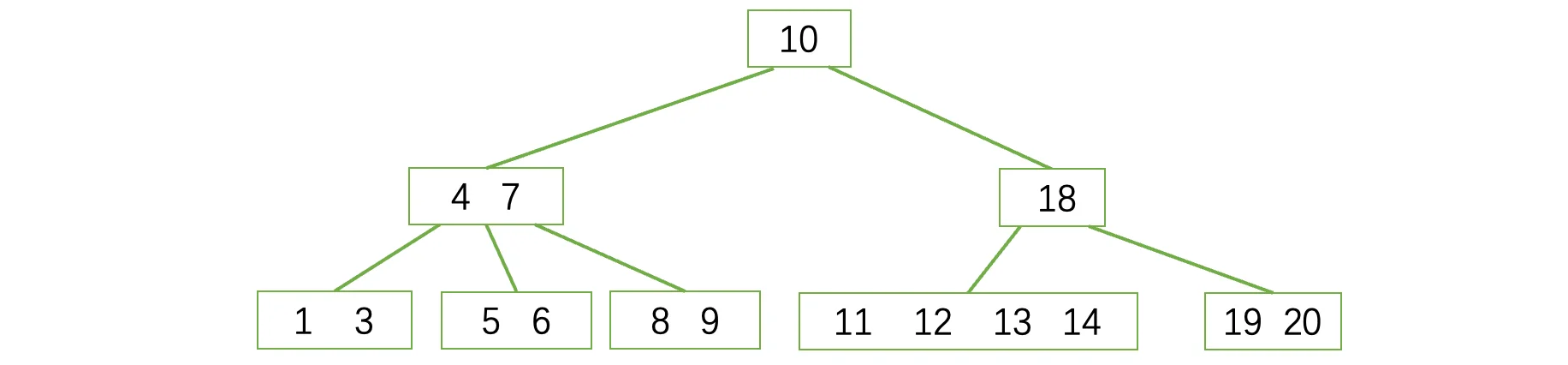
现在他们三个又合并回去了,这下总满足了吧?但是我们发现,父结点此时只有一个元素了,又出问题了。同样的,还是先去找兄弟结点借一个,但是兄弟结点也借不了了,此时继续采取我们的方案二,合并:

OK,这样才算是满足了B树的性质,现在我们继续删除4结点:

这种情况会导致失去分割值,那么我们得找一个新的分割值才行,这里取左边最大的:

不过此时虽然解决了分割值的问题,但是新的问题来了,左边结点不满足性质了,元素数量低于限制,于是需要找兄弟结点借,但是没得借了,兄弟也没有多的可以借了所以被迫合并了:

可以看到整个变换过程中,这颗B树所有子树的高度是一直维持在一个稳定状态的,查找效率能够持续保持。
删除操作可以总结为两大类:
- 若删除的是叶子结点的中元素:
- 正常情况下直接删除。
- 如果删除后,键值数小于最小值,那么需要找兄弟借一个。
- 要是没得借了,直接跟兄弟结点、对应的分割值合并。
- 若删除的是某个根结点中的元素:
- 一般情况会删掉一个分割值,删掉后需要重新从左右子树中找一个新分割值的拿上来。
- 要是拿上来之后左右子树中出现键值数小于最小值的情况,那么就只能合并了。
- 上述两个操作执行完后,还要继续往上看上面的结点是否依然满足性质,否则继续处理,直到稳定。
在了解了B树的相关操作之后,是不是感觉还是挺简单的,依然是动态维护树的平衡。正是得益于B树这种结点少,高度平衡且有序的性质,而硬盘IO速冻远低于内存,我们希望能够花费尽可能少的时间找到我们想要的数据,减少IO次数,B树就非常适合在硬盘上的保存数据,它的查找效率是非常高的。
注意:以下内容为选学部分:
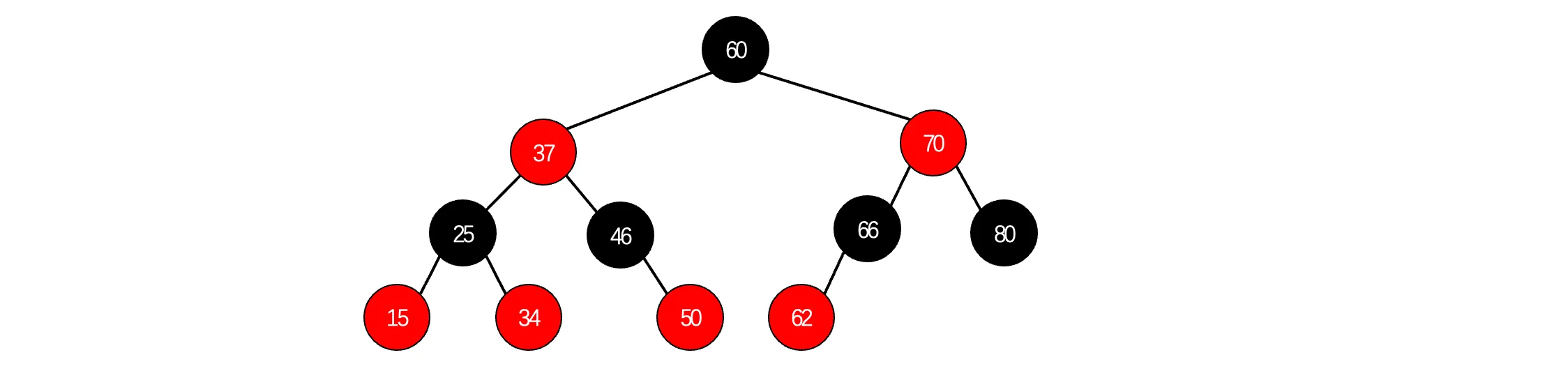
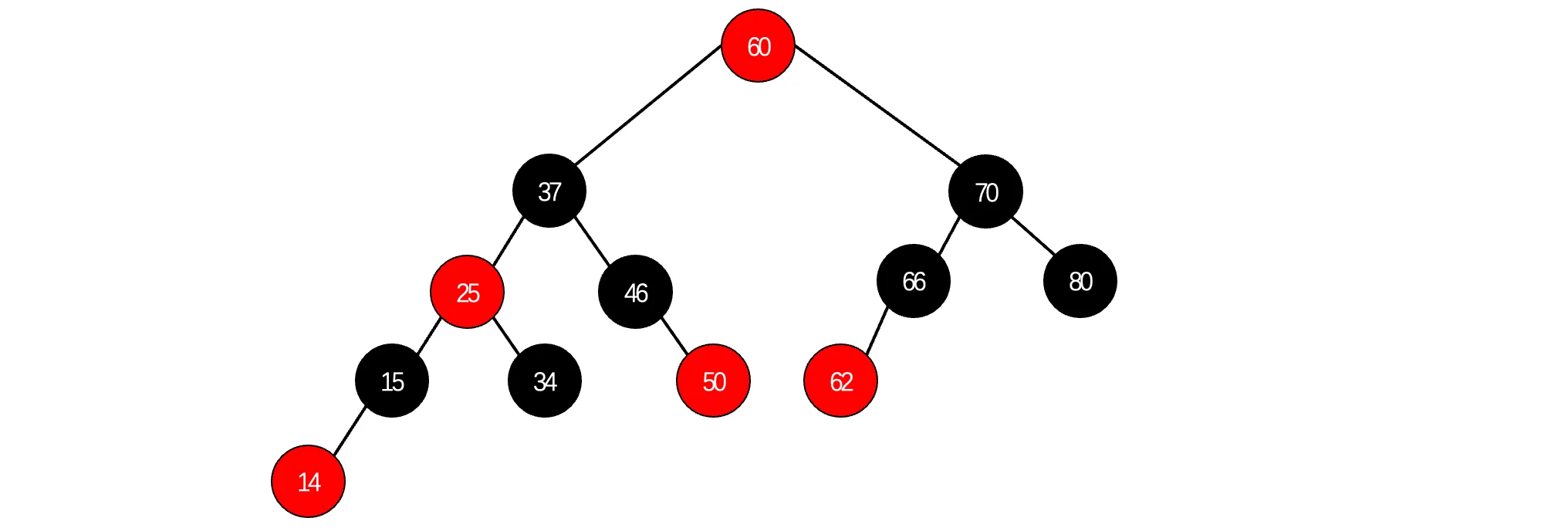
此时此刻,我们回想一下之前提到的红黑树,我们来看看它和B树有什么渊源,这是一棵很普通的红黑树:
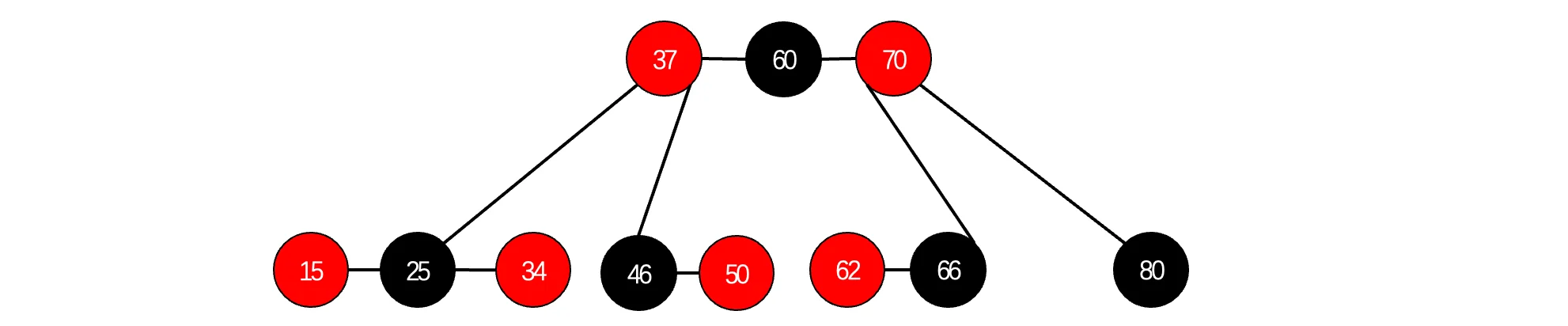
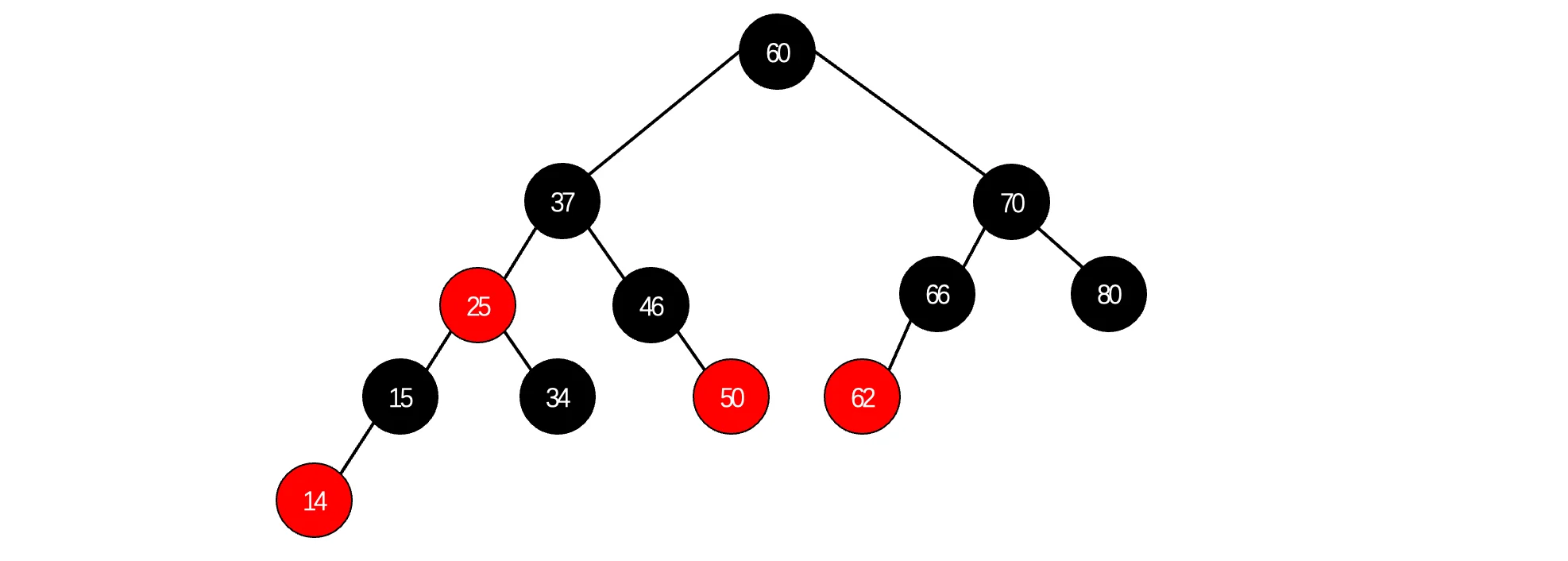
此时我们将所有红色节点上移到与父结点同一高度,
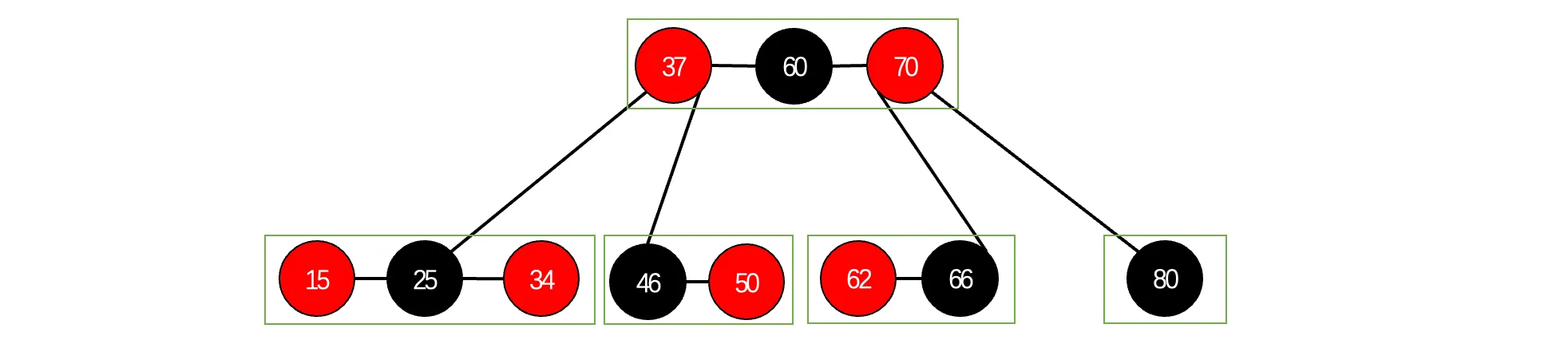
还是没看出来?没关系,我们来挨个画个框:
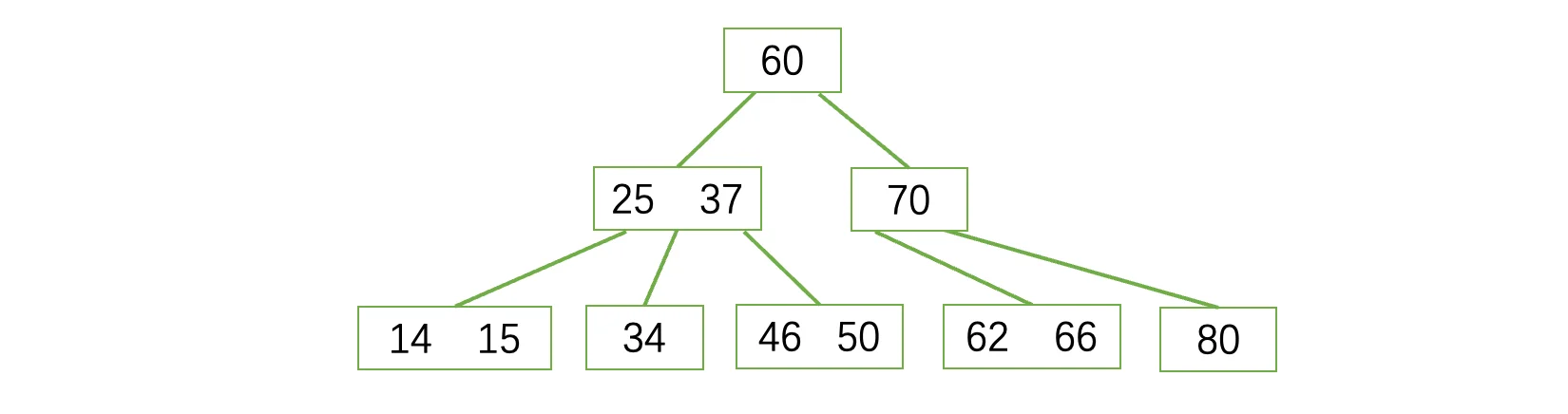
woc,这不就是B树吗?没错,红黑树 和 4阶B树(2-3-4树)具有等价性,其中黑色结点就是中间的(黑色结点一定是父结点),红色结点分别位于两边,通过将黑色结点与它的红色子节点融合在一起,形成1个B树节点,最后就像这样:
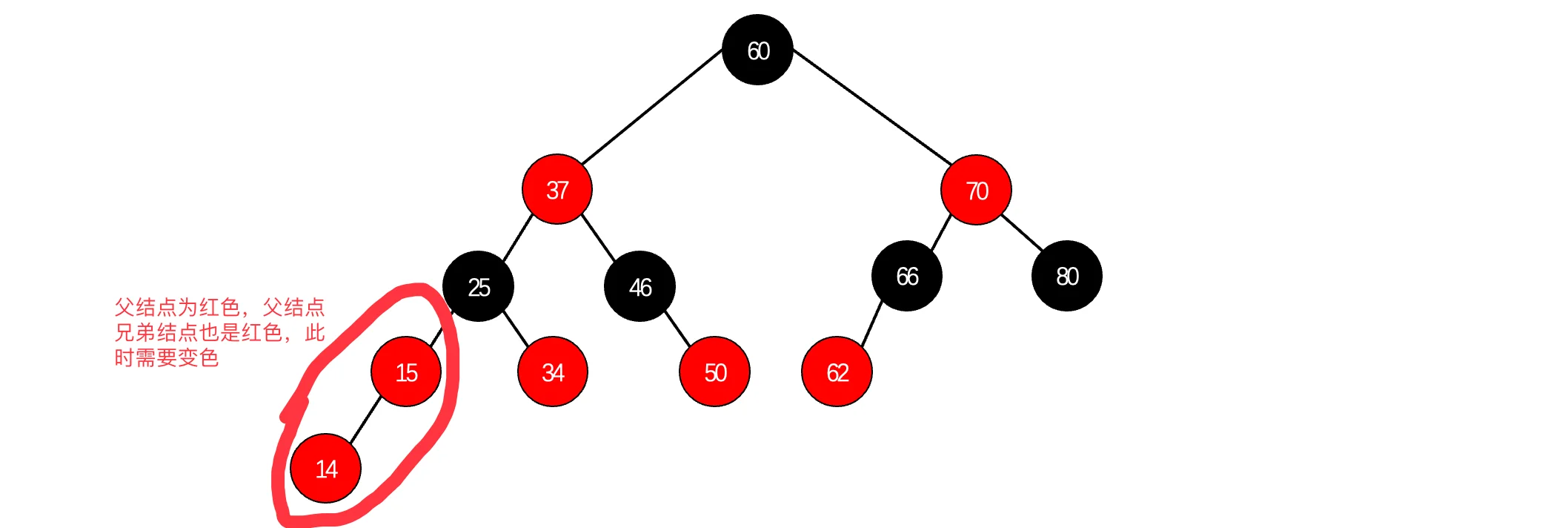
你会发现,红黑树的黑色节点个数总是与4阶B树的节点数相等。我们可以对比一下之前的红黑树插入和4阶B树的插入,比如现在我们想要插入一个新的14结点进来:
经过变色,最后得到如下的红黑树,此时又出现两个红色结点连续,因为父结点的兄弟结点依然是红色,继续变色:
最后因为根结点必须是黑色,所以说将60变为黑色,这样就插入成功了:
我们再来看看与其等价的B树插入14后会怎么样:
由于B树的左边被挤爆了,所以说需要分裂,因为是偶数个,需要选择中间偏右的那个数作为分割值,也就是25:
分裂后,分割值上升,又把父结点给挤爆了,所以说需要继续分裂:
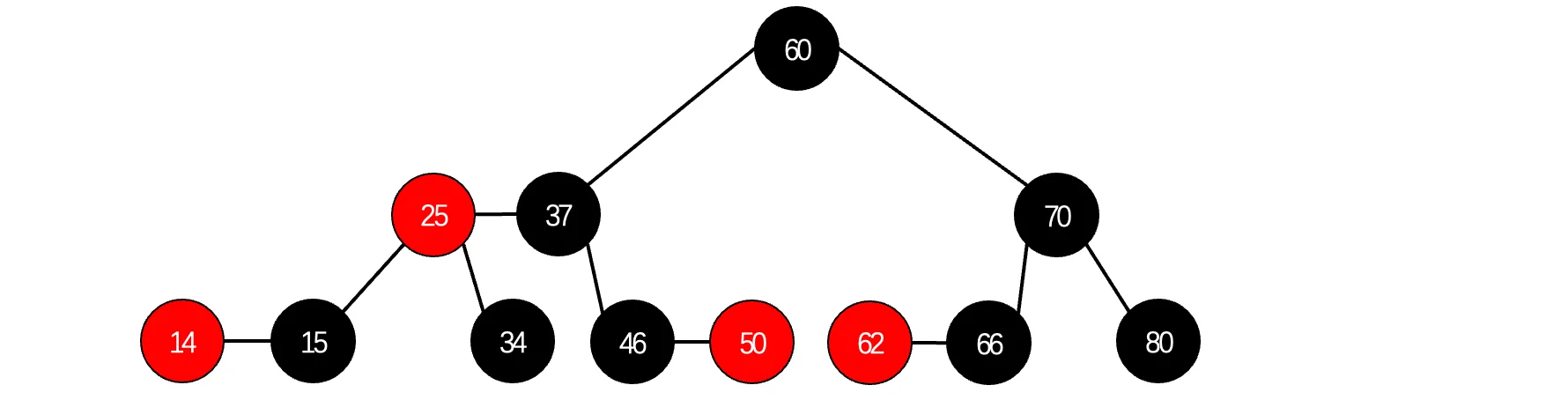
现在就变成了这样,我们来对比一下红黑树:
不能说很像,只能说是一模一样啊。为什么呢?明明这两种树是不同的规则啊,为什么会出现等价的情况呢?
- B树叶节点等深实际上体现在红黑树中为任一叶节点到达根节点的路径中,黑色路径所占的长度是相等的,因为黑色结点就是B树的结点分割值。
- B树节点的键值数量不能超过N实际上体现在红黑树约定相邻红色结点接最多2条,也就是说不可能出现B树中元素超过3的情况,因为是4阶B树。
所以说红黑树跟4阶B树是有一定渊源的,甚至可以说它就是4阶B树的变体。



前面我们介绍了B树,现在我们就可以利用B树来高效存储数据了,当然我们还可以让它的查找效率更高。这里我们就要提到B+树了,B+树是B树的一种变体,有着比B树更高的查询性能。
- 有k个子树的中间结点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据(卫星数据,就是具体需要保存的内容)都保存在叶子结点。
- 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点按照从小到大的顺序连接。
- 所有的根结点元素都同时存在于子结点中,在子节点元素中是最大(或最小)元素。
我们来看看一棵B+树长啥样:
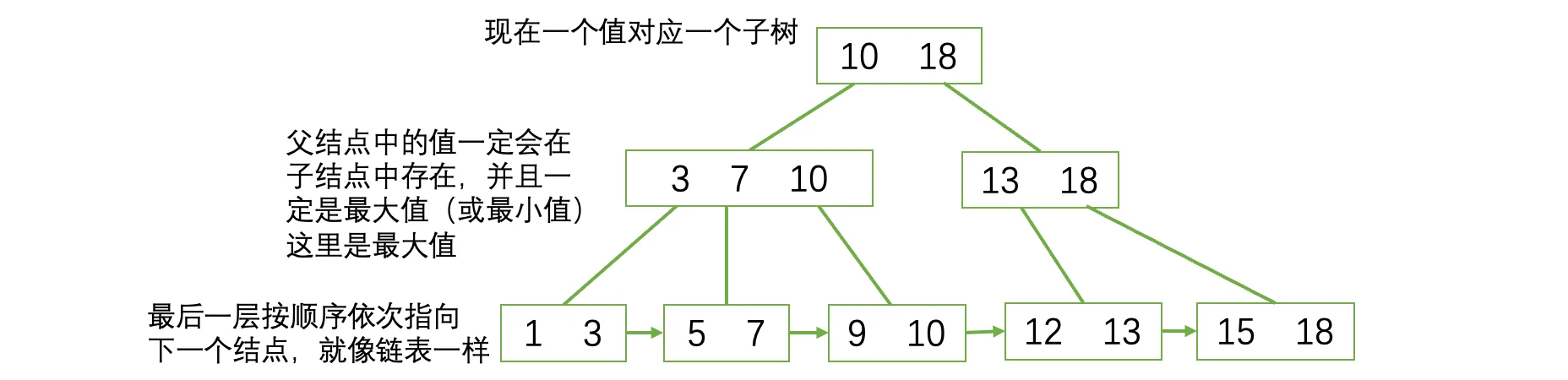
其中最后一层形成了一个有序链表,在我们需要顺序查找时,提供了极大的帮助。可以看到现在除了最后一层之外,其他结点中存放的值仅仅充当了一个指路人的角色,来告诉你你需要的数据在哪一边,比如根节点有10和18,因为这里是取得最大值,那么整棵树最大的元素就是18了,我们现在需要寻找一个小于18大于10的数,就可以走右边去查找。而具体的数据会放到最下面的叶子结点中,比如数据库就是具体的某一行数据(卫星数据)存放在最下面:
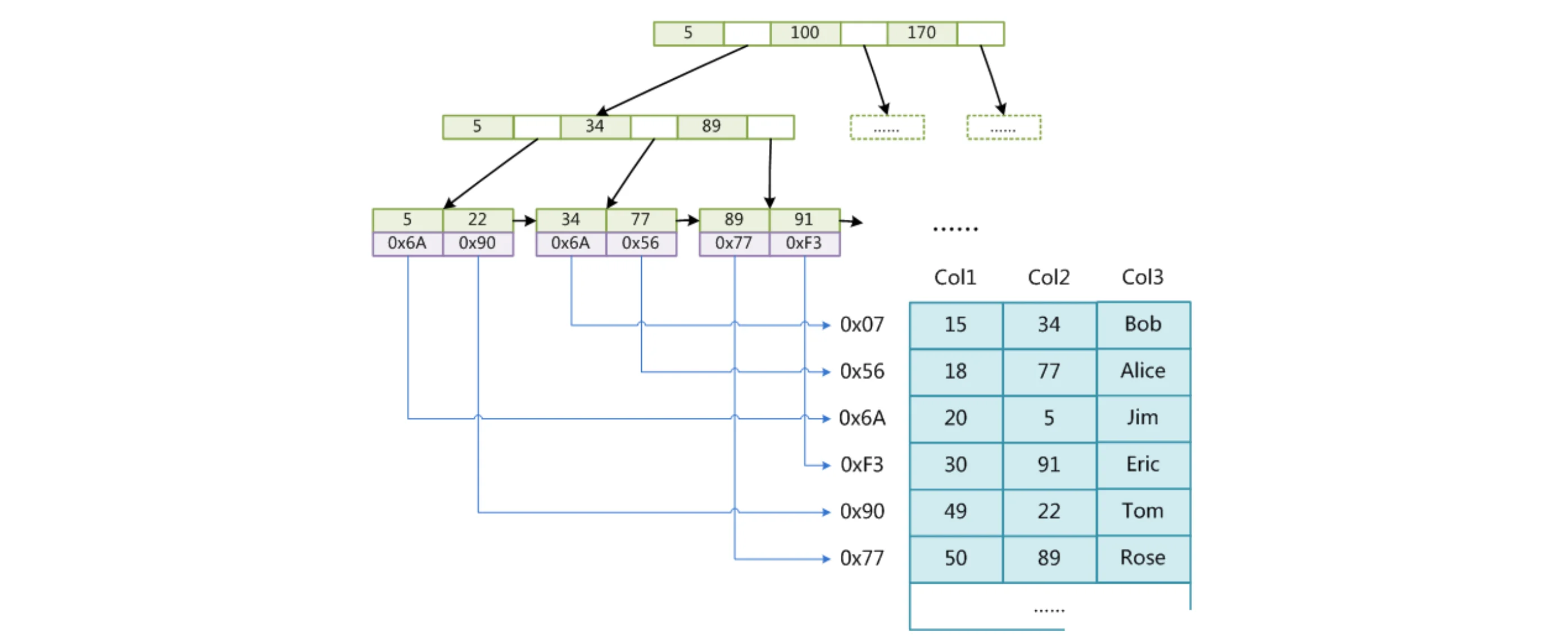
当然,目前可能你还没有接触过数据库,在以后的学习中,你一定会接触到它的,到时你就会发现新世界。
它不像B树那样,B树并不是只有最后一行会存储卫星数据,此时比较凌乱。因为只有最后一行存储卫星数据,使用B+树,同样大小的磁盘页可以容纳更多的节点元素,这就意味着,数据量相同的情况下B+树比B树高度更低,减小磁盘IO的次数。其次,B+树的查询必须最终查找到叶子节点,而B树做的是值匹配,到达结点之后并不一定能够匹配成功,所以B树的查找性能并不稳定,最好的情况是只查根节点即可,而最坏的情况则需要查到叶子节点,但是B+树每一次查找都是稳定的,因为一定在叶子结点。
并且得益于最后一行的链表结构,B+树在做范围查询时性能突出。很多数据库都在采用B+树作为底层数据结构,比如MySQL就默认选择B+Tree作为索引的存储数据结构。
至此,有关B树和B+树相关内容,就到这里。